机器学习模型(线性回归、逻辑回归、决策树和随机森林、SVM&向量机)
目录
- 包
- 机器学习模型
-
- 股价预测
- loss
- SGD
- 线性回归(模型是什么样?损失函数是什么?)、逻辑回归
-
- houseing.data
- 线性回归
- 损失函数是什么
- 去猜服从什么分布!
- 防止过拟合
- 怎么防止过拟合?
- 正则项与防止过拟合
- 怎么确定L1和L2的值呢?
- 梯度算法
- 为什么叫回归?
- 梯度下降算法
- 逻辑回归
- 推导
- 机器学习模型--决策树和随机森林
-
- 决策树:level
- 信息熵
- 随机森林是一个简单的混合模型
- 香农信息熵
- 神经网络
- SVM & 向量机
-
- 线性可分向量机
- 支持向量机的原理和目标
- 点到直线的距离
-
- 支持向量机的计算
- SVM代码
- 聚类
R/python/jupter
jupter notebook
包
mpl_finance
数据清洗与特征选择
OpenCV图像处理
时间序列分析
疫情模拟
机器学习与深度学习
机器学习模型
股价预测
方法:自回归
loss
SGD
线性回归(模型是什么样?损失函数是什么?)、逻辑回归
高斯分布,最大似然估计MIE,最小二乘法
逻辑回归和softmax和神经网络中的全连接层
houseing.data
500多个不同房屋的信息
m=506,n=13,Xmn Ym1
(xi,yi)
输入xi,输出yi,
xi---->yi得到一个模型。
yi=Model(xi,Θ)
参数记为Θ,里面含有多个参数,Θ是个向量,x,y是已知,
Θ是未知向量,VGGNet :138M 参数, 线性回归:14个
yi_predice与yi之间误差总和(平方和)是最小的。(yi_predice(Θ)-yi)(2)
CROSS Entropy:交叉熵
SSE
MSE:均方误差,
loss=模型误差和/个数m,loss只与Θ有关,称为损失函数。
Θ初始化:随机/先验
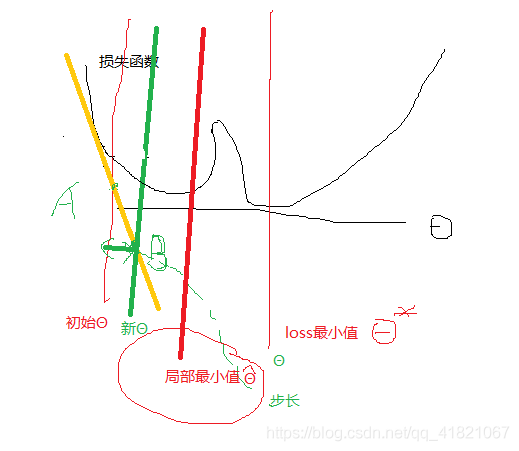
我们不知道函数是什么?对损失函数求偏导。∂loss/∂θ,沿着负梯度做下降?Θ
技术点
梯度下降算法
最大似然估计
线性回归
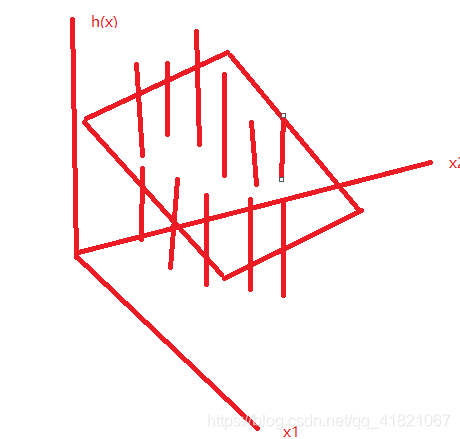
模型是什么?
一元,二元,
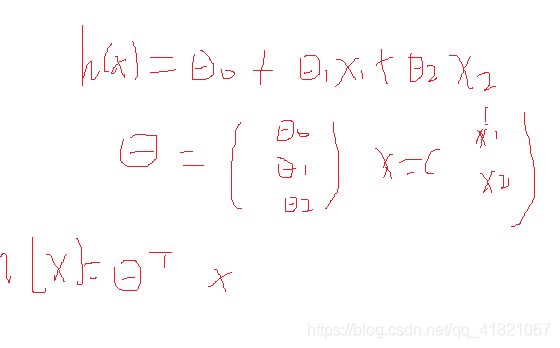
损失函数是什么
误差有正有负
去猜服从什么分布!
高斯是不直观,欧拉是直观,自己去确定的。
(假设)误差是独立同分布的,服从均值为0,方差为σ²的高斯分布、
P(y1,y2,y3…ym)是似然概率。
L(Θ)最大似然函数。

