AI深度学习入门与实战21 文本分类:用 Bert 做出一个优秀的文本分类模型
在上一讲,我们一同了解了文本分类(NLP)问题中的词向量表示,以及简单的基于 CNN 的文本分类算法 TextCNN。结合之前咱们学习的 TensorFlow 或者其他框架,相信你已经可以构建出一个属于自己的文本分类器了。
这一讲,是咱们《深度学习入门与实战》的最后一讲,我将会从一个实际的具体案例来带你从 0 构建一个效果很不错的文本分类流程。
问题背景
我们现在有一批 App 评论数据,来自多个国家和地区的应用商店。这些评论,按照其内容的表述不同,分为了若干小类,包括但不限于:
-
App rating>Satisfied,表示有关应用评价、评论、打分相关的满意类文本;
-
App rating>Dissatisfied,表示有关应用评价、评论、打分相关的不满意类文本;
-
Running app>App crash/launch error,表示有关应用崩溃、闪退的评论;
-
Running app>App installation/update,表示有关应用安装、更新的评论;
-
Chats,表示有关聊天的评论;
-
Account,表示有关账号的评论;
-
Notification,表示有关消息提醒评论;
问题分析
从问题描述以及数据本身来看,我们需要注意两个方面。
-
多语言。对一般人来说,通常掌握的外语都是英语,顶多再加个日语或者韩语。如果面对其他语言,甚至是小语种,可能就看不懂了,所以我们需要一个适应多语言的(预训练)模型。
-
数据比例,也就是之前章节中咱们提到的数据平衡问题。在实际的数据中,受功能影响大小、国家用户人数不同、应用问题集中位置不同等问题,会导致不同类别的数据的数量比例会不一样。
上一讲我们了解了 TextCNN,通过它的原理,我们可以得到一个大概的思路:将文本表示成向量的方式,然后接上一些卷积层或者全联接层,最后给出一个多分类的结果。这也就是文本表示、网络构建、分类三个环节。
我们先来看第一个环节,文本表示。
BERT
BERT 的全称是 Bidirectional Encoder Representation from Transformers,即双向 Transformer 的 Encoder。某种程度上可以认为它是 word2vec 的替代者。
BERT 在 2018 年被提出,当年就刷新了 NLP 领域 11 个问题的记录,令人瞠目。有关 BERT 的介绍,你可以阅读这个链接提供的论文。下图是我根据代码绘制的代码流程图。
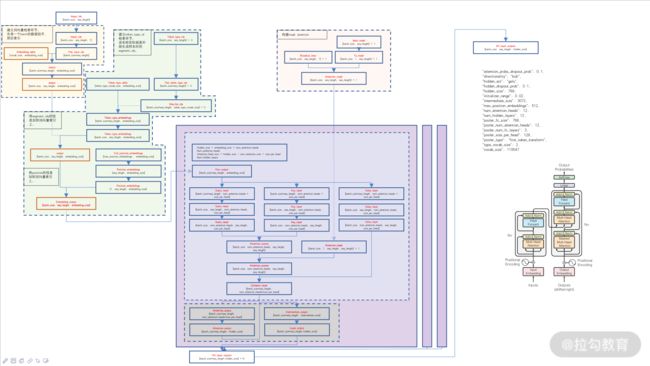
图 1:代码流程图
我们来看一个这个刷新了 11 个问题的记录的 BERT,它有哪些创新点和优势。
-
用了 Transformers 作为算法的主要框架。Transformers 能够更好地捕捉句子中的双向关系,或者说上下文关系(你可以点击链接查看它的论文)。不过其本质就是上一讲中介绍的 Attention,注意力机制。当你熟悉了这个机制,读论文就会变得非常容易。
-
使用了 Mask Language Model(MLM)训练模型。所谓 MLM,就是随机屏蔽一部分比例的词语,在训练的时候预测这些被 mask 的 token。这样做的好处是学习到的表征能够融合两个方向上的 context。这么一说,是不是觉得有点儿像咱们之前说的 Skip-Gram?它们确实有一定的相似之处。
-
增加了句子级别的预测,即next sentence prediction,不过这部分咱们暂时用不到。
-
灵活。之前介绍 word2vec 的时候我提到过,给定一个确定的单词,它对应的词向量是固定且唯一的。但在 BERT 中则有所不同,根据上下文的不同,它给出的词向量的值也稍有不同。这个很好理解:因为输入不同,所以对应的被激活的单元也就不同,最终的输出向量自然就有所不同。这一点,结合后面我给出的代码图你会更容易理解。
-
提供了多语言的预训练模型。对于个人开发者或者爱好者来说,很多时候我们手里并没有足够的语料去训练模型;同时考虑到训练成本(电费等),预训练模型的优势就更加明显了。很多机构都提供了开源的 BERT 预训练模型,并给出了可以直接使用的解决方案。
安装
说了一大通,接下来我们就来安装 Bert 吧!
