基于深度学习的图像分割算法
基于keras的深度学习实现语义图像分割
像素级的分割是计算机视觉研究的热点问题,图像分割的任务是对图像中的每个像素进行分类。在这篇文章中,我们将讨论如何使用深度卷积神经网络来做图像分割。我们将从数据准备到模型搭建完成一个keras的语义图像分割任务。
文章目录
- 基于keras的深度学习实现语义图像分割
- 前言
- 一、什么是语义分割?
- 二、语义分割的应用场景
-
- 1.医学图像
- 2.无人驾驶汽车
- 3.卫星图像数据分析
- 三、用于分割的卷积神经网络
- 四、Skip connections
- 五、Transfer learning
- 六、Loss function
- 七、Implementation
-
-
- 安装`pip install keras-segmentation`
- Dataset
- Data augmentation
- Building the model
- Choosing the model
-
-
- ResNet
- VGG-16
- MobileNet
- Custom CNN
- FCN
- SegNet
- UNet
- PSPNet
-
- Choosing the input size
- Training
-
- 总结
前言
深度学习和卷积神经网络(CNN)在计算机视觉领域已经非常普遍。网络神经网络广泛应用于图像分类、目标检测、图像生成等计算机视觉任务。像所有其他计算机视觉任务一样,深度学习已经超越了其他图像分割方法
一、什么是语义分割?
语义图像分割是将图像中的每个像素从一组预定义的类中分类。在下面的示例中,对不同的实体进行了分类:

在上面的例子中,属于床的像素被分类为“床”类,与墙对应的像素被标记为“墙”类。具体地说,我们的目标是通过一幅大小为W x H x 3的图像,生成一个W x H矩阵,其中包含与所有像素相对应的预测类ID。

通常,在一幅有各种实体的图像中,我们想知道哪个像素属于哪个实体,例如在一幅室外图像中,我们可以分割天空、地面、树木、人物等。语义分割不区分同一类别的不同实例。例如,场景中可能有多辆车,但是它们都具有相同的标签。为了进行语义分割,需要对图像有更高层次的理解。算法不仅要计算出目标的存在,还要计算出与目标对应的像素。语义分割是完成场景理解的基本任务之一。
二、语义分割的应用场景
1.医学图像
人体扫描的自动分割可以帮助医生进行诊断。例如,可以训练模型来分割肿瘤

2.无人驾驶汽车
自动驾驶汽车和无人机等自动驾驶车辆可以从语义分割中获益。例如,自动驾驶汽车可以检测可行驶区域

3.卫星图像数据分析
航拍图像可以用来分割不同类型的土地。可实现自动化的土地测绘

三、用于分割的卷积神经网络
通常,卷积神经网络模型的结构包含几个卷积层、非线性激活层、归一化化和池化层。模型最初的层学习低层次的概念,比如边缘和颜色,后来的层学习更高层次的概念,比如不同的对象。在模型的低层,神经元包含图像小区域的信息。而在较高的网络层,神经元包含图像的一个大区域的信息。因此,当我们添加更多的网络层时,图像的尺寸会不断减小,而通道的数量会不断增加。下采样采用池化层实现。对于图像分类的情况,我们需要将图像的空间张量通过卷积层转换为长的向量,通过全连接层来实现,但这也会丢失图像的空间信息。
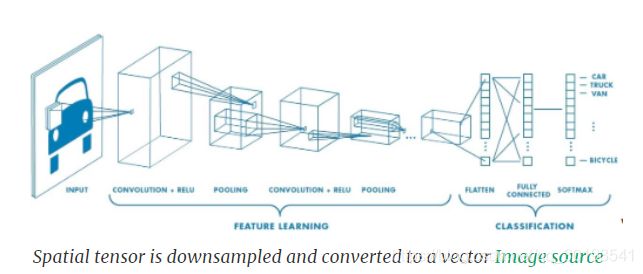
在图像的语义分割中,我们需要保留图像的空间信息,因此网络不采用全连接层,这就是我们称语义分割模型为全卷积网络的原因。卷积层与下采样层相结合产生包含高级信息的低分辨率张量。对于包含高分辨率信息的低分辨率空间张量,我们必须产生高分辨率的分割输出。为了做到这一点,我们增加了更多的卷积层和增加空间张量大小的上采样层。当我们提高分辨率时,我们减少了通道的数量,因为我们回到了低层次的信息。这被称为编码器-解码器结构,向下采样输入的层是编码器的一部分,向上采样的层是解码器的一部分