图上的x,y是训练样本
使用梯度下降算法不能保证是最优的。
防止过拟合
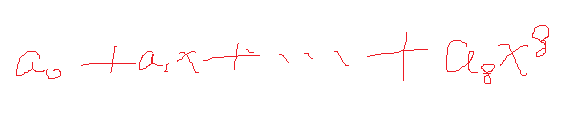
y值可以通过X的值求出来。
可以求得Θ是9行一列的,就是从(a0…a8)

将扭曲的线:过拟合
将直线称为欠拟合
怎么防止过拟合?
模型不能过于复杂,如果非要选择复杂模型去做,
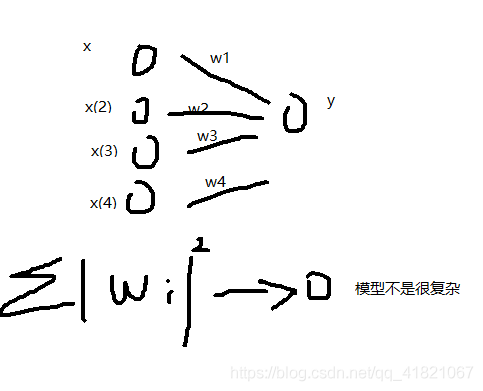
在逻辑回归logisticregression中,C是1/2λ,
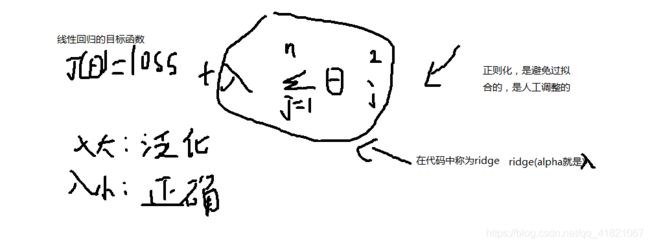
正则项与防止过拟合
正则就是定义的规则,不让参数变得太大,
conv2D 的kernel_regularizer(正则核),bias_regularizer可以给出L1或者L2,或者L1和L2
这样的话过拟合的线就会变得平滑
通过正则化计算得到高次方的系数几乎为0,把其删掉,取低次方的系数,也就是降维。这会更加接近我们的真实情况。
怎么确定L1和L2的值呢?
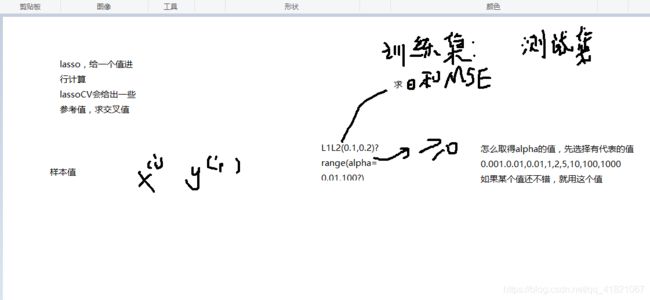
对数空间的线性模型,lassoCV中的参数**logspace(-3,3,20)**就是从0.001到1000的20个值。是现实中的指数值。alphas默认是100个值,就是值的个数。
RidgeCV 的cv值是交叉验证去几则,不要取得太大,默认是3则,决定分割稳定性。
梯度算法
为什么叫回归?
Y是连续的,回归是预测,离散是分类。噪声是要回归到均值的。
对于加权的要用到L1,l2,决策用 就用到其他。
梯度下降算法
迭代
给出初始值和学习率与梯度函数,求x=0(初始值)的梯度

