半监督3D医学图像分割(二):UA-MT
不确定性感知自集成模型
Uncertainty-Aware Self-ensembling Model for Semi-supervised 3D Left Atrium Segmentation
医学图像的分割标签需要专业医师标注,获取代价昂贵,而无标签的数据有很多。半监督学习则是将少量有标注的数据和大量无标注的数据直接输入到网络中,构建一致性损失或者多任务学习,达到比单独用有标注数据集更好的结果。
上一篇博文半监督3D医学图像分割(一):Mean Teacher中,将同一张图像加上不同的扰动,分别输入到学生网络和教师网络中,学生网络不仅从分割标签上学习训练,而且与教师模型做一致性优化。
教师网络的参数通过指数滑动平均,从学生网络迁移而来,但是没有分割标签的直接引导,教师网络的输出不一定靠谱。怎么让教师网络的输出更可靠呢?作者在Mean-Teacher的基础上,提出不确定性自感知模型(Uncertainty-Aware Self-ensembling Model),将图像加上不同的随机噪声多次输入教师网络中,对输出计算平均概率和不确定度,设计阈值过滤不确定的区域,得到更有意义更可靠的预测结果,然后再去指导学生网络。
网络设计
不确定性自感知模型(Uncertainty-Aware Self-ensembling Model)
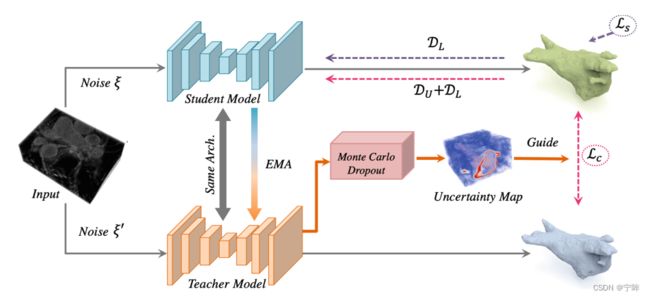
- input是输入图像,(b, c, h, w, d);Noise是高斯噪声,与input形状相同
- student model 和 teacher model 网络结构相同,都是 V-Net
- D代表MSE,L代表labeled,U代表unlabeled,DL和DU分别表示在有标签和无标签数据集上的MSE
- Ls代表有监督的损失,Lc代表一致性损失。有标签和无标签的图像都可以计算一致性损失。
在图像训练过程,教师模型在预测目标的同时评估了每个目标的不确定性。然后利用一致性损失优化学生模型,在不确定度的指导下,更关注不确定度低的区域。
不确定度评估
对每张输入图像随机添加随机噪声,多次输入到教师网络中,且在教师网络中使用nn.Dropout()随机丢失特征,进行T次正向传播,得到T组预测结果。因此,对于输入图像的每个像素,都可以得到T组softmax概率向量(1xC,C是类别),计算得到平均概率向量。借用信息熵作为不确定性的评估度量,公式如下所示
μ c = 1 T ∑ t p t c \mu_c = \frac{1}{T} \sum_{t}p_t^c μc=T1t∑ptc
u = − ∑ c μ c l o g ( μ c ) u = -\sum_c\mu_clog(\mu_c) u=−c∑μclog(μc)
- T是前向传播的次数,每个batch输入教师网络多少次
- c是分割类别,pt是第t次的概率图,μ是平均后的概率图
- u是信息熵,是所有分割类别 熵的概率加权
- p,μ,u的形状都是 H x W x D
下图是y = - [xlog(x)+(1-x)log(1-x)]的曲线
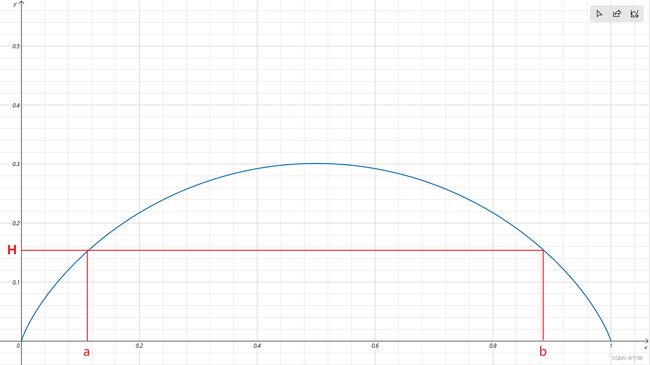
x在0和1之间,y随着x的增加先递增后递减。y表示不确定度,y越大的位置,不确定度越高。选定一个阈值H,过滤掉 y > H的区域,那么相当于只选择了(0,a)和(b,1)的区域,也就是不确定度低的区域。通俗的理解,以二分类为例(随机变量X要么是A类,要么是B类,非黑即白),如果X是A类的概率很小或者很大,我们可以说X是比较确定的,而X是A类的概率在0.5左右时,我们就说事件X是不确定的。
