基于深度学习的三维人体姿态估计
目录
一、技术背景
1.1 人体姿态估计
1.2 三维人体重建
1.4 构建多人场景研究情况
二. 技术方法
2.1 基础架构
2.2 重叠loss
2.3 深度顺序感知loss
四.存在的问题与未来研究热点
4.1 本实验方法存在的问题
4.2 未来研究热点
参考文献:
一、技术背景
1.1 人体姿态估计
人体姿态估计(human pose estimation, HPE)已经发展了几十年,一直围绕着从传感器的输入来构建人体姿态。在摄影领域尤为明显,一些基于视觉的人体姿态估计技术就经常被用于摄影技术上。随着深层级神经网络技术的发展,深度学习在图片分类,目标检测,语义分割等方面有着越来越好的表现。人体姿态估计也因为深度学习的运用得到了飞速发展,包括具有很强估计能力的神经网络模型,更加丰富的数据集以及构建愈加完善的人体模型。人体姿态估计的范围及其方法较为广泛,比如电影和动画的人体动作捕捉技术、虚拟现实技术、人机交互技术(humancomputer interaction, HCI)、视频监控和动作识别技术、医疗辅助相关技术、自动驾驶以及体育运动分析等。人体姿态估计的主要难点和挑战在于 1)灵活的身体拥有复杂而独立的关节以及高自由度的四肢容易造成自遮蔽(self-occlusions)或重叠;2)多样的外形包括不同的服饰和自相似的地方;3)复杂的环境导致前景遮蔽现象或者人体部位的相似性以及不同的视角造成的差异。当然人体姿态估计也涉及二维和三维人体模型的区别,不过本文主要讨论的是三维人体模型的重建。
1.2 三维人体重建
三维人体姿态估计比二维人体姿态估计更具有挑战性,因为三维人体模型还需要去预测身体关节的深度信息,但对于计算机来说,由于投射投影,3D场景投射到2D空间里面,就损失了很多的信息,最明显的就是深度信息,同时诸如光照,材料特性、朝向、距离等信息都反映成唯一的测量值——灰度,因而要从这唯一的测量值恢复上述一个或几个反映物体本质特征的参数是一个解不唯一的问题。观测数据不足以约束问题的解,因此要利用先验知识或引入合适约束。所以从单张图像去理解图像场景的3D结构就很困难了。
以前的3D模型重构,一般都是通过两个(模拟人的双眼)或者多个摄像头来获取图像,再配准的。当然,也有研究单张图像的,但是都会对场景做很多的假设,例如由明暗恢复形状shape from shading(SFS)(利用单幅图像中物体表面明暗变化恢复其表面各点的法向方向进而求得其相对高度),运用光学辅助等,使用有很大的局限性。现在更多地是利用可以探测深度的摄像头,例如Kinect,一个色彩感知摄像头,另一个红外摄像头用于测图像深度,即可以测量场景中物体到相机的距离,来获取更多的用于重建三维人体模型的信息。
而随着深度学习在3D人体分析任务取得了巨大的进展,例如在3D关键点估计、3D形状重建、全身3D姿态和形状恢复方面取得了令人印象深刻的效果,估计了更详细和更有表现力的重建。然而,随着对场景和在场景中互动的人的理解越来越全面,从单个图像中连贯地重建多人的3D图像成为重建的关键。关于多人姿势估计,有自上而下的方法。它首先检测场景中的所有身体关节,然后对它们进行分组,即将检测到的关节分配给适当的人。
当在3D中推理多人的姿势时,问题比在2D中三维重建更复杂。例如,重建的人可能在3D空间中相互重叠,或者在深度的估计值与实际不一致。这意味着,对图像进行多人三维重建不仅仅是为每个人单独预测一个合理的3D姿势,也要估计场景中所有人的连贯重建,考虑模型间的整体关系。整体场景的一致性成为这项工作的主要目标。本文讨论的方法采用了典型的自上而下的模型,目标是训练一个深度网络,学习估计场景中所有人的连贯重建。
1.3 单幅图片单人三维人体重建
对于单人三维姿态估计,一般地都是在图片中形成人体的包围盒,这样就可以减少不必要的人物的检测过程。单人三维姿态估计包含无人体模型的重建方法和基于人体模型的重建方法。无人体模型的方法不采用人体模型作为最终的估计目标或者中间线索。大致的方法类型分为两种:1)直接映射图像到3D姿态,2)从二维位姿估计方法中,根据中间预测的二维位姿估计深度。基于模型的方法通常使用参数化的身体模型或模板来从图像中估计人体的姿态和形状。这些模型通常由单独的身体姿势和形状组件来进行参数化设定。最近一些研究的人体模型是根据对不同人的多次扫描得到的,或者结合一些不同的身体模型得到。比如从图片中获取3D参数的SMPL的身体模型,就可以用来实现单幅图片单人三维人体重建。本文主要讨论的单人三维人体重建和多人三维人体重建都是基于人体模型的三维人体重建。
Nikos Kolotouros等人[1]提出的基于卷积网格回归的单幅图像人体形状重建方法,对单幅图片重建单个模型效果较好,但对单幅图片重建多个人不理想。它用了一个更加混合的学习方式,保留了SMPL的模板mesh,但是并没有直接回归SMPL的模型参数,而是通过回归模板mesh上的各个点坐标来达到生成想要的人体模型的效果。考虑到人体需要有很多的点来表示,所以用GCN网络。具体从image到mesh的变换学习过程如下图1所示