作为开源算法,很多机构和个人都提供了相关的代码下载,这里我们选择 GitHub 上的 PyTorch 版本。你可以点击链接查看,然后使用下面的语句安装。
pip install transformers
Transformers 提供了非常多的算法解决方案,BERT 只是其中的一个。打开上面的链接后,我们打开这个文件位置:src/transformers/models/bert,可以看到很多个 py 文件,其中有两个最为重要,它们分别是 convert_bert_original_tf2_checkpoint_to_pytorch.py 和 modeling_bert.py。
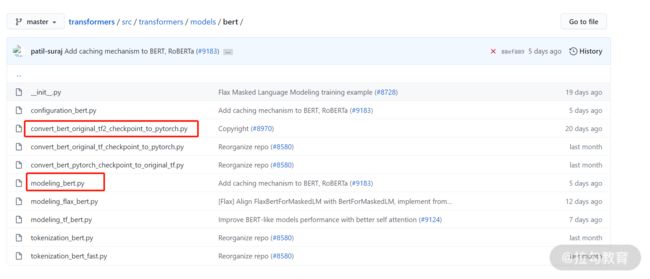
图 2:GitHub 上的 Transformers 页面
-
convert_bert_original_tf2_checkpoint_to_pytorch.py:从名字我们就能看到,这个文件的作用是将 tensorflow2 训练的 BERT 模型转换为 PyTorch 框架下的模型。
在使用 GitHub 的时候,代码文件的注释非常重要,特别是头部信息,往往包含了很多的重要内容,比如使用方法、资源下载位置、使用注意事项。
在本例中,tf2 预训练的模型下载位置就在:https://github.com/tensorflow/models/tree/master/official/nlp/bert。点开后,我们选择《BERT-Base, Multilingual Cased》版本的模型,下载并执行 convert_bert_original_tf2_checkpoint_to_pytorch.py 即可。
图 3:代码的头部信息
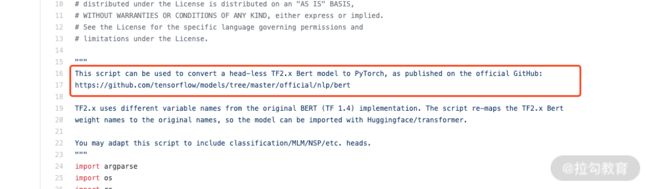
-
modeling_bert.py:点开文件之后我们可以看到,里面提供了很多功能已经封装好的使用方法,其中有一个 BertForSequenceClassification 的类,我们可以直接用作分类模型。但作为一个热爱科学的社会主义新青年,我们自然要自己动手写一个去搞懂其中的原理。稍后我们就去看看这个模型应该怎么写。
到这里,如果你生成得到了一个 PyTorch 框架下的模型,此时你的预训练模型文件夹中将会有三个文件。
-
config.json:BERT 模型的配置文件,里面记录了 BERT 所有的外部参数。
-
pytorch_model.bin: BERT 模型文件,按照不同的转换设置,你可以给它起不同的名字。
-
vocab.txt:BERT 模型的词表文件。之前我提到过,NLP 任务中,分词特别重要。BERT 也不例外,该文件可以指导模型对输入数据进行文字切分,切分方法基于 WordPiece,你可以通过链接查看 WordPiece 的相关介绍。
我总结了一下这个论文中的内容:以英语文本为例,love 这个单词有 love、loves、loved、loving 等不同的形态,WordPiece 会将不同的形态切分成 love、s、ed、ing……对应不同的形态,这样就可以分别提取词语的词干和不同形态,从而增强了模型的适应能力和理解能力。
输入要求
Bert 的模型使用非常简单,我们只需要按照要求将文本转换成合适的结构输入到 BERT 中就可以得到对应的向量信息。
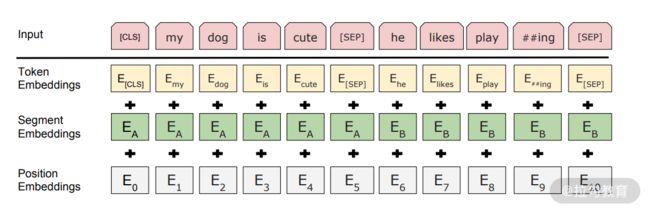
图 4:BERT 的输入
我们来看图 3 中的具体含义。
-
Token embeddings 代表词向量,每句话的第一个 token 总是[CLS]。对应它的最终的 hidden state(Transformer 的输出)用来表征整个句子,可以用于下游的分类任务。此外,用一个特殊 token [SEP]隔开两个句子以作区别。
-
Segment embeddings 用来区分两个句子,此处我们暂时只需要一个句子。
-
Position embeddings 可以将单词的位置信息编码成特征向量。
更为具体的 BERT 的 API,可以查看链接中的内容。
网络设计
最开始,我们先尝试最简单的网络模型,也就是 BertForSequenceClassification 提供的方案。毕竟得先把模型跑起来,然后再考虑优化。
class BertForSequenceClassification(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.bert = BertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
self.init_weights()
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
上面的代码块是精简之后的分类网络,我们可以看到,首先将 attention_mask、token_type_ids、position_ids 输入到 BERT 中,得到 output 输出。
output 的形式为一个 BaseModelOutputWithPoolingAndCrossAttentions 的类,它的内涵很丰富,包括 last_hidden_state、pooler_output 以及 hidden_states、attentions、cross attentions。
一般来说我们用得较多的是第一个返回值,也就是 last_hidden_state,这也就是为啥我们会有 pooled_output = outputs[1]。
-
last_hidden_state:模型最后一层输出的隐藏层状态序列。shape 是(batch_size, sequence_length, hidden_size),其中 hidden_size=768。
-
pooler_output:序列的第一个 token 的最后一个隐藏层的状态。shape 是(batch_size, hidden_size)。回忆一下,序列的第一个 token 是什么呢?