损失函数
下面是Mean Teacher分割模型的损失函数
θ ∗ = a r g m i n θ ∏ i = 1 N L s e g ( f ( x i ; θ ) , y i ) + λ ∏ i = N + 1 N + M L c o n ( f ( x i ; θ , η s ) , f ( x i ; θ ′ , η t ) ) \theta^* = argmin_{\theta} \prod_{i=1}^{N}L_{seg}(f(x_i;\theta),y_i) + \lambda\prod_{i=N+1}^{N+M}L_{con}(f(x_i;\theta,\eta^s),f(x_i;\theta',\eta^t)) θ∗=argminθi=1∏NLseg(f(xi;θ),yi)+λi=N+1∏N+MLcon(f(xi;θ,ηs),f(xi;θ′,ηt))
- θ和θ‘分别表示学生网络和教师网络的参数,η是随机噪声,y是标签
- N例有标签的数据,M例无标签的数据,i是数据索引
- Lseg 是dice loss或者交叉熵等常用的分割损失;Lcon是一致性损失,一般用MSE
- 每个 batch size 包含有标签的数据和无标签的数据,无标签的部分用来做一致性损失
与Mean Teacher相比,UA-MT只在不确定度低的区域计算学生网络和教师网络的一致性损失
L c o n ( f , f ′ ) = ∑ i I ( u i < H ) ∣ ∣ f i − f i ′ ∣ ∣ 2 ∑ i I ( u i < H ) L_{con}(f,f')=\frac{\sum_iI(u_i
上式,I 是符号函数(u
代码解读
UA-MT的网络架构同样以V-Net为基础(Backbone),与Mean Teacher在数据加载、训练框架部分基本一致。
for i_batch, sampled_batch in enumerate(trainloader):
volume_batch, label_batch = volume_batch.cuda(), label_batch.cuda()
unlabeled_volume_batch = volume_batch[labeled_bs:]
noise = torch.clamp(torch.randn_like(unlabeled_volume_batch) * 0.1, -0.2, 0.2)
ema_inputs = unlabeled_volume_batch + noise
outputs = model(volume_batch)
with torch.no_grad():
ema_output = ema_model(ema_inputs)
- unlabeled_volume_batch是无标签的图像
- noise是与unlabeled_volume_batch形状相同的高斯噪声,上下限为±0.2
- outputs是学生网络对当前batch的预测结果,ema_output是教师网络对添加noise后的unlabeled_volume_batch的预测结果
T = 8
volume_batch_r = unlabeled_volume_batch.repeat(2, 1, 1, 1, 1)
stride = volume_batch_r.shape[0] // 2
preds = torch.zeros([stride * T, 2, 112, 112, 80]).cuda()
for i in range(T//2):
