【Pytorch学习笔记十一】卷积神经网络(CNN)详细介绍(组成、常见网络模型)

文章目录
-
- 1.为什么要使用卷积神经网络
- 2.卷积神经网络的结构组成
-
- 2.1卷积层
-
- 1.卷积计算过程
- 2.卷积计算过程中的参数
- 4.多通道卷积计算过程
- 2.2 其它层
-
- 1. 池化层(pooling)
- 2. dropout层
- 3. 全连接层(FC)
- 3.经典的网络模型介绍
-
- 3.1 LeNet-5
- 3.2 AlexNet
- 3.3VGG
- 3.4 GoogLeNet (Inception)
- 3.5 ResNet
- 4.网络选择
卷积神经网络由一个或多个卷积层和顶端的全连通层(也可以使用1x1的卷积层作为最终的输出)组成一种 前馈神经网络。一般的认为,卷积神经网络是由Yann LeCun大神在1989年提出的LeNet中首先被使用,但是由于当时的计算能力不够,并没有得到广泛的应用,到了1998年Yann LeCun及其合作者构建了更加完备的卷积神经网络LeNet-5并在手写数字的识别问题中取得成功,LeNet-5的成功使卷积神经网络的应用得到关注。2006年后,随着深度学习理论的完善,尤其是计算能力的提升和参数微调(fine-tuning)等技术的出现,卷积神经网络开始快速发展,在结构上不断加深,各类学习和优化理论得到引入,2012年的AlexNet、2014年的VGGNet、GoogLeNet 和2015年的ResNet,使得卷积神经网络几乎成为了深度学习中图像处理方面的标配。
1.为什么要使用卷积神经网络
对于计算机视觉来说,每一个图像是由一个个像素点构成,每个像素点有三个通道,分别代表RGB三种颜色(不计算透明度),我们以手写识别的数据集MNIST举例,每个图像的是一个长宽均为28,channel为1的单色图像,如果使用全连接的网络结构,即,网络中的神经与相邻层上的每个神经元均连接,那就意味着我们的网络有28 * 28 =784个神经元(RGB3色的话还要*3),hidden层如果使用了15个神经元,需要的参数个数(w和b)就有:28 * 28 * 15 * 10 + 15 + 10=117625个,这个数量级到现在为止也是一个很恐怖的数量级。
如何减少参数?
**参数共享:**相比全连接网络一个参数对应一个像素特征,卷积网络中一个卷积核(9个参数)与特征之间不是一一对应的,实现了参数共享。
**稀疏连接(对比全连接理解):**比如,我们看输入图像左上角的9个像素和卷积核进行卷积之后,对应得到的特征图中的左上角的1个像素(这个像素只会受到输入图像左上角的9个像素的影响,不会受到其他像素的影响)。
2.卷积神经网络的结构组成
上面说到传统的网络需要大量的参数,但是这些参数是否重复了呢,例如,我们识别一个人,只要看到他的眼睛,鼻子,嘴,还有脸基本上就知道这个人是谁了,只是用这些局部的特征就能做做判断了,并不需要所有的特征。 另外一点就是我们上面说的可以有效提取了输入图像的平移不变特征,就好像我们看到了这是个眼睛,这个眼镜在左边还是在右边他都是眼睛,这就是平移不变性。 我们通过卷积的计算操作来提取图像局部的特征,每一层都会计算出一些局部特征,这些局部特征再汇总到下一层,这样一层一层的传递下去,特征由小变大,最后在通过这些局部的特征对图片进行处理,这样大大提高了计算效率,也提高了准确度。
2.1卷积层
1.卷积计算过程

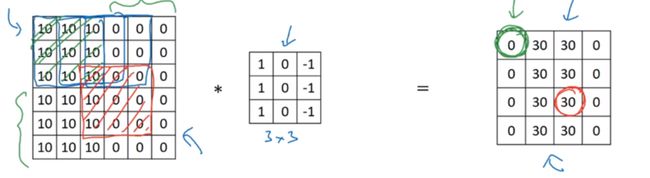
一个权重矩阵,也就是我们说的W(一般对于卷积来说,称作卷积的核kernel也有有人称做过滤器filter),这个权重矩阵的大小一般为3 * 3 或者5 * 5(在LeNet里面还用到了比较大的7 * 7,现在已经很少见了,因为根据经验的验证,3和5是最佳的大小)。 我们以图上所示的方式,我们在输入矩阵上使用我们的权重矩阵进行滑动,每滑动一步,将所覆盖的值与矩阵对应的值相乘,并将结果求和并作为输出矩阵的一项,依次类推直到全部计算完成。
上图所示,我们输入是一个 5 * 5的矩阵,通过使用一次3 * 3的卷积核计算得到的计算结果是一个3 * 3的新矩阵。 那么新矩阵的大小是如何计算的呢?
2.卷积计算过程中的参数
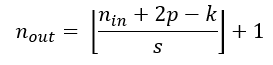
- n i n : 输入的尺寸 n_{in}:输入的尺寸 nin:输入的尺寸
- p : 填充的大小 p:填充的大小 p:填充的大小
- K : 卷积核尺寸 K:卷积核尺寸 K:卷积核尺寸
- s : 步长 s:步长 s:步长
- n o u t : 输出尺寸 n_{out}:输出尺寸 nout:输出尺寸
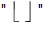 是向下取整符号,用于结果不是整数时进行向下取整。
是向下取整符号,用于结果不是整数时进行向下取整。
如下示例:
P(padding)为1,s(stride)也为1,f(filter)卷积核大小为3×3,卷积计算过程,的输出=((5+2-3)/1)+1=5,故输出也为5×5.