后面的就很简单了,接一个 dropout,再接一个全连接分类就 OK 了。
网络配置
设计好了网络之后,我们还需要对网络参数进行配置,也就是刚才说的 config.json 文件。在这个文件中你可以看到很多可配置的参数,文件最开头的几个配置项目基本不用改动,但要想完全弄懂它,我还是建议你看一下,了解其中的含义。
我们需要文件的几处进行修改。
-
id2label:类别标签和类别名称的映射关系。
-
label2id:类别名称和类别标签的映射关系。
-
num_labels_cate:类别的数量。
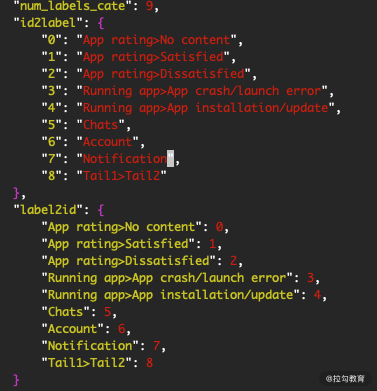
图 5:config.json 文件
在开发时,有一个小习惯可以让你做到对数值的全局管理和把控:尽可能不要在代码中硬编码写入一些数值,而是把这些数值通过配置文件的方式进行添加。假如你有个数值是表示文本最大长度的,你肯定会在代码中反复使用到这个值;如果每一次都写具体的数字,一旦在以后的开发过程中需要更改,你就得去一个个修改。麻烦不说,难免会存在遗漏或者写错的情况。统一管理之后,这种问题就基本不会出现了。
数据组织
从 model.py 文件中,我们知道需要为模型喂入的数据就是 forward 函数中的参数,结合 BERT 的 API 文档,我们又知道其实模型必须传入的数据包括:input_ids、token_type_ids、attention_mask 三个,这也对应了刚才提到的 BERT 的三个向量。
那怎么将文本转为这三种向量呢?
我们打开 util/DataSet.py 文件,这个文件提供了一整套的数据预处理流程。
在原始数据和模型使用的数据之间,需要一个 InputExample 类作为中间形式。
我们来看一下 InputExample 的定义:
class InputExample:
def __init__(self,
text_a=None,
text_b=None,
label_cls=None):
self.text_a = text_a
self.text_b = text_b
self.label_cls = label_cls
# 其实你看到的代码比这个复杂,是因为我们后需要增加更多的信息,使模型更好。
通过 InputExample,我们就将文本数据,转为了利用类进行记录的方式。然后,我们再结合 VocProcessor 类,特别是其中的_get_examples 和_get_dataloader 函数,将数据组织成可供 PyTorch 训练时使用的 batch 形式。
其实,在对数据进行组织,也就是转换为 InputExample 之前,还有一个很关键很重要的过程:数据平衡和预处理。不过我在《12 | 数据预处理:让模型学得更好》中已经介绍过了,所以这里就不赘述了。
