【论文&模型讲解】Learning to Select Knowledge for Response Generation in Dialog Systems(PostKS模型)
文章目录
- 前言
- 背景
- Posterior Knowledge Selection 模型(PostKS)
-
- 1. 对话编码器&知识编码器(Utterance Encoder&Knowledge Encoder)
- 2. 知识管理器(Knowledge Manager)
- 3. 解码器
- 4. 损失函数
- Q & A
-
- 1. 先验知识模块相关问题
前言
论文网址:Learning to Select Knowledge for Response Generation in Dialog Systems
源码网址:Posterior-Knowledge-Selection
本文讲解 Learning to Select Knowledge for Response Generation in Dialog Systems 中 Posterior Knowledge Selection(PostKS)模型的理论部分(不含实验)
这个论文其实研究的并不是很深,如有不足,欢迎指正。
背景
- 传统的Seq2Seq模型成功实现了生成流畅的回复,但是它倾向于生成信息较少的回复(通用的回复),如“我不知道”、“那很酷”,这就导致了对话并不那么有吸引力。
- 数据集Persona-chat和Wizard-of-Wikipedia在回复生成中引入了与对话相关的知识(例如Persona-chat中的个人简介)用于指导对话流程。Dinan等人使用ground-truth知识来指导知识选择,这是优于那些不使用这些知识的。然而,ground-truth知识实际上是很难获得的。
- 现有的研究大多是基于 输入语句 与 知识 之间的语义相似度来选择知识,这种语义相似度被认为是知识的先验分布。然而,先验分布不能有效地指导正确的知识选择,因为不同的知识可以用于对同一个的输入语句产生影响,从而生成不同的回复。相反,在给定输入语句及其相应的回复时,从输入语句和回复(区别于先验分布中的仅使用输入语句)中推导出的后验分布可以有效地指导知识选择,因为它考虑了回复中实际使用的知识。先验分布和后验分布的差异给学习过程带来了困难:模型在没有回复的情况下,仅根据先验分布难以选择合适的知识,在推理过程中难以获得正确的后验分布。这种差异会阻止模型通过使用适当的知识来产生正确的回复。
对于第3点,详细解释一下:假如说数据集中的输入语句是 X X X,它的回复是 Y Y Y,对于这个对话对儿有若干个知识 { K i } i = 1 N {\{K_i\}}_{i=1}^N {Ki}i=1N。先验分布就是说我在只知道 X X X的情况下,要挑选一个合适的知识 K i K_i Ki的准确性;而后验分布是不仅知道 X X X,且知道 Y Y Y的条件下,挑选一个合适的知识 K i K_i Ki的准确性,很显然后验分布是更准确,但后验分布只能在训练中得到,实际应用中,以聊天机器人为例,用户发送给系统一句话,因为回复是需要机器自己生成的,机器仅能依据用户的输入语句选择这个语句的知识,这时就只能得到先验分布。

| Utterance | 嗨!我没有最喜欢的乐队,但我最喜欢的读物是黄昏 |
| Profiles/Knowledge | |
| K1:我喜欢红辣椒乐队 | |
| K2:我的脚是六码女的 | |
| K3:我想成为一名记者,但我却在西尔斯卖洗衣机 | |
| R1(no knowledge) | 你是干什么的? |
| R2(use K2) | 我买了一双六码女鞋 |
