【Easy RL】手写数字识别
ps.这是paddle paddle的一个学习项目所以可能会用到一些内置包。
import paddle
print(paddle.__version__)
数据集:MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
代码:
import paddle
import numpy as np
from paddle.vision.transforms import Normalize
transform = Normalize(mean=[127.5], std=[127.5], data_format='CHW')
# 下载数据集并初始化 DataSet
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
# 模型组网并初始化网络
lenet = paddle.vision.models.LeNet(num_classes=10)
model = paddle.Model(lenet)
# 模型训练的配置准备,准备损失函数,优化器和评价指标
model.prepare(paddle.optimizer.Adam(parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 模型训练
model.fit(train_dataset, epochs=5, batch_size=64, verbose=1)
# 模型评估
model.evaluate(test_dataset, batch_size=64, verbose=1)
# 保存模型
model.save('./output/mnist')
# 加载模型
model.load('output/mnist')
# 从测试集中取出一张图片
img, label = test_dataset[0]
# 将图片shape从1*28*28变为1*1*28*28,增加一个batch维度,以匹配模型输入格式要求
img_batch = np.expand_dims(img.astype('float32'), axis=0)
# 执行推理并打印结果,此处predict_batch返回的是一个list,取出其中数据获得预测结果
out = model.predict_batch(img_batch)[0]
pred_label = out.argmax()
print('true label: {}, pred label: {}'.format(label[0], pred_label))
# 可视化图片
from matplotlib import pyplot as plt
plt.imshow(img[0])
模型组网【不是很明白是什么意思w】
LeNet 模型包含 2个Conv2D 卷积层、2个ReLU 激活层、2个MaxPool2D 池化层以及3个Linear 全连接层,这些层通过堆叠形成了 LeNet 模型,对应网络结构如下图所示。
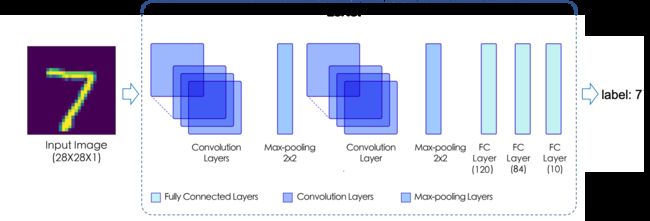
方式一:使用内置模型paddle.vision.models.*
方式二:自定义模型组网
线性结构组网:paddle.nn.Sequential ( Sublayer1, Sublayer2, ..., SublayerN)
subclass组网:paddle.nn.Layer{_init_
{forward
模型训练与评估
主要代码拆分,便于理解
模型训练
步骤:
-
加载训练数据集、声明模型、设置模型实例为
train模式 -
设置优化器、损失函数与各个超参数
-
设置模型训练的二层循环嵌套,并在内层循环嵌套中设置如下内容
-
从数据读取器 DataLoader 获取一批次训练数据
-
执行一次预测,即经过模型计算获得输入数据的预测值
-
计算预测值与数据集标签的损失
-
计算预测值与数据集标签的准确率
-
将损失进行反向传播
-
打印模型的轮数、批次、损失值、准确率等信息
-
执行一次优化器步骤,即按照选择的优化算法,根据当前批次数据的梯度更新传入优化器的参数
-
将优化器的梯度进行清零
-
# dataset与mnist的定义与使用高层API的内容一致
# 用 DataLoader 实现数据加载
train_loader = paddle.io.DataLoader(train_dataset, batch_size=64, shuffle=True)
# 将mnist模型及其所有子层设置为训练模式。这只会影响某些模块,如Dropout和BatchNorm。
mnist.train()
# 设置迭代次数
epochs = 5
# 设置优化器
optim = paddle.optimizer.Adam(parameters=mnist.parameters())
# 设置损失函数
loss_fn = paddle.nn.CrossEntropyLoss()
for epoch in range(epochs):
for batch_id, data in enumerate(train_loader()):
x_data = data[0] # 训练数据
y_data = data[1] # 训练数据标签
predicts = mnist(x_data) # 预测结果
# 计算损失 等价于 prepare 中loss的设置
loss = loss_fn(predicts, y_data)
# 计算准确率 等价于 prepare 中metrics的设置
acc = paddle.metric.accuracy(predicts, y_data)
# 下面的反向传播、打印训练信息、更新参数、梯度清零都被封装到 Model.fit() 中
# 反向传播
loss.backward()
if (batch_id+1) % 900 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id+1, loss.numpy(), acc.numpy()))
# 更新参数
optim.step()
# 梯度清零
optim.clear_grad()
模型评估
# 加载测试数据集
test_loader = paddle.io.DataLoader(test_dataset, batch_size=64, drop_last=True)
# 设置损失函数
loss_fn = paddle.nn.CrossEntropyLoss()
# 将该模型及其所有子层设置为预测模式。这只会影响某些模块,如Dropout和BatchNorm
mnist.eval()
# 禁用动态图梯度计算
for batch_id, data in enumerate(test_loader()):
x_data = data[0] # 测试数据
y_data = data[1] # 测试数据标签
predicts = mnist(x_data) # 预测结果
# 计算损失与精度
loss = loss_fn(predicts, y_data)
acc = paddle.metric.accuracy(predicts, y_data)
# 打印信息
if (batch_id+1) % 30 == 0:
print("batch_id: {}, loss is: {}, acc is: {}".format(batch_id+1, loss.numpy(), acc.numpy()))
模型推理
-
加载待执行推理的测试数据,并将模型设置为
eval模式 -
读取测试数据并获得预测结果
-
对预测结果进行后处理
# 加载测试数据集
test_loader = paddle.io.DataLoader(test_dataset, batch_size=64, drop_last=True)
# 将该模型及其所有子层设置为预测模式
mnist.eval()
for batch_id, data in enumerate(test_loader()):
# 取出测试数据
x_data = data[0]
# 获取预测结果
predicts = mnist(x_data)
print("predict finished")
# 从测试集中取出一组数据
img, label = test_loader().next()
# 执行推理并打印结果
pred_label = mnist(img)[0].argmax()
print('true label: {}, pred label: {}'.format(label[0].item(), pred_label[0].item()))
# 可视化图片
from matplotlib import pyplot as plt
plt.imshow(img[0][0])