有了数据,有了模型,那么我们就要将数据和模型连接起来,也就是构建训练的流程。这部分的代码,在 util/ModelTrainer.py 中。
优化
util/ModelTrainer.py 中的代码要比刚才说的复杂得多,这主要是因为其中有几个需要优化的地方,我们来看看当前这种简单粗暴方式下的模型存在的效果上的问题。
如果我们单独使用 BERT 来做的话,整体效果确实不错,但是将数据评估具体来看就会暴露出一些短板。
-
超短文本(长度小于 10)、短文本(长度介于 10~20)、长文本(长度介于 100~150)和超长文本(大于 150)之间,不同长度的 BERT 的表现是不一样:短文本和超短文本的准确率比其他长度的要明显低一些。
-
不同语言上,BERT 的效果也不一样。英语日语的相对好一些,但是其他语言的相对差一些。这是因为 BERT 在预训练时,语料的数量、语言本身的语法结构、数据质量等因素造成了天然上的差异。
-
数据不平衡。深度学习需要大量的语料来让模型学习,但有的类别的文本本身就很少,即便是通过过采样等方式,效果仍不理想。
那这些短板该如何解决呢?我们来逐个看。
多模型
在很多情况下,数据本身是复杂、不平衡、有噪声的,没有哪个单一的模型有能力 hold 住全场。不过俗话说得好,三个臭皮匠顶个诸葛亮,模型也是。所以在本项目中,我们采用了深度学习与传统机器学习相结合的方式,让它们来把问题各个击破。
首先,我们引入了 FastText。
FastText 是 Facebook 开源的一款集 word2vec、文本分类等于一体的机器学习训练工具。它的优秀之处在于,可以用较少的数据实现一个相对不错的效果。
FastText 的数据组织与模型训练,我已经放到了 tools/fasttext 文件夹中,并将 FastText 模型替换了 BERT 在超短文本的工作,也就是说,超短文本我们使用 FastText,其余的仍旧采用 BERT。
此外,通过数据统计,我们发现,不同的类别数量比例相差悬殊,有的文本超过八万,有的数据只有寥寥的两三千条。即便是把数据平衡的所有方法都用上了,对于这种极度不平衡的情况也无济于事。
因此,我们可以采用两步走的方式:先将所有长尾类别(也就是数量少的类)合并成一个新的大类,这个新的大类在数量上和其他大类差不多然后我们再通过合并后的数据训练模型。
数据被分类到长尾大类以后,我们可以再使用 SVM 对其进行类别还原。
SVM 的训练过程,我放在了 tools/svm 中,你可以直接使用。
你看,现在的训练流程就变成了:FastText 和 BERT 分别学习大类别的超短文本和非超短文本,SVM 学习长尾类别,真的是“三个臭皮匠顶个诸葛亮”。这三个模型在各自擅长的数据上发挥了最大的作用。