4.多通道卷积计算过程
单通道卷积计算以上面的计算过程一样,但以彩色图像为例,包含三个通道,那它是怎么进行卷积计算的呢?
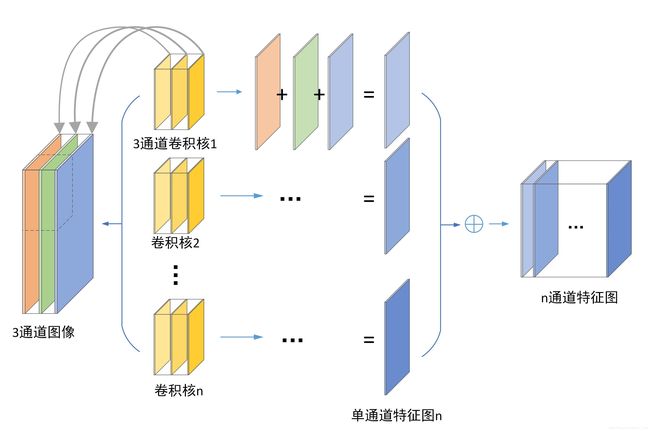
首先多通道卷积计算的卷积核f的通道数也是和输入图像的通道数是一样的,以下图为例,输入为5 * 5 *3
的RGB图像,经过3*3*3的卷积核的各通道分别进行卷积运算,得到了3*3*3卷积后的结果,再进行依次相同位置相加,得到单通道3*3的最后输出结果,注意:多通道卷积核每一层是不一样的。同样的,在卷积计算过程可以有多个卷积核,每个卷积核同样得到一个单通道3*3的结果,最后汇总到一起,该卷积层的输出通道数就是卷积核的个数。

多核卷积计算过程
2.2 其它层
1. 池化层(pooling)
池化层是CNN的重要组成部分,通过减少卷积层之间的连接,降低运算复杂程度,池化层的操作很简单,就想相当于是合并,我们输入一个过滤器的大小,与卷积的操作一样,也是一步一步滑动,但是过滤器覆盖的区域进行合并,只保留一个值。 合并的方式也有很多种,例如我们常用的两种取最大值maxpooling,取平均值avgpooling
池化层的输出大小公式也与卷积层一样,由于没有进行填充,所以p=0,可以简化为 n − f s + 1 \frac{n-f}{s} +1 sn−f+1
2. dropout层
dropout是2014年 Hinton 提出防止过拟合而采用的trick,增强了模型的泛化能力 Dropout(随机失活)是指在深度学习网络的训练过程中,按照一定的概率将一部分神经网络单元暂时从网络中丢弃,相当于从原始的网络中找到一个更瘦的网络,说的通俗一点,就是随机将一部分网络的传播掐断,听起来好像不靠谱,但是通过实际测试效果非常好。
3. 全连接层(FC)
全链接层一般是作为最后的输出层使用,卷积的作用是提取图像的特征,最后的全连接层就是要通过这些特征来进行计算,输出我们所要的结果了,无论是分类,还是回归。

