语义分割--Efficient and Robust Deep Networks for Semantic Segmentation
Efficient and Robust Deep Networks for Semantic Segmentation
Code: https://lmb.informatik.uni-freiburg.de/Publications/2017/OB17a/
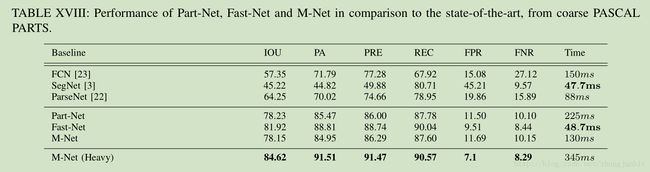
在 Up-Convolutional Networks 的基础上,提出了 Part-Net,Fast-Net,M-Net。 三个网络的侧重点不一样。
Part-Net 主要解决人体部件分割问题
Fast-Net 的特点主要是速度快,可以在移动GPU上运行
M-Net 通过多尺度融合达到网络的最大性能
A. 3.1 Part-Net
专门用于得到 highly accurate human body part segmentation,网络主要改进的地方在: refinement procedure and the feature map dropout module
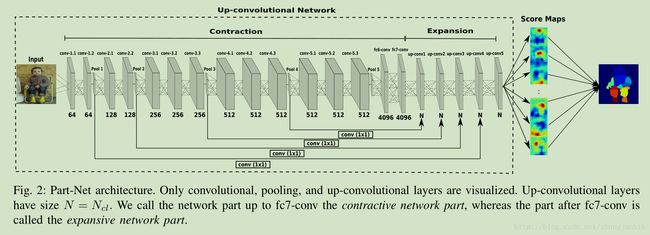
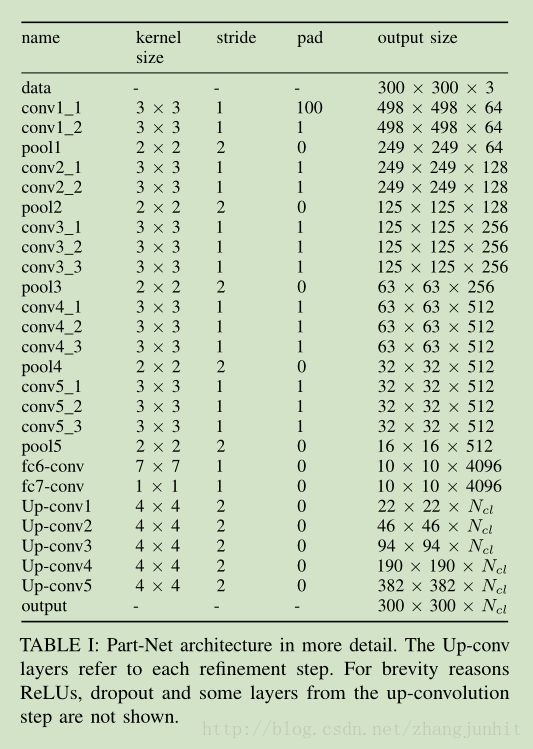
网络的前半部分参数初始化使用 VGG分类网络参数,这样可以节省训练时间
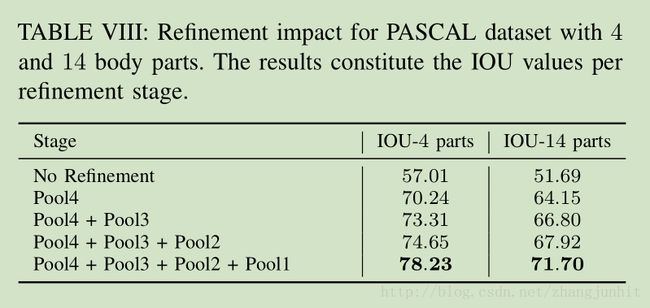
这里采用了与 FCN 不同的 refinement architecture
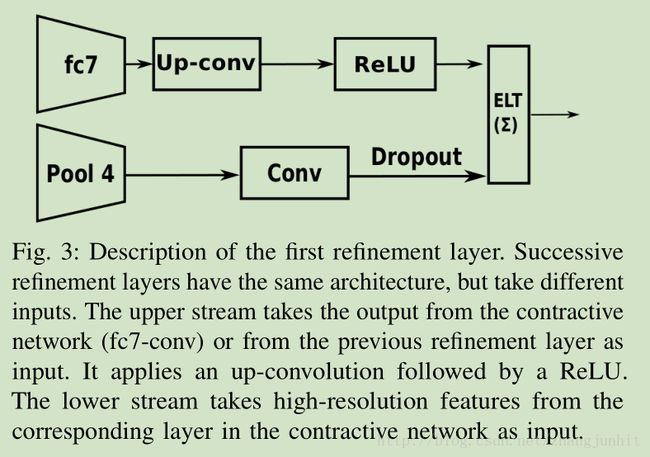
1) FCN 中只有三层的refinement:32s-16s-8s,我们这里有 5层的 refinement 32s-16s-8s-4s-2s
2) 加了一个 dropout
The feature map from the contracting network part is fed into a convolutional layer followed by dropout to improve the robustness to over-fitting
3) 针对人体部件分割,加入 Feature map dropout
Feature map dropout performs a standard Bernoulli trial per output feature during training, yet propagates the dropout value across the entire feature map
B. 3.2 Fast-Net
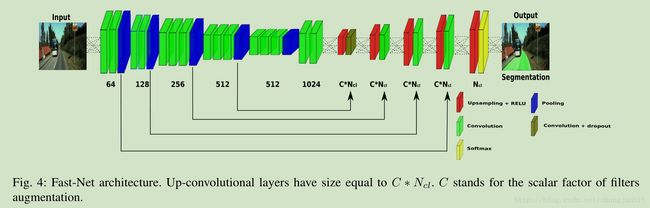