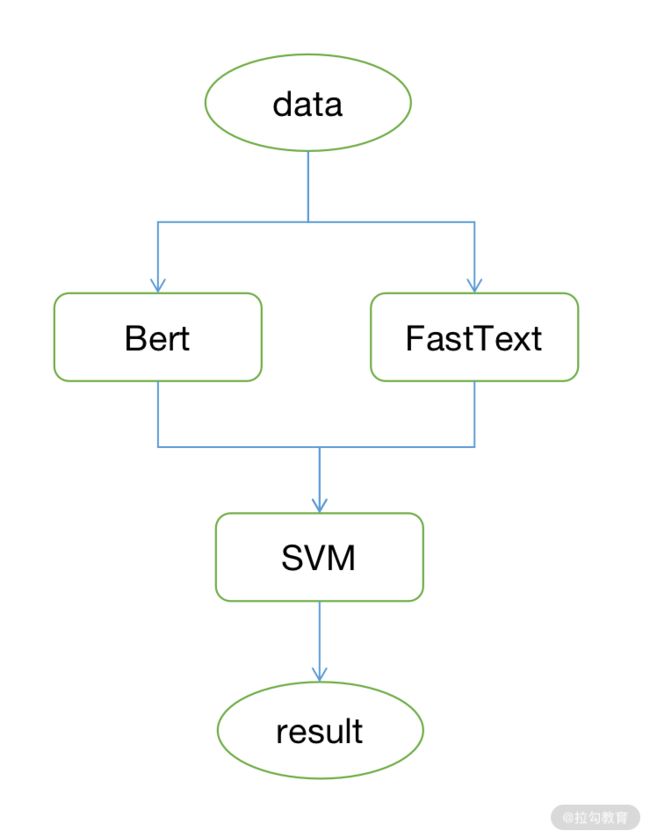
图 6: “三个臭皮匠”
你可能会觉得太复杂了,用一个模型来做,不是又方便又美观吗?其实不然, 在实际的项目开发中,这已经算是很简单的了,还有很多策略方面的工作没有加入。我们在工作的时候经常会调侃:“人工智能,人工智能,先人工,后智能”,这句话不是没有道理的。
那 BERT 这么优秀,为什么我们还要用古老的 SVM 呢?在我看来,这个世界上没有最好的模型,只有最合适的模型。面对不同的场景会有不同的状况,这就要求我们要对算法有全面的了解,不是认为最新的就是最好的,那只会使自己陷入“只看得上最新模型”的怪圈。
多语言
刚才我提到,受语言不同、数据量不同等原因,BERT 在不同语言的效果也不同。在本项目中,我们增加了一个环节,也就是将非英语文本通过谷歌翻译 API 转化为英语文本,连同原始语言文本,一同传入 BERT ,然后学习。这也是为什么你在 util/Model.py 中的 forward 函数看到的是这样的代码:
tensor_cat = []
for i in range(2):
outputs = self.bert(
input_ids[:, i*self.voc_max_seq_length:(i+1)*self.voc_max_seq_length],
attention_mask=attention_mask[:, i*self.voc_max_seq_length:(i+1)*self.voc_max_seq_length],
token_type_ids=token_type_ids[:, i*self.voc_max_seq_length:(i+1)*self.voc_max_seq_length],
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
tensor_cat.append(pooled_output)
我们向 BERT 传入两次数据,得到了两个长度为 768 的 output 向量,并以此来表示文本的向量。
不过这里会涉及另一个问题,那就是模型最终学习的效果依赖翻译 API 的效果,如果翻译得不好,对模型最终输出的效果也是一个不好的影响。
既然这样,那为什么要增加一个翻译环节在模型中呢?其实在实际开发中,很多的做法都是研发人员一点点尝试出来的,任何一点微小的提升背后都是辛苦的劳动换来的,为了达成提升目标,就不得不尝试各种办法,这就是理论研究和实际研发的区别。
词形还原
BERT 因为采用了 WordPiece 的分词方式,所以对于单词的不同形态有着很好的适应。但是对于 FaxtText 和 SVM 来说,就需要人工来还原英语单词的时态。
这是为什么呢?