当对模型进行语义分割训练时,编码器输出一个包含目标及其形状和大小信息的张量。解码器接受此信息并生成分割映射。
四、Skip connections
如果我们只是简单地堆叠编码器和解码器层,可能会丢失底层信息,因此,解码器产生的分割映射的边界可能不准确。为了弥补丢失的信息,我们让解码器获取由编码器层产生的底层特征。这是通过跳过连接来完成的。编码器的中间输出在适当位置加/连接到解码器的中间层作为输入。skip connections为解码器的网络层提供了必要的信息实现了准确的边界预测,这些信息来自编码器的最初几层。
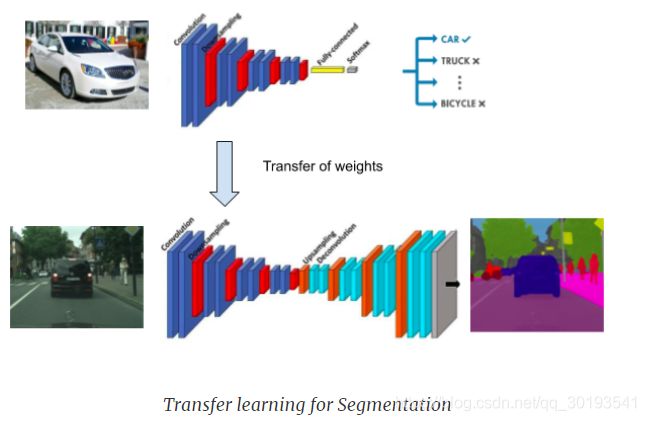
五、Transfer learning
经过训练的用于图像分类的CNN模型包含有意义的信息,这些信息也可以用于分割,我们可以在分割模型的编码器层中重用预训练模型的卷积层
六、Loss function
将网络输出的每个像素与ground truth分割图像中对应的像素进行比较,我们对每个像素应用标准的交叉熵损失。
七、Implementation
我们将使用Keras来构建和训练分割模型
安装pip install keras-segmentation
Dataset
训练分割模型的第一步是准备数据,我们需要输入RGB图像和相应的分割图像。如果您想制作自己的数据集,可以使用labelme或GIMP等工具手动生成ground truth分割掩码。给每个类分配一个唯一的ID。在分割图像中,像素值应该表示对应像素的类ID。这是大多数数据集和keras_segmentation使用的一种常见格式。对于分割映射,不要使用jpg格式,因为jpg是有损的,而且像素值可能会改变。使用bmp或png格式代替。当然,输入图像和分割图像的大小应该是一样的。
生成分割后的图像,将它们放在培训/测试文件夹中。为输入图像和分割图像制作单独的文件夹,输入图像的文件名与对应的分割图像的文件名相同。
请参考下面的格式:
dataset/
train_images/
- img0001.png
- img0002.png
- img0003.png
train_segmentation/
- img0001.png
- img0002.png
- img0003.png
val_images/
- img0004.png
- img0005.png
- img0006.png
val_segmentation/
- img0004.png
- img0005.png
- img0006.png
数据集下载地址:here
Data augmentation
如果训练对的数量较少,结果可能不好,因为模型可能会过度拟合。我们可以通过对图像应用随机变换来增加数据集的大小。我们可以改变输入图像的颜色属性,如色调、饱和度、亮度等。我们还可以应用旋转、缩放和翻转等转换。对于改变像素位置的变换,分割后的图像也应进行同样的变换。Imgaug是一个可用于执行图像增强的工具。可参考下面将随机应用剪裁、翻转和高斯模糊转换的代码片段:
import imgaug as ia
import imgaug.augmenters as iaa
seq = iaa.Sequential([
iaa.Crop(px=(0, 16)), # crop images from each side by 0 to 16px (randomly chosen)
iaa.Fliplr(0.5), # horizontally flip 50% of the images
iaa.GaussianBlur(sigma=(0, 3.0)) # blur images with a sigma of 0 to 3.0
])
def augment_seg( img , seg ):
aug_det = seq.to_deterministic()
image_aug = aug_det.augment_image( img )
segmap = ia.SegmentationMapOnImage( seg , nb_classes=np.max(seg)+1 , shape=img.shape )
segmap_aug = aug_det.augment_segmentation_maps( segmap )
segmap_aug = segmap_aug.get_arr_int()
return image_aug , segmap_aug
代码中aug_det定义了转换的参数,它应用于输入图像img和分割图像seg。
Building the model
使用Keras API定义带有skip connection的分割模型。
首先定义编码器,其中每个模块包含两个卷积层和一个最大池化层,最大池化层将图像的采样降低到原来的2倍。
img_input = Input(shape=(input_height,input_width , 3 ))
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same')(img_input)
conv1 = Dropout(0.2)(conv1)
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv1)
pool1 = MaxPooling2D((2, 2))(conv1)