| R3(use K3) | 我是个好记者 |
| R4(use K3) | 我也喜欢读书,并希望成为一名记者,但现在只能卖洗衣机 |
| Response | 我喜欢写作!想当记者但是我只能在西尔斯将就着卖洗衣机。 |
如上表中的对话,在这个数据集中,每一个角色都会与一个作为知识的角色相关联。两个角色根据相关的知识交换信息,给定一个语句Utterance,根据是否使用了适当的知识Knowledge,可以产生不同的回复R。
R 1 R1 R1 没有使用任何知识,因此生成一个信息较少的答复,而其他的答复拥有更多的信息,因为他们吸收了外部的知识(Profiles/Knowledge部分)。然而,在这些知识中, K 1 K1 K1 和 K 3 K3 K3 都与 输入语句Utterance 相关。如果我们仅仅根据 Utterance (即先验信息)选择 knowledge,而没有使用 K 3 K3 K3 来产生应答 R R R(即后验信息),则很难产生正确的应答,因为可能没有选择适当的知识。如果通过选择错误的知识(如 R 2 R2 R2 使用了 K 2 K2 K2)或与实际回复无关的知识(如 K 1 K1 K1)来训练模型,可以看出它们是完全无用的,因为它们不能提供任何有用的信息。请注意,在回复 R R R 生成中适当地吸收知识也很重要。例如,虽然 R 3 R3 R3 选择了正确的知识 K 3 K3 K3,但是它由于不恰当地使用知识,导致生成了不太相关的回复。只有 R 4 R4 R4 对 knowledge 进行了适当的选择,并在生成回复时适当地合并了它。
为了解决上述差异,提出将后验分布与先验分布分离。在知识的后验分布中,Utterance 和 回复Response都被利用,而先验分布在没有预先知道Response的情况下有效。然后,我们试着最小化它们之间的距离。具体来说,在训练过程中,我们的模型被训练成最小化先验分布和后验分布之间的 KL divergence 收敛,这样我们的模型可以利用先验分布准确地逼近后验分布。然后,在推理过程中,模型仅根据先验分布(即生成回复时不存在后验)对知识进行采样,并将采样后的知识纳入到响应生成中。在此过程中,该模型可以有效地学习利用适当的知识生成适当的、信息丰富的响应。
Posterior Knowledge Selection 模型(PostKS)
假设一个语句 X = x 1 x 2 ⋯ x n ( x t 是 X 中第 t 个单词 ) X=x_1 x_2⋯x_n( x_t 是 X 中第 t 个单词) X=x1x2⋯xn(xt是X中第t个单词),存在一个知识集合 { K i } i = 1 N {\{K_i\}}_{i=1}^N {Ki}i=1N,目标是从集合中选择适当的知识,并通过选择的知识生成应答 Y = y 1 y 2 ⋯ y n Y=y_1 y_2⋯y_n Y=y1y2⋯yn。PostKS模型的架构如图所示,主要由四部分组成:
- 对话编码器(Utterance Encoder):将 X X X编码成一个对话向量 x x x,并将其输入知识管理器。
- 知识编码器(Knowledge Encoder):将每一个 K i K_i Ki作为输入,然后把它编码成知识向量 k i k_i ki,当回复 Y Y Y可用时将其编码成向量 y y y。
- 知识管理器(Knowledge Manager):由两个子模块组成:先验知识模块和后验知识模块。给定先前编码的 x x x 和 { K i } i = 1 N {\{K_i\}}_{i=1}^N {Ki}i=1N(如果 y y y 可用),知识管理器负责选择一个适当的 k i k_i ki并使它(与一个基于注意的上下文向量 c t c_t ct)进入解码器。(这里的 y y y 是否可用是针对先验和后验的,先验就是不可用,后验就是可用)
