JSON 字符串转换为 JavaScript 对象

JSON.parse 将一个 JSON 字符串转换为 JavaScript 对象。
JSON.parse('{"hello":"\world"}')
以上代码输出:
{
hello: "world"
}
是一个 JavaScript 对象,但是仔细观察会发现,"\world" 变成了 "world"。
那么我们继续运行如下代码:
JSON.parse('{"hello":"\\world"}')
出抛出异常:
VM376:1 Uncaught SyntaxError: Unexpected token w in JSON at position 11
at JSON.parse ()
at:1:6
Unexpected token w。
好奇心不死,继续试,3 个反斜杠:
JSON.parse('{"hello":"\\\world"}')
结果是:
VM16590:1 Uncaught SyntaxError: Unexpected token w in JSON at position 11
at JSON.parse ()
at:1:6
继续,4 个反斜杠:
JSON.parse('{"hello":"\\\\world"}')
结果正常:
{
hello: "\world"
}
- 1个,"world"
- 2个,Error
- 3个,Error
- 4个,"\world"
- 5个,"\world"
- 6个,Error
- 7个,Error
- 8个,"\\world"
- 。。。
我们换个思路,把 JSON.parse 去掉,只输出 JavaScript 字符串:
> 'hello' "hello" > '\hello' "hello" > '\\hello' "\hello" > '\\\hello' "\hello" > '\\\\hello' "\\hello"
问题大概找到了。
把上面的规则带入到之前的 JSON.parse 代码,问题就解决了。
我们看看 JSON 的字符串解析规则:

根据这个规则,我们解析一下 "\hello",第 1 个字符是反斜杠(\),所以在引号后面走最下面的分支(红线标注):
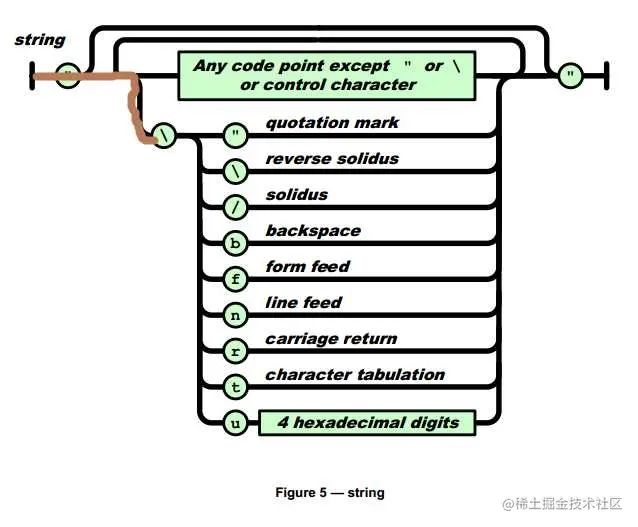
第 2 个字符是 h,但是反斜杠后面只有 9 条路,这个不属于任何一条路,所以这个是个非法字符。
不只是 JSON,在很多语言中都会抛出类似 Error:(7, 27) Illegal escape: '\h' 的错误。
但是不知道为什么 JavaScript 偏偏可以解析这个非法转义字符,而解决方式也很暴力:直接忽略。
在 es 规范我没有找到具体的章节。去看看 V8 是怎么解析的吧。
引擎读取 JavaScript 源码后首先进行词法分析,文件 /src/parsing/scanner.cc 的功能是读取源码并解析(当前最新版 6.4.286)。
找到 Scanner::Scan() 函数关键代码:
case '"': case '\'': token = ScanString(); break;
是一个很长的 switch 语句:如果遇到双引号(")、单引号(')则调用 ScanString() 函数。
简单解释下:以上代码是 C++ 代码,在 C++ 中单引号是字符,双引号是字符串。所以表示字符时,双引号不需要转义,但是单引号需要转义;而表示字符串时,正好相反。此处的 C++ 转义并不是我们今天要研究的转义。
ScanString() 函数
在 ScanString() 函数中我们也只看重点代码:
while (c0_ != quote && c0_ != kEndOfInput && !IsLineTerminator(c0_)) {
uc32 c = c0_;
Advance();
if (c == '\\') {
if (c0_ == kEndOfInput || !ScanEscape()) {
return Token::ILLEGAL;
}
} else {
AddLiteralChar(c);
}
}
if (c0_ != quote) return Token::ILLEGAL;
literal.Complete();
如果已经到了末尾,或者下 1 个字符是不能转义的字符,则返回 Token::ILLEGAL。那么我们看看 ScanEscape 是不是返回了 false 呢?
templatebool Scanner::ScanEscape() { uc32 c = c0_; Advance (); // Skip escaped newlines. if (!in_template_literal && c0_ != kEndOfInput && IsLineTerminator(c)) { // Allow escaped CR+LF newlines in multiline string literals. if (IsCarriageReturn(c) && IsLineFeed(c0_)) Advance (); return true; } switch (c) { case '\'': // fall through case '"' : // fall through case '\\': break; case 'b' : c = '\b'; break; case 'f' : c = '\f'; break; case 'n' : c = '\n'; break; case 'r' : c = '\r'; break; case 't' : c = '\t'; break; case 'u' : { c = ScanUnicodeEscape (); if (c < 0) return false; break; } case 'v': c = '\v'; break; case 'x': { c = ScanHexNumber (2); if (c < 0) return false; break; } case '0': // Fall through. case '1': // fall through case '2': // fall through case '3': // fall through case '4': // fall through case '5': // fall through case '6': // fall through case '7': c = ScanOctalEscape (c, 2); break; } // Other escaped characters are interpreted as their non-escaped version. AddLiteralChar(c); return true; }
这个函数只有 2 处返回了 false。
1、如果转义字符后面是 u,u 后面不是 Unicode 字符时,返回 false
2、如果转义字符后面是 x,x 后面不是十六进制数字时,返回 false
也就是说:'\u'、'\uhello'、'\u1'、'\x'、'\xx' 都抛出异常。
Uncaught SyntaxError: Invalid Unicode escape sequence
或
Uncaught SyntaxError: Invalid hexadecimal escape sequence
而其它非转义字符,都直接执行了后面的代码:
AddLiteralChar(c); return true;
前面的注释也说明了这一点:
Other escaped characters are interpreted as their non-escaped version.
其他转义字符被解释为对应的非转义版本。
综上,问题的根源就是 JavaScript 和 JSON 对转义字符的处理方式不同,导致了难以发现的 bug。JSON 遇到不能转义的字符直接抛出异常,而 JavaScript 遇到不能转义的字符直接解释为对应的非转义版本。
以上就是JavaScript 转义字符JSON parse错误研究的详细内容,更多关于JavaScript JSON parse错误的资料请关注脚本之家其它相关文章!