3.经典的网络模型介绍
3.1 LeNet-5
官方网址:http://yann.lecun.com/exdb/lenet/index.html
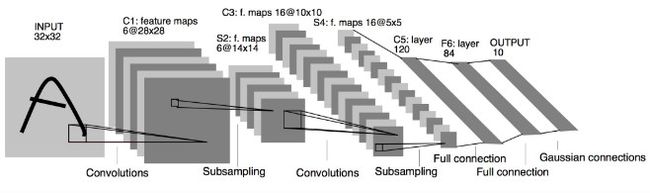
输入:图像Size为32*32,单通道。这要比mnist数据库中最大的字母(28*28)还大。这样做的目的是希望潜在的明显特征,如笔画断续、角点能够出现在最高层特征监测子感受野的中心。
输出:10个类别,分别为0-9数字的概率
- C1层是一个卷积层,有6个卷积核(提取6种局部特征),核大小为
5 * 5 - S2 层是池化(pooling)层,下采样(区域:
2 * 2)降低网络训练参数及模型的过拟合程度。 - C3层是第二个卷积层,使用16个卷积核,核大小:
5 * 5提取特征 - S4层也是一个pooling层,区域:
2*2 - C5层是最后一个卷积层,卷积核大小:
5 * 5卷积核种类:120 - 最后使用全连接层,将C5的120个特征进行分类,最后一层为长度为10,分别为输出0-9的概率
上面网络的代码:
import torch.nn as nn
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
# 1 输入图像通道, 6 输出通道, 5x5 卷积核
self.conv1 = nn.Conv2d(1, 6, 5)
# 6 输入图像通道, 16 输出通道, 5x5 卷积核
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
# 这里论文上写的是conv,官方教程用了线性层
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 最大池化,2*2的窗口滑动
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# 如果滑动窗口是方形,可以直接写一个数
#把所有特征展平,num_flat_features(x)==x.size()[1:].numel()
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # 获取出了batch的其它维度
num_features = 1
for s in size:
num_features *= s
return num_features
#实例化
net = LeNet5()
print(net)
结果:
LeNet5(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
3.2 AlexNet
论文:https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
AlexNet的主要贡献
-
用rectified linear units(ReLU)得到非线性;
-
使用 dropout 技巧在训练期间有选择性地忽略单个神经元,来减缓模型的过拟合;
-
重叠最大池,避免平均池的平均效果;
-
使用 GPU NVIDIA GTX 580 可以减少训练时间

AlexNet只有8层,但是它有60M以上的参数总量,Alexnet有一个特殊的计算层,LRN层,做的事是对当前层的输出结果做平滑处理, Alexnet的每一阶段(含一次卷积主要计算的算作一层)可以分为8层。具体计算过程:

打印网络结构:
import torchvision
model = torchvision.models.alexnet(pretrained=False) #我们不下载预训练权重
print(model)
结果:
AlexNet(
#特征提取
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))
(1): ReLU(inplace)
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU(inplace)
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace)
(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace)
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace)
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
#分类
(classifier): Sequential(
(0): Dropout(p=0.5)
(1): Linear(in_features=9216, out_features=4096, bias=True)
(2): ReLU(inplace)
(3): Dropout(p=0.5)
(4): Linear(in_features=4096, out_features=4096, bias=True)
(5): ReLU(inplace)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
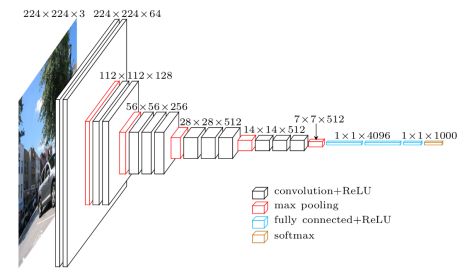
3.3VGG
论文:https://arxiv.org/pdf/1409.1556.pdf
- 每个卷积层中使用更小的 3×3 filters,并将它们组合成卷积序列
- 多个3×3卷积序列可以模拟更大的接收场的效果
- 每次的图像像素缩小一倍,卷积核的数量增加一倍
3.4 GoogLeNet (Inception)
论文:https://arxiv.org/abs/1512.00567
-
使用1×1卷积块来减少特征数量,这通常被称为“瓶颈”,可以减少深层神经网络的计算负担。
-
每个池化层之前,增加 feature maps,增加每一层的宽度来增多特征的组合性。
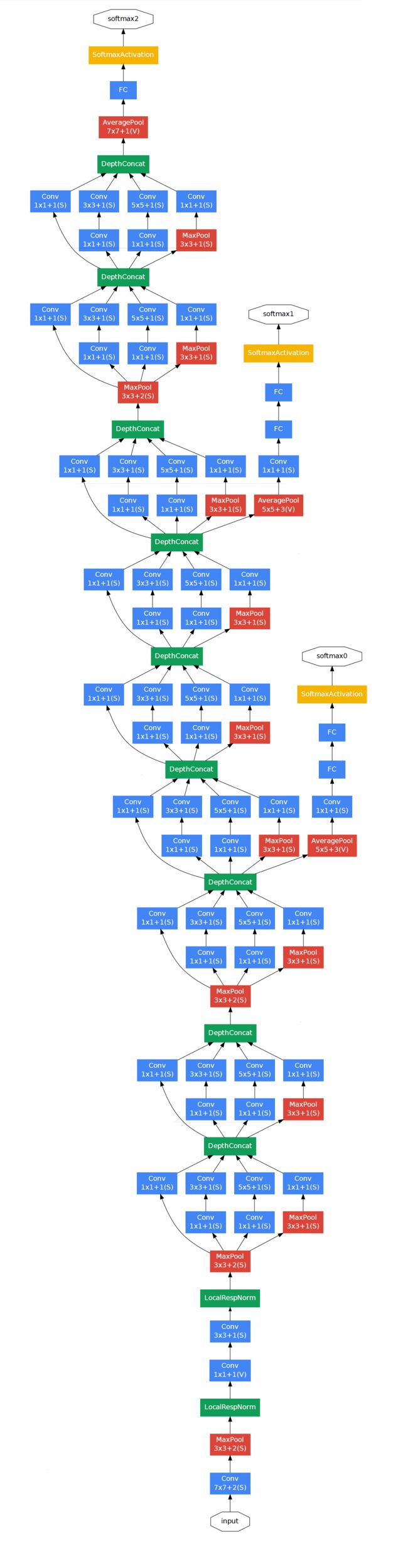
LocalRespNorm(LRN): 局部相应归一化,有利于增加泛化能力,做了平滑处理识别率提高1-2%。
3.5 ResNet
论文:https://arxiv.org/abs/1512.03385
1.退化问题
网络层数增加,但是在训练集上的准确率却饱和甚至下降了。这个不能解释为overfitting,因为overfit应该表现为在训练集上表现更好才对。这个就是网络退化的问题,退化问题说明了深度网络不能很简单地被很好地优化,也就是说越学越差。
2.残差网络的解决办法
深层网络的后面那些层是恒等映射,那么模型就退化为一个浅层网络。让一些层去拟合一个潜在的恒等映射函数H(x) = x,比较困难。如果把网络设计为H(x) = F(x) + x。我们可以转换为学习一个残差函数F(x) = H(x) - x。 只要F(x)=0,就构成了一个恒等映射H(x) = x. 而且,拟合残差肯定更加容易。
如图(其中一种residual):
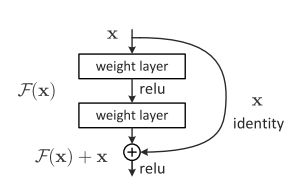
在激活函数前将上一层(或几层)的输出与本层计算的输出相加,将求和的结果输入到激活函数中做为本层的输出。引入残差后的映射对输出的变化更敏感,其实就是看本层相对前几层是否有大的变化,相当于是一个差分放大器的作用。图中的曲线就是残差中的shoutcut,他将前一层的结果直接连接到了本层,也就是俗称的跳连接。
以ResNet18为例:
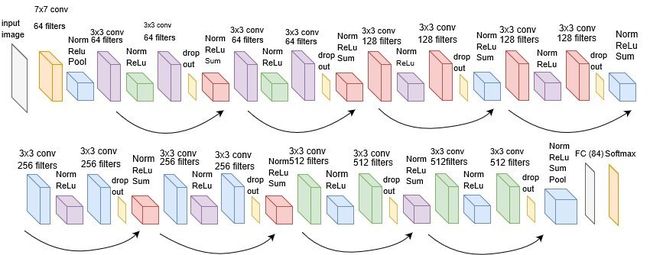
4.网络选择
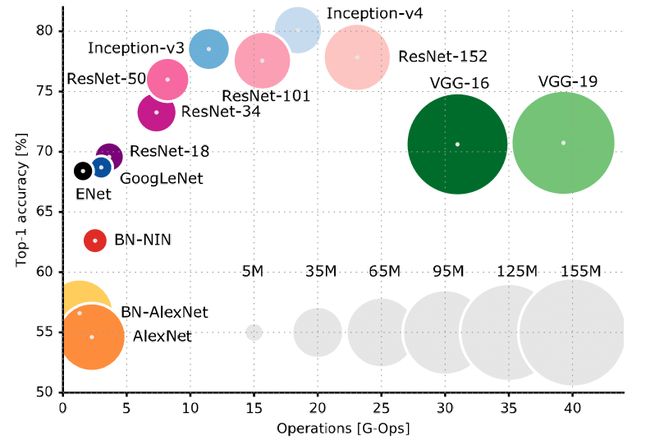
流行CNN 架构的比较,纵轴显示 ImageNet 分类的前 1 的准确度,水平轴显示对图像进行分类所需的操作数,圆圈大小与网络中的参数数量成正比。
参考资料:
https://blog.csdn.net/qq_52302919/article/details/123549586
https://blog.csdn.net/jack__linux/article/details/91357456
https://pytorch.org/tutorials/beginner/blitz/neural_networks_tutorial.html
https://zhuanlan.zhihu.com/p/478197016
https://www.researchgate.net/figure/Comparison-of-popular-CNN-architectures-The-vertical-axis-shows-top-1-accuracy-on_fig2_320084139
欢迎关注公众号【智能建造小硕】(分享计算机编程、人工智能、智能建造、日常学习和科研经验等,欢迎大家关注交流。)