图1. 从image到mesh的变换学习过程
该方法的主要工作流程:
- 给定一张图,用任何一个经典的2D CNN都可以提出到低维的图像特征;
- 将低纬度的图像特征嵌入到template mesh的各个顶点中;
- 这样每个顶点都有其坐标位置及对应的feature vector;
- 通过GCN层来不断迭代进行优化;最后得到回归后的3D mesh的各个顶点坐标,对应图中的output mesh。
另外的一篇论文中提出了一个从图像中预测SMPL模型的shape和pose参数的框架,称之为NBF(Neural Body Fitting)[2]。NBF将3D模型和CNN相结合,利用了语义分割(semantic segmentation)技术,可以进行细粒度的全面的模型fitting。同时提供3D和2D的监督方法,可以根据可用数据集的情况灵活训练。

图2. NBF网络框架
如图2,NBF网络框架训练的两个阶段:
(1)使用CNN,从原始图像中得到segmentation图像;
(2)使用CNN,从segmentation图像中预测shape和pose参数,生成3D/2D关节点坐标,进行优化。
上述方法进行三维人体重建对人体位姿的预测是基于SMPL的方法,Qiuhong Ke等人[3]提出可以利用视频的时空编码图对人体进行三维重建。而在此之前的构建的时空编码图都是以直接排列关节点的坐标来构建。这种时空编码图虽然能够通过归一化来克服平移不变性(translation)和尺度不变性(scale),但是始终存在一个缺陷:就是它始终对于旋转(rotation)是敏感的。这篇文章为了解决这个问题,不再直接使用关节点的坐标,而是根据关节点计算平移、尺度、旋转不变性的特征,基于该特征构建时空编码图,从而达到目的。时空编码图网络结构如图3。