- 解码器(Decoder):根据所选知识 k i k_i ki以及基于注意的上下文向量 c t c_t ct生成回复。
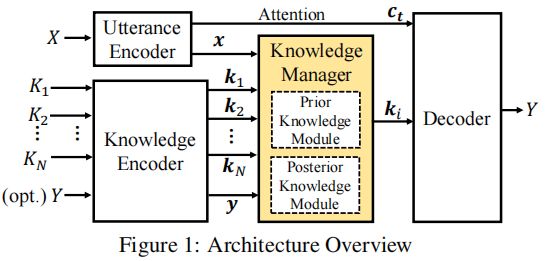
1. 对话编码器&知识编码器(Utterance Encoder&Knowledge Encoder)
在对话编码器中使用GRU的双向RNN(由前向RNN和反向RNN组成),对于语句 X = x 1 x 2 ⋯ x n X=x_1 x_2⋯x_n X=x1x2⋯xn,前向RNN从左向右读取 X X X并获得每个 x t x_t xt从左向右的隐藏状态 ( h t → \overrightarrow{h_t} ht) ,同理反向RNN从右向左读取 X X X并获得每个 x t x_t xt从右向左的隐藏状态 ( h t ← \overleftarrow{h_t} ht ) ,这两个隐藏状态合并成一个总的隐藏状态 h t h_t ht:

利用隐藏状态并定义 x = [ h t → ; h t ← ] x=[ \overrightarrow{h_t};\overleftarrow{h_t}] x=[ht;ht],这个向量会传送到知识管理器来优化知识的选择,同时它将会作为解码器的初始隐藏状态。
知识编码器的结构与对话管理器相同,但它们之间不共享参数。知识编码器使用双向RNN将每一个知识 K i K_i Ki(如果回复 Y Y Y可用)转化成向量 K i K_i Ki并传入知识管理器。
2. 知识管理器(Knowledge Manager)

给定编码后的语句 x x x和知识集合 { K i } i = 1 N {\{K_i\}}_{i=1}^N {Ki}i=1N,知识管理器的目标是选择一个合适的个性 k i k_i ki ,当应答 y y y可用时,模型也将同时利用 y y y得到 k i k_i ki 。知识管理器由先验知识模块和后验知识模块两个模块组成。
在先验知识模块中,定义了知识上的条件概率分布 p ( k │ x ) p(k│x) p(k│x):
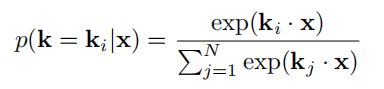
使用点乘来衡量 k i k_i ki 与 x x x 的关联性, p ( k │ x ) p(k│x) p(k│x)表示仅有 x x x的时候,即它在不知道应答的情况下工作,因此它是知识先验分布。但不同对话相关的知识各有不同,所以在训练中仅仅使用先验分布来选择知识是十分困难的。
在后验知识模块中,通过考虑输入语句及其应答,定义了知识的后验分布 p ( k │ x , y ) p(k│x,y) p(k│x,y):
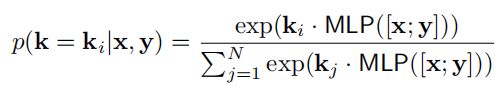
其中,MLP是一个全连接层。通过比较先验分布,后验分布是比较准确的,可以获得应答 Y Y Y使用的知识内容。
显然,后验分布在选择知识时是优于先验分布的(因为后验分布是在已知 x x x和 y y y的条件下的概率,而先验分布是在仅已知 x x x条件下的概率),但在推理生成应答阶段中,后验分布是未知的,因此期望先验分布能够尽可能地接近后验分布。为此,引入了Kullback-Leibler divergence loss(KLDivLoss)作为辅助损失函数,用来衡量先验分布和后验分布的接近性:
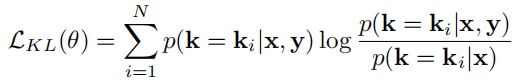
其中 θ 为模型参数。