用损失函数做梯度下降算法。假如有1000个样本,求取某一个样本下的梯度,然后对参数做更新,求第二个样本的梯度,再更新,这就是随机梯度下降算法。对样本的梯度加和,这是批量下降梯度算法,只要给出合适学习率,都可以求极小值,随机梯度下降可能有偏差。

逻辑回归
y的取值,是离散还是连续?
连续是回归,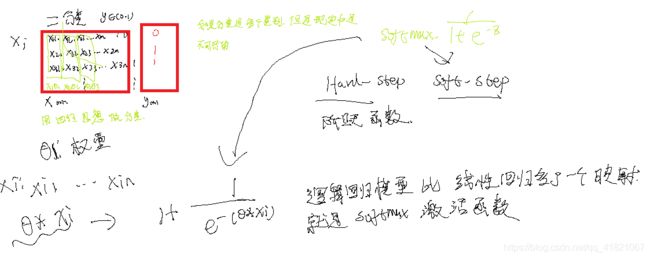

推导


机器学习和深度学习的其他模型是怎样的?
交叉熵预测值和真实熵的熵
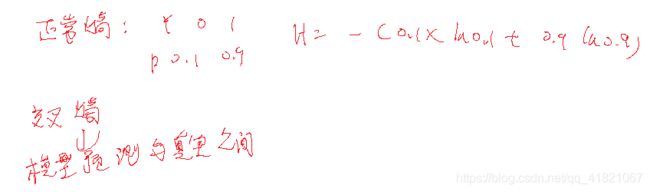

怎样将训练集和数据集分开
x_train,x_test,y_trian,y_test=train_test_split(x,y,test_size=0.3)
model=logicregression()
model.fit(x_train,y_train)
y_train _pred=model.predict(x_train)
print(“训练正确率”+accuracy_score(y_trian_pred,y_train))
有过拟合行为
用正则项

逻辑分类超过两个要用softmax,
4分类:ABCD
A|BCD
B|ACD
C|ABD
D|ABC
弄成4个二分类器,代码中用到权值和截距
multi_class=multionmial是多分类器,是不能使用liner学习方法,可以使用拟牛顿学习算法
机器学习模型–决策树和随机森林
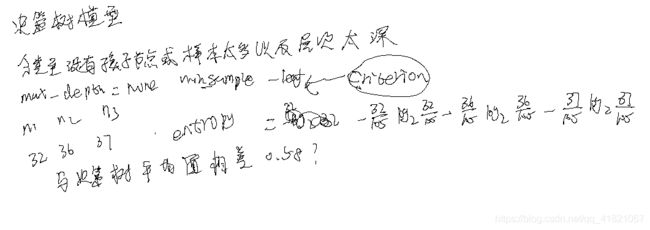
决策树:level
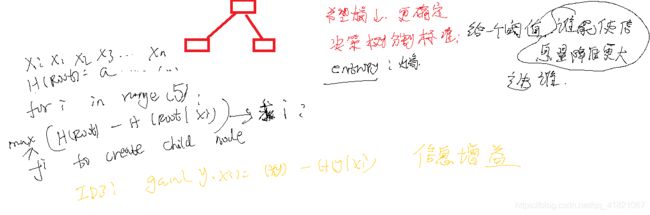
信息熵
度量模型不确定程度的量
Y:红,绿色
N:100 100
100/200=0.5
从 200个随机选择的概率都是0.5
如果红是0.9,绿是0.1 ,这样更有意义,更利于我们对类别的判定。
决策树可以容纳的样本个数是很深的。现实中做决策树不是很深的,在做决策树的时候,如果多加一层样本数量就会极速膨胀。
随机森林是一个简单的混合模型
香农信息熵

