零样本分割系列论文(2)Open-Vocabulary Instance Segmentation via Robust Cross-Modal Pseudo-Labeling
我最近刚刚入门zero-shot segmentation,准备以此作为我的博士研究方向,这是我入门这个方向读的第二篇论文,这篇论文我读了5遍以上,文章篇幅有限,所以很多细节我在读论文的时候发现不了,导致我在跟师兄师姐分享论文的时候,他们提出的一些问题我回答不上来。于是,在读了很多遍之后,啊我的阅读笔记分享一下,可能还是有不对的地方,文章暂时没提供代码,有些细节问题可能还是得阅读源码。
写在前面:可以只看第四部分,对pipeline的描述
1. 出处
2021.11.24挂在arXiv上,据说是投了2022年CVPR
2. 问题
已有的方法需要昂贵的mask annotations。Open-vocabulary instance segmentation能够不需要mask annotations分割novel classes。
大多数已有的工作,首先在包含大量novel classes的文字描述的图像上预训练模型,然后在limited带有mask annotations的base classes上微调。
然而,单纯在captions进行pre-train学到的high-level textual information,无法有效地encode pixel-wise segmentation所需的细节。
详细来说,zero-shot instance/semantic segmentation能够利用高维语义描述如word embeddings,在没有novel classes训练样本的情况下,分割novel classes。然而,当前的zero-shot instance/semantic segmentation方法效果不够好,因为high-level word embeddings无法有效的编码细粒度的shape信息。
3. 解决方案
解决方案的核心思想是:通过使用low-cost captioned images分割novel classes,极大减少mask supervision的数量
提出了一个cross-modal pseudo-labeling框架,通过对齐说明文字中的word semantics和图像中object masks的visual features来生成training pseudo masks,并将这种能力泛化到novel classes。
该框架能够通过word semantics self-train一个student model,无需任何mask annotations,分割captioned images的objects。
为了解释pseudo masks里的噪声,作者设计了一个鲁棒的student model,能够通过估计mask noise levels选择性地distill mask knowledge,从而减轻noisy pseudo masks的不利影响。
4. 整体模型
4.1 setting
训练:
base classes : 每个图像对应一系列ground truth标注,包括instance masks和对应的目标类别(起到预训练作用)
额外的图像 : 为了能够分割novel classes,利用额外的图像,每个图像只有一段说明文字作为注释,从中可以提取出一系列objects nouns,从caption annotations可以抽取出很多caption classes,远远多于base classes
测试:
novel classes:没有任何mask annotation,训练阶段也没见过,这些类别仅仅被用作proxy来评估对novel classes的分割效果,object的类别可能是base classes,additional classes,或者novel classes
通过使用预训练好的BERT模型提供的high-level semantic embedding,作者的模型可以识别很多novel classes。给定BERT Embeddings,可以利用class semantic similarity从base/caption classes迁移知识到target classes上
在对novel classes进行识别的时候,使用通过BERT模型训练得到的high-level semantic embeddings
4.2 base detector
Mask R-CNN
4.3 cross-modal pseudo-labeling framework
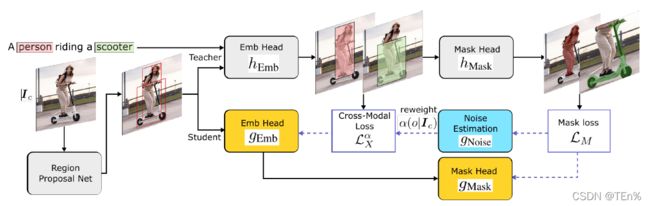
4.3.1 Pipeline
-
训练过程
-
Teacher model
embedding head用于分类,对captions中的每个object,选择最适配的region proposal。
mask head用于生成class-agnostic mask
分为两个阶段,第一阶段预训练backbone(ResNet50),在COCO Captions还有Conceptual Captions上预训练,得到vision-semantic模型。(Conceptual Captions很大,所以能学到很多图像和类别的对应关系)
然后在COCO和Open Images数据集上进行检测/分割任务,微调backbone,得到teacher模型。
首先利用RPN获得输入图像的region proposals,teacher的embedding head能够获得所有region的visual features,将region features映射到词向量的语义空间上,将visual embedding和word embeddings点乘,计算每个region每个类别的对应得分。通过在visual features和word embeddings学习一个共同的embedding空间,teacher可以泛化到novel classes.