SVM 构建训练数据的时候,我们首先要提取特征词,比如 chi 提取(具体代码在tools/svm/chi_extractor_new.py 中)。提取出来的词语实际上是没有还原时态的。如果特征词里面有 love,但是训练和测试语料中有很多 loving,这一部分的词语就无法被提取出来,会有一定概率影响到学习的效果。
这里我们使用开源的 NLP 工具 NLTK,构建了属于我们自己的词形还原类,我放在了 util/Lemmatizer.py 中,你可以前往 GitHub 查看。
其他
除了以上几处优化,我们还需要增加几个内容。
-
长度信息与损失函数:通过向模型传入文本的长度信息,并修改损失函数的参数,我们可以让模型更加侧重长文本的学习。
weight = 0.8 + len_info * 0.2 / 100
loss_fct = BCEWithLogitsLoss(weight = weight)
-
显式地将类别关键词和业务特征关键词构建成 one-hot 形式,并作为一路特征传入分类网络中,也就是代码中的 cate_word_weights 和 word_features。
bert_word_feat = torch.cat(tensor_cat + [word_features] + [cate_word_weights], 1)
不要忘了将 word_features 的长度添加到 config.json,即配置文件中的 word_feat_size。
至此,我们手头的特征信息就丰富多了,包括词特征、BERT 特征(两种语言)、类别词特征、长度特征,将它们结合到一起,再接上两个全联接层,效果就比单一地使用 BERT 要好多了。
总结
由此,我们构建了一个相对复杂的文本分类流程,包括了以下几个部分。
-
基于 BERT 的词向量环节。通过该环节,我们能够获取非常好的向量表示来表征文本内容。
-
多语言。考虑到数据本身的特点,我们使用原文和翻译成英语后的两种文本让模型同时学习。
-
多模型。这个世界上没有最好的模型,只有最合适的模型。我们需要了解不同模型背后的原理和它们的特点,才能将其放在最合适的位置,获得更好的效果。
-
附加信息。通过词形还原、修改损失函数参数、增加特征词等方式,我们可以让模型直接学习这些特征。尽管模型本身有很好的学习能力,但是我们直接告诉模型该学习什么,往往也非常有效。
以上就是这一讲的全部内容了。你可能发现了,这一讲中并没有突出太多算法方面的东西,而是更多地向你介绍了从 0 开发一个相对复杂的分类流程的思考过程。单独阅读这一讲的内容可能会让你感觉比较不好理解,你可以结合我提供的代码来看。我在这一讲中所讲到的其实也可以算作是对这个代码项目的一个解释性的介绍。
如果你有什么问题,欢迎在留言区留言,也欢迎来微信群与我讨论。
恭喜你完成了《深度学习入门与实战》的学习。最后,我为你准备了一份结课问卷,希望你能评价本课程的内容。你的关注就是我们的专注。
精选评论
你好,我是槐树。
时间匆匆,不知不觉,你就学完了《深度学习入门与实战》的所有内容了。