在最小化KLDivLoss时,后验分布 p ( k │ x , y ) p(k│x,y) p(k│x,y)可以被视为标签,模型使用先验分布 p ( k │ x ) p(k│x) p(k│x) 来精确地近似 p ( k │ x , y ) p(k│x,y) p(k│x,y)。因此,即使在推理过程中后验分布是未知的(因为真实回复 Y Y Y是未知的),也可以有效地利用先验分布 p ( k │ x ) p(k│x) p(k│x) 对适当的知识进行抽样,从而产生合适的回复。作者认为它是第一个神经模型:将后验分布作为指导,使准确的知识查找和高质量的回复生成成为可能。
3. 解码器
解码器通过合并所选知识 k i k_i ki逐字生成应答,使用分级门控融合单元(Hierarchical Gated Fusion Unit, 简称HGFU)。HGFU提供了一种将知识融合到应答生成中的方法,由话语GRU、知识GRU和融合单元三个主要部分组成。
话语GRU和知识GRU遵循标准GRU结构,基于上一个状态 s t − 1 s_{t-1} st−1和上下文向量 c t c_t ct分别对最后生成的 y t − 1 y_{t-1} yt−1和选择的知识 k i k_i ki生成隐藏状态:
然后,融合单元将它们组合在一起,生成整体的隐藏状态:
其中, r = σ ( W z [ t a n h ( W y s t y ) ; t a n h ( W k s t k ) ] ) , W z , W y , W k r=σ(W_z [tanh(W_y s_t^y );tanh(W_k s_t^k )]),W_z,W_y,W_k r=σ(Wz[tanh(Wysty);tanh(Wkstk)]),Wz,Wy,Wk是参数。门控 r r r 控制 s t y 和 s t k s_t^y和 s_t^k sty和stk对最终隐藏状态 s t s_t st的影响比例,以便于它们能够灵活的融合。
获得隐藏状态 s t s_t st后,下一个单词 y t y_t yt 根据下面的概率分布生成:
4. 损失函数
仍然是看这个图,除了刚刚在上面 2. 知识管理器(Knowledge Manager) 中提到的 KLDivLoss,还用了NLL Loss 和 BOW Loss。
NLL Loss:用于衡量 真实response 和 模型生成的 response 之间的差异:

BOW Loss:通过加强知识与真实response的关联来确保采样知识 k i k_i ki 的准确性。论文中给出,令 w = M L P ( k i ) ∈ R ∣ V ∣ w=MLP(k_i)\in R^{|V|} w=MLP(ki)∈R∣V∣,其中 ∣ V ∣ |V| ∣V∣是 vocabulary size,定义
p ( y t ∣ k i ) = e x p ( w y t ) ∑ v ∈ V e x p ( w v ) p(y_t|k_i)=\frac{exp(w_yt)}{\sum_{v\in V}exp(w_v)} \quad p(yt∣ki)=∑v∈Vexp(wv)exp(wyt)
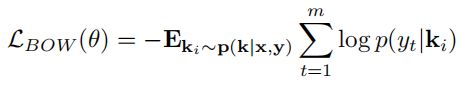
整个模型的损失函数就是将 KLDivLoss、NLL Loss 和 BOW Loss 三者相加:

在代码中也就是将这三个损失相加后作为整个模型的损失,共同调整模型参数:

Q & A
1. 先验知识模块相关问题
在知识管理器 Knowledge Manager 的先验知识模块中,定义了知识上的条件概率分布 p ( k │ x ) p(k│x) p(k│x):
这里可能会有疑问,给定了 知识( { k i } i = 1 N \{k_i\}_{i=1}^N {ki}i=1N) 和 输入语句( x x x) 不就能知道哪个 k i k_i ki 的概率最大了吗?
