第一章 机器学习 引言
一、机器学习定义
定义1:
机器学习是这样的领域,它赋予计算机学习的能力(这种学习的能力)不是通过显著式编程获得的。
Machine Learning is Fields of study that gives computers the ability to learn without being explicitly programmed.
非显著式编程:让计算机自己总结规律的编程方法。
定义2:
一个计算机程序被称为可以学习,是指它能够针对某个任务T和某个性能指标P,从经验E中学习。这种学习的特点是,它在T上的被P所衡量的性能,会随着经验E的增加而提高。
例:计算机识别花卉类别
任务T:编写计算机程序识别菊花和玫瑰
经验E:一大堆菊花和玫瑰的图片
性能指标P:不同机器学习算法会有不同,识别率(Recognition Rate)为例,识别的正确率。
机器学习是针对识别玫瑰和菊花这样的任务,构造某种算法。这种算法的特点是,当训练的菊花和玫瑰的图片越来越多的时候,即E越来越多,P识别率也会越来越高。
思考题:给出经验E与性能指标P
1、教计算机下棋
2、垃圾邮件识别,教计算机自动识别某个邮件是垃圾邮件
3、人脸识别,教计算机通过人脸的图像识别这个人是谁
4、无人驾驶,教计算机自动驾驶汽车从一个指定地点到另一个指定地点
二、机器学习分类
根据任务是否需要和环境交互获得经验,可以分为监督学习和强化学习,但是不绝对,二者有时存在交叉。
监督学习(Supervised Learning)
所有的经验E都是人工采集并输入进计算机的,我们把这一类输入计算机训练数据,同时加上标签的机器学习。
监督学习可以根据标签存在与否,分为以下几类
(1)传统的监督学习:每一个训练数据都有对应的标签

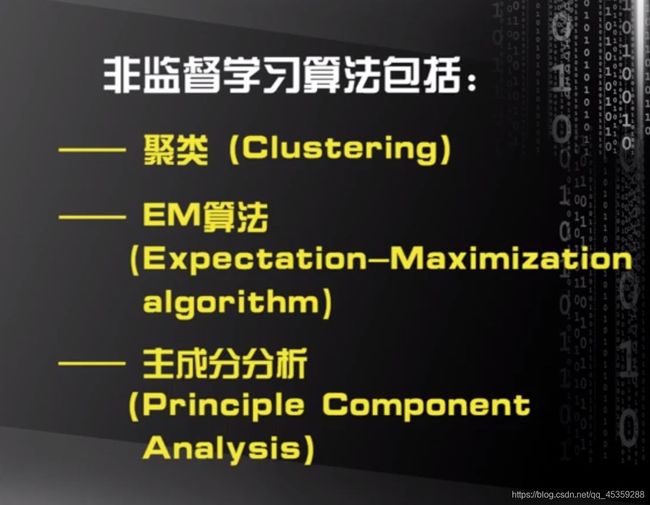
(2)非监督学习:所有的训练数据都没有对应的标签
(3)半监督学习:训练数据一部分有标签,一部分没有标签
监督学习可以根据标签的固有属性,分为
(1)分类:标签是离散的值
(2)回归:标签是连续的值
其实分类和回归的界限非常模糊,连续<–>离散

强化学习(Reinforcement Learning)
计算机通过与环境的互动,逐渐强化自己的行为模式。
三、机器学习算法过程
1:特征提取、特征选择
通过训练样本获得的,对机器学习任务有帮助的多维度数据。
机器学习不是研究提取特征,而是假设在以及提取好特征的前提下,如何构造算法获得更好的性能指标。但是特征提取非常重要,提取到了好的特征,也能获得不错的性能。
不同的算法对特征空间做不同的划分,获得不同的结果。研究不同应用场景下应该采取哪种算法,以及研究生新的机器学习算法以便适应新的场景。
四、没有免费午餐定理
任何一个预测函数,如果在一些训练样本上表现好,那么必然在另一些训练样本上表现不好,如果不对数据在特征空间的先验分布有一定假设,那么表现好与不好情况将会一样多。
如果不对特征空间的先验分布有假设,那么所有算法的表现都一样。
机器学习的本质是,利用有限的已知数据,在复杂的高维特征空间中,预测未知的样本。
五、课后习题
1:给人脸打上标签再让模型进行学习训练的方法,属于(C)
A. 无监督学习
B.强化学习
C.监督学习
D.半监督学习
2:机器学习进行的第一步是(A)
A.特征提取
B.数据收集
C.交叉验证
D.模型训练
3.一般来说,在机器学习中,用计算机处理一幅图像,维度是(C)
A.三维
B.一维
C.上万维
D.二维
4.在“没有免费午餐定理”的时候,我们假设以上每一种情况出现的概率相同,请问这样的假设是基于如下哪种经验(B)
A.常识经验
B.无经验
C.学习经验
D.实践经验
5.在本课程中,我们把机器学习分成了哪几类(A B D)
A.半监督学习
B.传统监督学习
C.自监督学习
D.无监督学习
6.以下哪种算法是非显著式编程(B D)
A.编程统计一个地区的GDP
B.编程实现扫地机器人的路径规划
C.编程求解棋盘上八皇后问题
D.编程判断医疗CT片中的病变区域
7.下面哪种机器学习的分类,完全不需要人工标注数据(C D)
A.监督学习
B.半监督学习
C.无监督学习
D.强化学习
8.以下哪种算法是无监督学习算法(B C)
A.Q-LEARNING
B.主成分分析
C.空间聚类
D.支持向量机
9.以下哪些算法是监督学习算法(A B)
A.人工神经网络
B.支持向量机
C.ACTOR-CRITIC算法
D.高斯混合模型概率密度估计
10.机器学习中E、 T 、P分别表示(B C D)
A.Performance
B.Experience
C.Performance Measure
D.Task
六、讨论题
(1)举出其他监督学习、无监督学习、强化学习的例子
(2)说一下非显著式编程的优势
(3)既然没有免费的午餐定理成立,不管是机器还是人,为什么都还要学习