ema_inputs = volume_batch_r + torch.clamp(torch.randn_like(volume_batch_r) * 0.1, -0.2, 0.2)
with torch.no_grad():
preds[2 * stride * i:2 * stride * (i + 1)] = ema_model(ema_inputs)
- T是前向传播的次数,每个unlabeled_volume_batch输入教师网络T次
- stride其实是unlabeled_volume的batch_size,volume_batch_r是复制两倍后的unlabeled_volume_batch
- preds是unlabeled_volume_batch T次的预测结果。因为复制了两倍,所以前向传播T//2次。
preds = F.softmax(preds, dim=1)
preds = preds.reshape(T, stride, 2, 112, 112, 80)
preds = torch.mean(preds, dim=0) #(unlabel_batch, 2, 112,112,80)
uncertainty = -1.0*torch.sum(preds*torch.log(preds + 1e-6), dim=1, keepdim=True) #(unlabel_batch, 1, 112,112,80)
-
F.softmax得到概率图 -
对T组概率图求平均,对应公式
μ c = 1 T ∑ t p t c \mu_c = \frac{1}{T} \sum_{t}p_t^c μc=T1t∑ptc -
计算平均概率图的不确定度,对应公式
u = − ∑ c μ c l o g ( μ c ) u = -\sum_c\mu_clog(\mu_c) u=−c∑μclog(μc)
- 最终得到的不确定图(uncertainty map),形状为(unlabel_batch, 1, H, W, D)
# supervised loss
loss_seg = F.cross_entropy(outputs[:labeled_bs], label_batch[:labeled_bs])
outputs_soft = F.softmax(outputs, dim=1)
loss_seg_dice = losses.dice_loss(outputs_soft[:labeled_bs, 1, :, :, :], label_batch[:labeled_bs] == 1)
supervised_loss = 0.5*(loss_seg+loss_seg_dice)
对batch中有标签的图像计算损失,损失函数是分割任务中常用的交叉熵和dice损失
consistency_weight = get_current_consistency_weight(iter_num//150)
consistency_dist = consistency_criterion(outputs[labeled_bs:], ema_output) #(batch, 2, 112,112,80)
threshold = (0.75+0.25*ramps.sigmoid_rampup(iter_num, max_iterations))*np.log(2)
mask = (uncertainty<threshold).float()
consistency_dist = torch.sum(mask*consistency_dist)/(2*torch.sum(mask)+1e-16)
consistency_loss = consistency_weight * consistency_dist