首先看 Manager 类中,下面是源码(model.py 中):
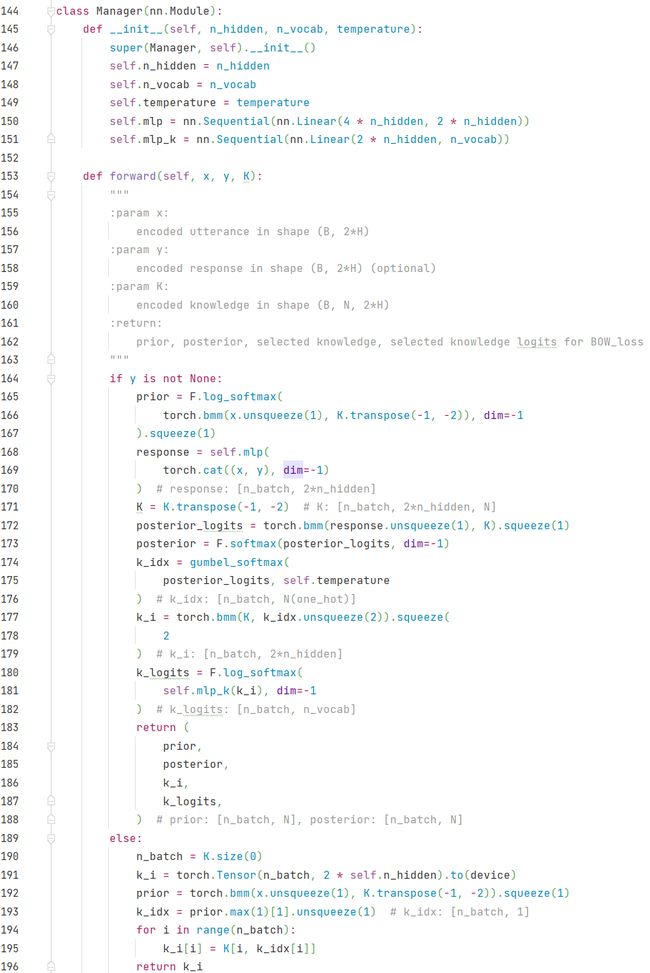
在 forward 中,有个 if 条件语句,用来判断 y y y 是否可用的( y y y 即是 r e s p o n s e response response,训练时 y y y 已知,测试时 y y y 未知),所以 满足y is not None时(训练时),计算了知识的先验和后验分布,而不满足y is not None时(测试时),仅仅能计算知识的先验分布。
在训练时(图中165-188行),prior 为知识的先验分布,其计算代码如下:
prior = F.log_softmax(
torch.bmm(x.unsqueeze(1), K.transpose(-1, -2)), dim=-1
).squeeze(1)
这么乍一看确实是 给定 { k i } i = 1 N \{k_i\}_{i=1}^N {ki}i=1N 和 x x x 就能知道哪个 k i k_i ki 的概率最大,这里确实是没涉及调整 Manager 中的模型参数,但是这其中的 x x x 和 K K K 是通过编码器(Utterance Encoder和Knowledge Encoder)得到的( x x x 和 K K K是通过模型计算得到的,并不是一成不变的),所以说 先验知识模块 这里应该是通过不断修改 编码器 中的模型参数来进行训练、优化的。
看下源码中训练的部分(train.py):
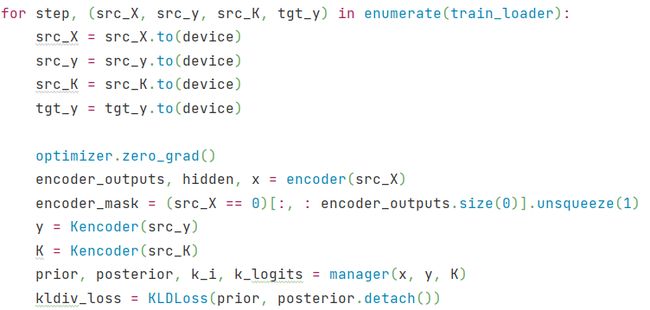
x x x 是通过encoder(源码 model.py 中的 Encoder 类)得到的,而 K K K 是通过Kencoder(源码 model.py 中的 KnowledgeEncoder 类)得到的。训练时即是通过不断调整 Encoder 和 KnowledgeEncoder 中 GRU 的参数,来不断优化先验分布的,来让知识的先验分布不断地贴近后验分布,以提高选择知识 K i K_i Ki 的准确率。
综上,公式确实是没有问题,不过这里的 x x x 并不是原始的输入语句, { k i } i = 1 N \{k_i\}_{i=1}^N {ki}i=1N也不是原始的知识,他们都是编码后的,训练时公式中的 x x x 和 k i k_i ki 是变化的,所以才能不断调整先验分布。不过这里确实有些误导因素,因为调整先验分布这部分的参数却不是在 Knowledge Manager 中实现的。