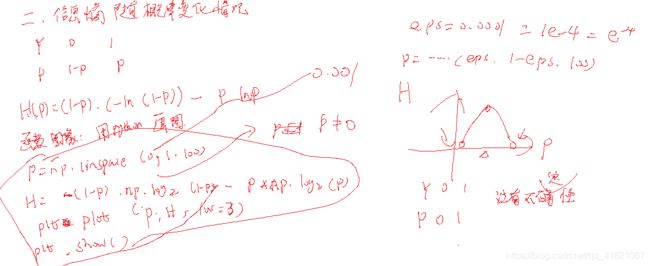






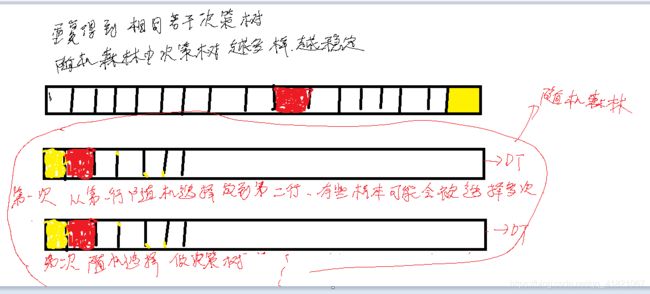




1、随机森林怎么做回归
2、数据不均衡,怎么用随机森林进行调整。
神经网络
SVM & 向量机
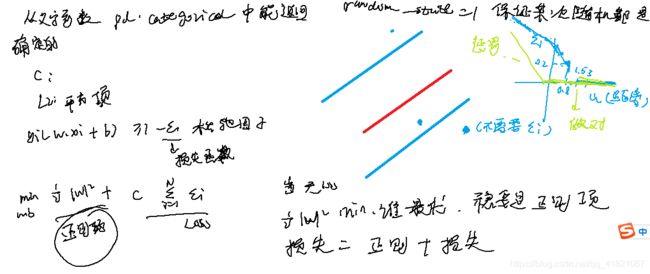
线性可分向量机
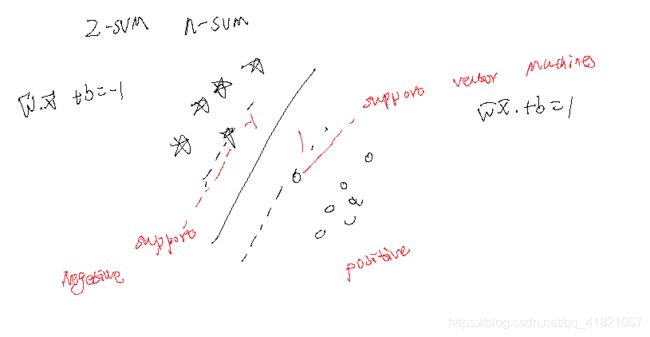

支持向量机的原理和目标
点到直线的距离

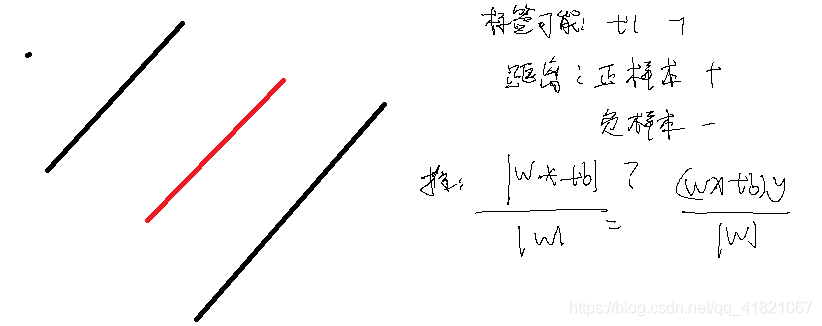

支持向量机的计算




SVM代码


聚类
无监督的