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same')(pool1)
conv2 = Dropout(0.2)(conv2)
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv2)
pool2 = MaxPooling2D((2, 2))(conv2)
conv1和conv2包含将被解码器使用的编码器输出的中间部分。pool2是编码器的最终输出
然后定义解码器,将编码器的中间层输出与解码器的中间层输出连接起来
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same')(pool2)
conv3 = Dropout(0.2)(conv3)
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv3)
up1 = concatenate([UpSampling2D((2, 2))(conv3), conv2], axis=-1)
conv4 = Conv2D(64, (3, 3), activation='relu', padding='same')(up1)
conv4 = Dropout(0.2)(conv4)
conv4 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv4)
up2 = concatenate([UpSampling2D((2, 2))(conv4), conv1], axis=-1)
conv5 = Conv2D(32, (3, 3), activation='relu', padding='same')(up2)
conv5 = Dropout(0.2)(conv5)
conv5 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv5)
其中conv1与conv4连接,而conv2与conv3连接。为了得到最终的输出,添加与类数目相同的过滤器的卷积
out = Conv2D( n_classes, (1, 1) , padding='same')(conv5)
from keras_segmentation.models.model_utils import get_segmentation_model
model = get_segmentation_model(img_input , out ) # this would build the segmentation model
Choosing the model
语义分割有几种可用的模型。模型架构应该根据用例进行适当的选择,通常,基于深度学习的分割模型建立在一个base CNN网络上。一个标准的模型,如ResNet, VGG或MobileNet通常被选择为基础网络。一些初始层的基础网络在编码器中使用,和分割网络的其余部分是建立在那之上。对于大多数分割模型,任何基网络都可以使用。对于分割模型的选择,我们的首要任务是选择一个合适的基网络。对于许多应用场景,选择在ImageNet上预先训练过的模型是最好的选择。
ResNet
这是微软提出的模型,在2016年ImageNet竞赛中获得了96.4%的准确率。ResNet被用作多个应用的预训练模型。ResNet具有大量的层和剩余连接,使其训练可行
VGG-16
这是牛津大学提出的模型,该模型在2013年ImageNet竞赛中获得了92.7%的精度。与Resnet相比,它有较少的层次,因此它是更快的训练。对于大多数现有的分割基准测试,VGG在准确性方面不如ResNet。在ResNet之前,VGG是大量应用程序中标准的预训练模型。
MobileNet
该模型由谷歌提出,优化后的模型规模小,推理时间快,这非常适合在移动电话和资源受限的设备上运行,由于体积小,模型的精度可能会受到小的影响
Custom CNN
除了使用ImageNet预先训练的模型之外,自定义网络还可以用作基础网络。如果分割应用程序相当简单,则没有必要对ImageNet进行预训练。使用自定义模型的另一个好处是,我们可以根据应用场景自定义它。如果用于分割任务的图像域与ImageNet相似,则ImageNet预训练的模型将是有益的。根据任务输入图像的类型,预训练的模型还可以在其他数据集上进行训练。在选择了基础网络之后,我们必须选择分割模型架构。
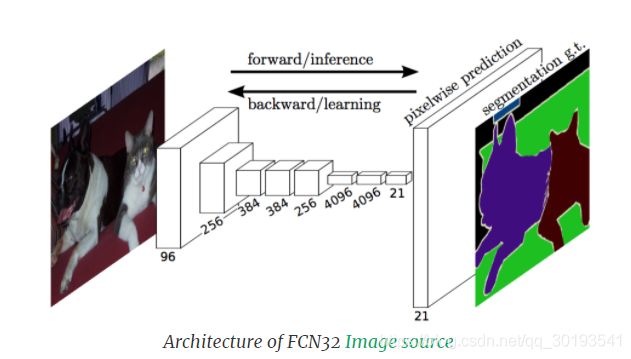
FCN
FCN是最早提出的用于端到端语义分割的模型之一。标准图像分类模型,如VGG和AlexNet,通过FC层1x1卷积转换为全卷积。在FCN,使用转置的卷积进行上采样,不同于使用数学插值的其他方法,三种改型是FCN8、FCN16和FCN32。在FCN8和FCN16中,使用skip connections。
SegNet
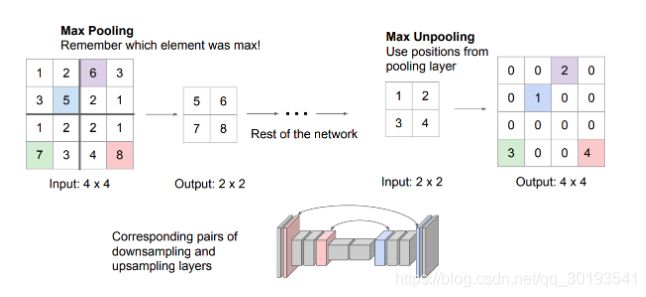
SegNet架构采用编解码器框架,编码器层和解码器层相互对称,解码器层的上采样操作使用对应编码器层的最大池化操作,SegNet没有任何skip connections。与FCN不同,上采样不使用可学习的参数。
UNet
UNet结构采用具有skip connections的编解码器框架,像SegNet一样,编码器层和解码器层是相互对称的。