从最开始的数学基础和深度学习基础概念学习,我们不断地为“深度学习”这座大厦夯实基础,打好地基。再到后来的工具与框架的学习,我们一同开始筹谋规划,为真正开始盖楼做准备。最后,随着基础概念和工具准备齐全,我们从三个实际项目出发,建好了真正属于我们自己的深度学习的大厦。
虽然这座大厦可能不那么高,但却有着牢固的基础、优秀的结构,就像在经历了学习之后,敲开深度学习的大门的你一样优秀。
我有幸来做这个课程,得益于年长几岁,工作较多几年,在最后,我也想分享一些我的经验和心得,无论是做深度学习,还是做其他的学问,希望你都能用得上。
-
随时保持饥饿。我不是指肚子饿的饥饿,这里指的是对知识的饥饿。
深度学习是一个即悠久又年轻的学科,说它悠久是因为它的很多理论已经有了几十年的历史,说它年轻是因为它是近几年才快速爆发的。
在未来,随着硬件、科技、伦理、法律、社会的不断进步,深度学习的落地场景也会越来越多。现在几乎每天都有新的算法、框架出现,迭代速度之快,令人咋舌。所以我希望你要时刻保持饥饿,紧跟领域内的最新进展,才能让自己更有竞争力。
-
耐住枯燥乏味。深度学习的应用都很酷炫,但是其背后的算法、技术、逻辑则大多枯燥无趣。如果你真的想做这一行,那么你就要努力地去爱上这一行,将枯燥化为乐趣。如果你面前出现公式,你的第一反应是眼晕和抗拒,那么你就要重新审视自己是否真的喜欢它了。
-
扩充知识储备。我们在学习网络、模型的时候,往往是针对某一个模型来学习的。这就很容易有一个怪圈:不管什么项目,我都要用最好最新的算法来做,它一定有最棒的效果。
其实,在课程中,我反复提到的一句话:世界上没有最好的模型,只有最合适的模型。一切的算法,一切的模型,最后都是要为解决问题服务的,问题是第一位,模型是第二位。你如果深入分析了问题的本质,就能够知道哪里才是解决问题的关键环节。这看似容易,其实很难拿。你需要尽可能地扩充你的知识储备,这样在面对不同的问题的时候才能游刃有余。
-
杜绝拿来主义。作为开发者,我们可以从各个渠道获取各种来源的开源工具,这也让我们避免了重复造轮子带来的痛苦,但这有利有弊。
有了开源项目的分享,你可以第一时间直面大咖的工作成果并享受其带来的红利。久而久之,却失去了独立思考的能力。在课程发布的时候,很多同学希望能够提供直接可以使用的代码,其实我内心是抗拒的。如果你了解了某个算法的原理,如果不是很复杂,你应该首先尝试去实现它,而不是去找现成的代码。
深度学习,在未来很长一段时间都将是影响人们生产生活的主题之一,它能带给你的机遇也将越来越多。我衷心希望你能够搭上 AI 发展的快车,在这个领域有自己的一席之地。
时间总是过得很快,在以后学习深度学习的日子里,你还会遇到各种各样的问题,希望你能够多学、多问、多想、多动手。你一定能够在深度学习的海洋里尽情遨游。
有一讲的结尾,我称自己为“鲁棒的槐树”,因为我希望我自己能和模型一样“鲁棒”,无论是我的身体,还是我的大脑。明天就是 2021 年了,新的一年,希望你也能“鲁棒”起来。
让我们一起收拾好行囊,迈向充满希望的 2021 吧!
爱你的槐树~
最后,我为你准备了一份结课问卷,希望你能评价本课程的内容。你的关注就是我们的专注。
精选评论
Ther:
学习知识要善于思考,思考,再思考。—爱因斯坦