loss = supervised_loss + consistency_loss
-
每150个iteration更新一次损失权重,下图是权重随iteration的变化曲线和公式,常数系数为0.1
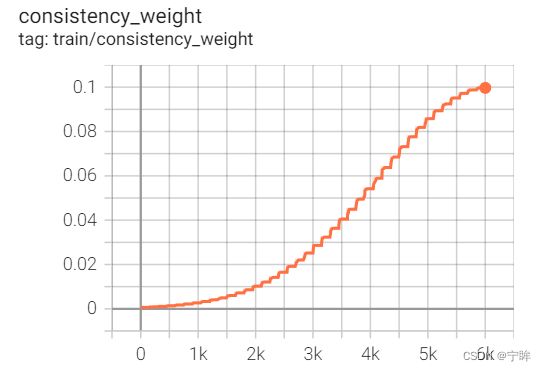
λ ( t ) = ω m a x ⋅ e − 5 ( 1 − t t m a x ) \lambda(t) = \omega_{max} \cdot e^{-5(1-\frac{t}{t_{max}})} λ(t)=ωmax⋅e−5(1−tmaxt)
- 阈值(threshold)也随iteration变化,从 0.75ln2 逐渐增加到 ln2
- 一致性损失(consistency_dist)是 ema_output 和 outputs[labeled_bs:] 的MSE损失
- 通过阈值过滤掉不确定度高的区域,只对不确定度低的区域做一致性损失,对应公式
L c o n ( f , f ′ ) = ∑ i I ( u i < H ) ∣ ∣ f i − f i ′ ∣ ∣ 2 ∑ i I ( u i < H ) L_{con}(f,f')=\frac{\sum_iI(u_i
- mask对应公式中的I(ui
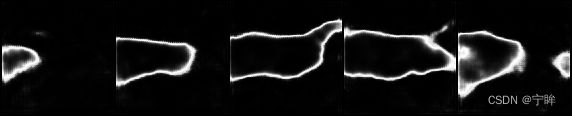

注意,uncertainty map中,亮度越高,不确定度越高;mask map是二值图,亮处表示不确定度超过阈值的区域I(u>H),一致性损失只在暗处计算。
其余代码细节见LASeg: 2018 Left Atrium Segmentation (MRI)中的train_UAMT.py
实验结果
论文中的可视化结果:
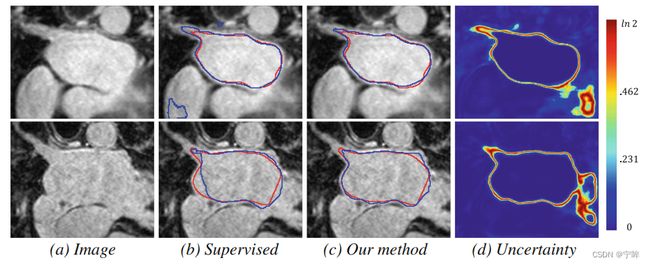
论文里提到,在 Left Atrium (LA) MR dataset 数据集实验中,不确定图在靠近大血管边界和模糊区域的不确定度较高。
我的实验结果:
分割结果重建图:蓝色是金标签,红色是模型预测结果
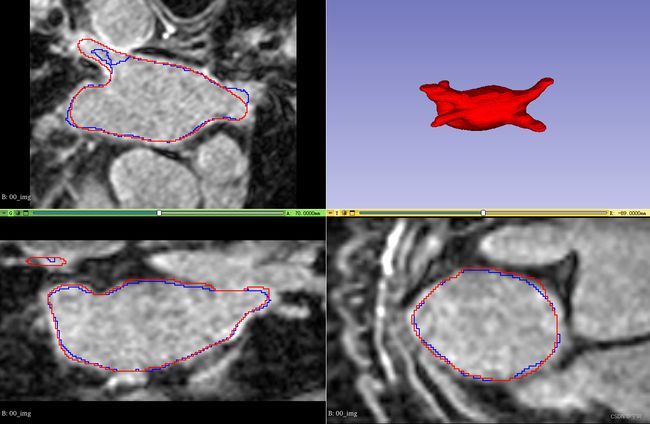
- 一共154例数据,123例当做训练集,31例当做测试集
- 分别使用20%和10%的标签数据集进行实验,推理结果如下表:
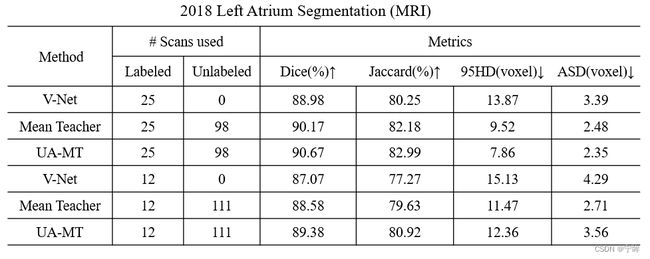
只使用20%的标签,Dice就达到了90.67%,Jaccard(IOU)相比全监督的V-Net,提高了2.74%。
相比Mean Teacher,UA-MT的量化指标有一定提升,证明了不确定度自感知模型的有效性。
在医学图像分割领域,自从Mean Teacher架构的半监督图像分割网络架构以及一致性损失的概念被提出以后,有很多人都对其进行了改进,UA-MT精炼教师网络的预测结果,去更好的引导学生网络,是比较有代表性的一种方法。
另外有人提出对分割模型的多级特征,去做深监督损失和一致性损失,下一篇博客将会介绍。
参考资料:
Yu L, Wang S, Li X, et al. Uncertainty-aware self-ensembling model for semi-supervised 3D left atrium segmentation[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2019: 605-613.
项目地址:
LASeg: 2018 Left Atrium Segmentation (MRI)
如有问题,欢迎联系 ‘[email protected]’