PSPNet
金字塔场景解析网络被优化以更好地学习场景的全局上下文表示。首先,将图像传递到基础网络得到特征图。将特征图向下采样到不同的尺度,卷积应用于合并的特征映射。然后将所有的特征图向上采样到一个共同的比例尺并连接在一起。最后,使用另一个卷积层来产生最终的分割输出。较小的物体被高分辨率的特征集合很好地捕获,而大的对象是由较小的特征集合捕获的。
对于包含室内和室外场景的图像,首选PSPNet,因为对象通常以不同的大小出现。这里的模型输入尺寸应该相当大,大约500x500左右。对于医学领域的图像,UNet是普遍的选择,因为skip connections,UNet不会遗漏细节。UNet也可用于有小型物体的室内/室外场景。对于具有大尺寸和小数量对象的简单数据集,像FCN或Segnet这样的简单模型就足够了。最好使用具有不同模型输入大小的多个分割模型进行实验。
Choosing the input size
除了选择模型的架构之外,选择模型输入大小也非常重要,如果图像中有大量的物体,输入尺寸要大一些。在某些情况下,如果输入大小很大,模型应该有更多的层来弥补,标准的输入大小在200x200到600x600之间。一个大输入尺寸的模型会消耗更多的GPU内存,也会花费更多的时间来训练。
Training
在准备数据集和构建模型之后,我们必须训练模型。
总结
在这篇文章中,我们讨论了基于深度学习的分割的概念。然后我们讨论了使用的各种流行模型,使用Keras,我们实现了在任何数据集上训练分割模型。我们讨论了如何根据应用场景选择合适的模型
原文