我们做的主要改进在一下几个方面:
1)Parameter reduction: FCN 在特征提取阶段使用了 VGG16 作为基础,这个网络有4096个 7*7 大小的滤波器,这个大尺寸滤波器计算量比较大。 这里我们将 FC-conv 的滤波器数量从 4096 降低到 1024, 滤波器尺寸由 7*7 变为 3*3, 这样网络的参数减少一些,计算量也相应降低,当然精度有所下降,我们在网络的其他地方来提高精度。
2) New refinement to improve system accuracy: 这里主要是参考 U-Net 设计思想,增加了网络放大层的宽度, we increase the width of the up-convolutional side of the network。 Previously our network has a 1 − to − 1 mapping, each refinement has the same number of filters and classes ( N_cl ).
C. 3.3 M-Net

Incorporating low resolution features to a high resolution network makes M-Net more robust towards false positive detections
D. 3.4 Data Augmentation
• Scaling: Scale the image by a factor from 0.7 and 1.4
• Rotation: Rotate the image by an angle of up to 30 degrees
• Color: Add a value between −0.1 and 0.1 to the hue channel of the HSV representation
对于人体部件分割,所有的 augmentation transformations 都是有正作用的,但是对于道路分割, rotation and cropping transformations 没有被使用
E. 3.5 Network Training
M-Net 没有使用 VGG网络来初始化参数,其他的网络都用 VGG来初始化
训练采用了分阶段进行,每个阶段在一个 Titan X GPU 使用了一天时间,总共使用了5天训练了整个网络。 M-Nets 使用了 10天
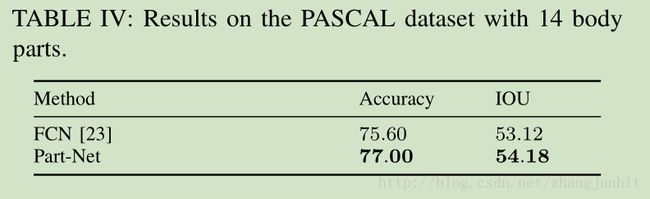
实验结果:

没有使用 data augmentation
B. 4.2 Effect of Data Augmentation



C. 4.3 Effect of Layer Refinement