Bag of Tricks for Long-Tailed Visual Recognition with Deep Convolutional Neural Networks
长尾分布在图像识别中的相关技巧总结
背景
目前图像识别领域在长尾分布上存在着巨大挑战,类总是展现出数据不平衡,虽然一些复杂的方法和改良方案(eg:调整特征、损失函数)都起到了一定的作用,但是这些方法可能会发生冲突,目前并没有一个具体的实验指导原则,说明这些方法结合的有效性。
本文主要内容
总结了目前所有在图像识别中的长尾分布主流的技巧方法,并且做了相关的对照试验,对比出每一类中效果最好的,并且提出了一种不同类别的相互融合的最佳方法。同时提出了一个基于类激活图的数据增强方法,用于基于re-sampling的两阶段训练中,展现出了很好的效果。如图所示:

数据集
- CIFAR-10-LT 和CIFAR-100-LT(基于CIFAR的变异数据集,通过指数函数来减少每一类训练样本数量),不平衡因子分别是50和100
- iNaturalist 2018 是包含437513张图片,有8142类别的真实场景下大规模不平衡数据集
- ImageNet-LT(ImageNet ,采用Pareto distribution的子集,构建最大类别包含1280图像,最小类别包含5图像的不平衡数据集)
基线设置
ResNet
一、Re-Sampling Methods
这类方法时通过重新采集数据样本使得数据集均衡(可以理解为在输入的这一部分改善数据集不平衡的问题)
- Random over-sampling 随机上采样
从少数类样本中随机复制训练数据,这种方法是有效果的,但是可能会导致过拟合 - Random under-sampling 随机下采样
从多数类样本中随机移除训练样本,直到所有样本平衡,这种方法在一些问题上会优于上采样 - Class-balanced sampling 类平衡采样
使每一个图片被选择概率相等,不论其类别。类平衡采样的核心就是根据不同类别的样本数量,对每个图片的采样频率进行加权。公式中q=0.

局限性
重采样就是在已有数据不均衡的情况下,人为的让模型学习时接触到的训练样本是类别均衡的,从而一定程度上减少对头部数据的过拟合,不过由于尾部的少量数据往往被反复学习,缺少足够多的样本差异,不够鲁棒,而头部拥有足够差异的大量数据又往往得不到充分学习,所以重采样也并非是个真正完美的解决方案。
二、Re-Weighting Methods
这种方法是通过为不同的类分配不同权重使得网络更加关注少数类(把整个网络结构可以看成由输入、model网络结构、loss这三个部分,那么这个方法就是通过改变loss来使得网络在反向传播的时候更加关注少数类),但是实验证明,当类别增加时,使用该方法的效果不好
1. CE(cross-entropy)
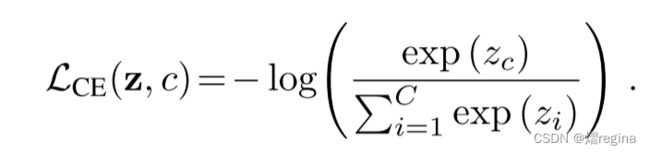
2. CS_CE(Cost-sensitive softmax cross-entropy loss)
3. Focal loss


4. CB_Focal loss

5. CB_CE

局限性
本文对该类方法进行了实验,表明当类别增加,或者不平衡数据量更大时,直接使用该类方法,效果不好
作者也会在接下来阐述在两阶段训练的方法中应用重加权的方法会时有效的策略
三、Mixup Training
混合采样可以看做是数据增强的方法,可以增强模型的泛化能力,并且能够提高模型对于对抗攻击的鲁棒性。在图像识别的长尾分布数据中,混合采样的效果很好,尤其是结合重采样,本文介绍了两种混合采样方法
1. Input mixup
每一个新的样本是由两个随机采样(xi,yi)和(xj,yj)组成,通过加权线性插值如下:

2. Manifold mixup

3. fine-tuning after mixup training
使用mixup训练的模型可以在最后几个epochs去除mixup,表现出更好的结果
四、Two-Stage Training Procedures
两阶段训练包含不平衡训练和平衡微调,换句话说就是先让模型在不平衡的训练集上进行训练,然后再通过重采样或者重加权的方法,得到一个相对平衡的数据集,然后再进行微调,本文主要是探索了平衡微调的不同方法,并且提出了一种新的CAM-based-sampling方法
1. DRS(deferred re-balancing by re-sampling)
该方法是中涉及到的重采样主要是基于前文re-sampling中提到的方法,在这里作者提出了他的创新方法叫CAM-based-sampling
2. DRW(deferred re-balancing by re-weighting)
该方法中涉及到的重加权主要是在前文中re-weighting中提到的方法
3. 在DRS基础上提出的CAM-Based-Sampling(本文作者利用热力图提出的数据增强的方法)

实验结果
DRS结合CAM-based balance-sampling的效果最好,DRW结合CS_CE的结果最好
五、Trick Combinations
实验结果表明
CAM-BS结合CS-CE的精度低于CAM-BS,因为他们都是试图扩大尾部类的影响,并且两者的联合使用可能由于过拟合的问题而导致精度下降
与其他最佳的技巧相结合时,input mixup会比manifold mixup更高,其中DRS 结合CAM-BS的方法加上Input mixup的方法精度更高
六、Applying the Best Tricks Incrementally
作者进一步的将每一类方法中性能最好的方法相结合发现
实验结果表明:
在DRS中使用CAM-based balance-sampling,并结合input mixup,在mixup训练之后进行微调的结果最佳
参考文献
《Bag of Tricks for Long-Tailed Visual Recognition with Deep Convolutional Neural
Networks》