此外,还学习一个class-agnostic Mask R-CNN-based head分割每个region的物体,通过h_mask预测mask logit scores。
-
Student model
在包含captions和base classes的数据集上训练
student和teacher不是同时训练的,teacher训练好后,作为student的初始参数(将teacher的mask知识和captions迁移到sudent model。)
-
将teacher对齐好的目标区域用于训练student,对于每个对齐的区域,最大化它和目标词之间的相似度,最小化它和非目标词之间的相似度
-
teacher的mask head可以得到每个region对应的pseudo mask,作为student的mask head的label
-
通过三部分来优化student,base class对应的基础的分割损失(知道对应的GT),跨模态损失,噪声估计损失
-
-
测试过程
使用student完成测试,利用caption中目标词提供的类别,匹配对应的区域,然后使用mask head预测mask
在base classes上,训练一个teacher模型,使用这个模型来选择visual features能够与captions中的词语义最适配的目标区域。这些区域进一步被分割成pseudo masks,代表captions里的object words。然后将pseudo masks蒸馏出来用于训练一个robust student,能够共同学习分割并估计pseudo-mask noise levels,为不正确的teacher预测降低权重。
对每个caption-image对,通过选择visual features与(captions中object words的)semantic embeddings最适配的mask predictions,来生成pseudo masks.
4.3.2 Teacher Model详细内容(可不看)
teacher model包括embedding head用于分类,和一个class-agnostic mask head用于分割。
然后,在teacher predictions和captions中蒸馏mask knowledge,用于student model,共同在pseudo masks中学习,并估计mask noise levels来降低unreliable pseudo masks的权重。
给定region proposals,将他们分类到captions提到的任意类别。作者将Mask R-CNN分类头中的全连接层,替换成了embedding head h_Emb,h_Emb将region features映射到词向量的语义空间中。通过embedding head,每个区域类别o的分数通过该类的word embedding和region’s visual feature之间的内积计算得到的。
通过学习一个visual features和word embedding之间共同的embedding space,teacher可以通过度量visual和textual features的兼容性,泛化到novel classes。
此外,还训练一个class-agnostic Mask R-CNN-based head来分割每个区域的物体,h_Mask是mask head,能够预测mask logit scores.
尽管teacher可以分割novel classes,但由于缺乏标注,还是会对novel classes误分类。为了对novel classes提供额外的监督信息,提出了cross-modal pseudo-learning method,能够使用caption words里的语义信息来指导teacher预测,并生成pseudo masks用于self-training一个student model
4.3.3 Cross-Modal Pseudo-Labeling详细内容(可不看)
首先,利用captions识别图像中的物体,提取caption里的名词,为了定位图中这些object words的位置,提出了cross-modal
alignment,能够选择与captions中名词的word embeddings特征最兼容的区域。
给定对齐的object regions,引入了cross-modal loss,训练student,识别这些区域,作为他们的positively-matched caption words.

对于每一个对齐的目标区域b_o,student通过Softmax normalization最大化他的object words的分数,最小化其他不相关的words的分数。
word embedding(textual modality)和aligned object regions(visual modality)中的信息蒸馏到student embedding head中,以扩展student关于caption中novel classes的知识。
cross-modal loss在student embedding head上计算,忽视了用于分割的mask head。因此,提出从teacher中获得pseudo masks,并估计这些masks的noise level
4.3.4 Estimating Pseudo-Mask Noises
给定aligned object regions,通过对这些区域使用teacher mask head,将其转变成二值化的pseudo masks,正确预测的pixel值为1,其他为0。
直观上,可以通过在每个像素上模拟出pseudo masks,将其和teacher生成的pseudo作比较,训练student model。
然而,由于teacher的预测错误,并不是captions中的所有objects都能被正确检测到。因此,最小化pixel-wise loss会将错误从pseudo mask传递到student mask head,使得模型退化。
为了消除pseudo label error的影响,作者提出估计pseudo masks的noise level。student为pseudo masks中的每个像素预测一个额外的noise value。
假定pseudo mask中的每个像素被高斯噪声腐蚀,方差可以通过aligned object region的visual features估计。
student很难通过分割错误的Pseudo masks进行学习,会使得g_noise估计高noise level来适应这些errors
4.3.5 训练鲁棒的student model
因为student model和teacher model由于缺乏标注信息,无法知道正确的novel object masks。所以,作者提出将mask noises作为proxy,推断pseudo masks是否reliable。