图3. 时空编码图网络结构
整个网络结构如图3所示,每一个部分都可以计算出一张CD时空编码图和NM时空编码图,一共5个部分,总共可以计算出10张图,将这些图stack输入到卷积神经网络中即可得到最终的结果。
1.4 构建多人场景研究情况
多人位姿估计通常有Bottom-up、Top-down这两种方法。其中B方法是从人体关节到组建关节,但缺点是基于关节进行其他信息的拓展抽象且困难;而T方法是从人到每个人的位姿估计,通过结合SOTA的人体检测、位姿估计方法可以在2D上达到很好的效果。但传统的T方法在3D中存在肢体渗透、遮挡、深度顺序的协调不一致问题。
经过上述文献调研和分析,我们参考文献[4]实现一个从单一图像中连贯地重建多人模型。主要的方法是训练一个可学习的深度网络,得到协调的3D场景人体重建结果。利用基于自上而下的框架,结合上述文件中单人建模所使用的SMPL参数化对人体进行建模。同时,为了处理人物之间位姿的重叠,以及减少人物间深度的不一致的问题,构建了两个新的loss函数:
(1)距离场域冲突loss(distance field-based collision loss,针对人体重叠);
(2)深度顺序感知loss(depth ordering-aware loss,遮挡推断、优化人体深度排序,提供深度监督信号)。
二. 技术方法
本文选取了近期较新的网络模型方法来做探讨,从基础架构、重叠loss、深度顺序感知loss来阐述。基础架构的整体框架结构类似于R-CNN框架,使用的是最类似于Mask R-CNN迭代的结构。
为了改进对非碰撞人的预测,引入重叠loss。回归网络可以预测重叠,但对重叠产生的碰撞不做处理,引入了惩罚被重构人之间相互重叠的损失。
在多人三维重建中,除了相互重叠外,另一个常见的问题是难以估计人的深度顺序。如果我们能够访问像素级的深度标注,解决这个深度排序问题就很容易了。但显然很难获得这种标注。我们这里的关键思想是,引入深度顺序感知loss,利用经常可用的实例分段标注,可以在大规模COCO数据集中实现。
2.1 基础架构
本文网络的基础架构主要由Backbone,RPN,Heads组成,Backbone用的是残差神经网络ResNet50, RPN (Region Proposal Network)用于生成候选区域(Region Proposal), 最后heads用来对候选框进行细分操作。网络训练是一种端到端的方式进行。R-CNN基础架构图如下图4。

图4. 架构图
具体实现步骤:
(1)输入一幅图片到预训练好的CNN中获得对应的feature map;
(2)RPN对feature map中的每一点设定多个anchor,从而获得多个候选框,RPN对候选框进行二值分类和B Box回归,过滤掉一部分候选框;
(3)进行ROI Align操作得到固定大小尺寸的feature map;
(4)最后对候选框进行分类、B Box回归、MASK生成和SMPL参数回归。
功能结构图如图5.

图5. 功能结构图
作者受文献[5]的启发,在模型训练过程中引入SMPL网络,训练得到人体的姿态参数以及相机的位置等信息。利用SMPL参数对场景中的人物在深度上的遮挡关系和相互穿透关系进行推理,从而将两种新的损失重叠损失和深度顺序损失,作为约束条件合并到三维重建中。
SMPL的训练过程如下:输入图片后,由CNN获取图片的特征,在RPN生成的每个BBOX中对SMPL中的姿势和形态参数以及相机参数进行迭代回归,根据每个BBOX在图片中的位置,更新相机参数。根据最后得到的SMPL参数生成三维人体模型并将人体模型再次投影到二维平面得到关节点。使用鉴别器,根据关节点的角度信息,判断三维参数在姿势和体态上是否合理,是否是真实的人体。
2.2 重叠loss
与一般的一个静态的场景和一个人的相比,本文使用的方法构建的场景中包括了多个人,并且可以在动态场景下通过训练生成多人3D模型形象。引入了一个loss,惩罚了重建人群之间的相互重叠。对N人场景重叠loss定义如下:

ρ是Geman-McClure鲁棒误差函数。Pij是非负的,如果人物i和人物j之间没有碰撞,它的值为0;而随着人物j的表面顶点与人物i的距离的增加,Pij也随之增加。Pij是重叠的冲突惩罚函数,定义如下:

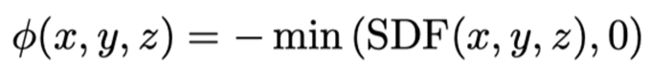
其中Signed Distance Field(SDF),即有向距离场。表示空间中某⼀点到最近平⾯的距离,在物体内部为负,在物体外部为正。如果j中的一点在i的外部,则惩罚为0;如果这⼀点在i的内部,惩罚为该点的距离场。
理论上,Pij本身可以作为避免重叠的优化目标。但是在人物形象的建模过程中容易造成梯度过大,从而使得在过度重叠的情况下网络模型的训练不稳定。因此结合Geman-McClure鲁棒误差函数提出Lp(即重叠loss函数),来保持网络模型训练具有较好的鲁棒性。
2.3 深度顺序感知loss
在多人三维重建中,除了互穿之外,另一个常见的问题是,人物模型的深度估计错误。这个问题在人们在二维图像平面上重叠的情况下更为明显。
本文方法使用像素级的深度注释,解决深度排序问题。实现思路是利用易获得的实例分割标注(大规模COCO数据集),在图像平面上绘制所有重建人体的网格,可以显示每个像素对应的人,并在与已标注的实例注释一致的基础上进行优化。
直观的方法是利用可微渲染器the Neural Mesh Renderer (NMR),惩罚实际实例分割与渲染网格产生的分割之间的不一致。但是传统的NMR的error只能反向传播到可视网格顶点。这就存在一些问题,若存在深度顺序error,该方法不能使不可视的网格移动到离相机更近的距离,导致破坏训练(数值不稳定)。
为了改进这个问题,本文方法除了渲染场景语义分割,还通过NMR分别渲染每个人的深度图,完整深度loss函数如下:
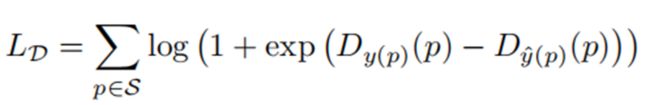
同时,本文方法将上述loss反向传播到重叠双方的人体网格(最终至模型参数),而不是像传统的可微分渲染器那样,只向可见的人反向传播梯度。这促进了损失(和更新)具有更大的对称性,使这种损失变得更加实用。
四.存在的问题与未来研究热点
4.1 本实验方法存在的问题
因为该方法是对单幅图片进行三维人体建模,在处理视频数据时,也只是对单帧进行绘制,没有考虑到帧与帧之间的连续性,导致重建出来的视频在人物模型的数量和位置上不稳定。之后可以通过引入上下文的关系与时序来改进这一问题。
4.2 未来研究热点
可以看到,使用深度学习进行基于图像的三维重建取得了很好的效果。然而这一课题仍在初级阶段,有待进一步发展,未来针对人体三维重建的研究,有以下发展趋势。
训练数据问题:深度学习技术的成功在很大程度上取决于训练数据的可用性,不幸的是,与用于分类和识别等任务的训练数据集相比,包含图像及其3D注释的公开数据集的大小很小。二维监督技术被用来解决缺乏三维训练数据的问题。然而,它们中的许多依赖于基于轮廓的监督,因此只能重建视觉外壳。因此,期望在未来看到更多的论文提出新的大规模数据集、利用各种视觉线索的新的弱监督和无监督方法,以及新的领域适应技术,其中使用来自某个领域的数据训练的网络(例如,合成渲染图像)适应新的领域。研究能够缩小真实图像和综合渲染图像之间差距的渲染技术,可能有助于解决训练数据问题。
3D视频:本次实验研究的是一幅或多幅图像的三维重建,但没有时间相关性,而人们对三维视频越来越感兴趣,即对连续帧具有时间相关性的整个视频流进行三维重建。一方面,帧序列的可用性可以改善重建,因为可以利用后续帧中可用的附加信息来消除歧义并细化当前帧处的重建。另一方面,重建的图像在帧间应该平滑一致。
走向全三维场景解析:最后,最终目标是能够从一个或多个图像中语义分析完整的3D场景。这需要联合检测、识别和重建。它还需要捕获和建模对象之间和对象部分之间的空间关系和交互。虽然在过去有一些尝试来解决这个问题,但它们大多局限于室内场景,对组成场景的对象的几何和位置有很强的假设。
参考文献:
[1]Kolotouros N , Pavlakos G , Daniilidis K . Convolutional Mesh Regression for Single-Image Human Shape Reconstruction[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2019.
[2]M Omran,C Lassner,G Pons-Moll,P Gehler,B Schiele ,et al.Neural Body Fitting: Unifying Deep Learning and Model-Based Human Pose and Shape Estimation
[3]Ke Q , An S , Bennamoun M , et al. SkeletonNet: Mining Deep Part Features for 3-D Action Recognition[J]. IEEE Signal Processing Letters, 2017, 24(6):731-735.
[4]Wen Jiang, Nikos Kolotouros ,et al.Coherent Reconstruction of Multiple Humans from a Single Image[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2020.
[5]Han X F , Laga H , Bennamoun M . Image-based 3D Object Reconstruction: State-of-the-Art and Trends in the Deep Learning Era[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019.
[6]Y Chen, Y Tian, He M . Monocular Human Pose Estimation: A Survey of Deep Learning-based Methods[J]. Computer Vision and Image Understanding, 192.