Paddle2.0实现PSPNet进行人体解析(图像分割)
Paddle2.0实现PSPNet进行人体解析(图像分割)
- 项目背景
-
- 概述
- 前言
- PSPNet介绍
-
- 为什么会提出PSPNet ?
- PSPNet 的效果为什么好 ?
- PSPNet 是怎样考虑上下文信息的 ?
- PSPNet 是怎样增大感受野的 ?
- PSPNet - 金字塔模块(Pyramid Pooling)
- PSPNet 的总体结构
- PSPNet - Backbone
- 代码
-
- 引入需要的包
- Pyramid Scene Parsing Network
-
- ConvBNReluLayer
- BottleneckBlock
- Dilated Resnet50
- PSPModule
- PSPNet
- 解压数据集
- 数据处理部分
-
- 将原图和分割图路径保存为 .txt文件
- 自定义数据集类
- MIOU
- 一些常用的函数
- DataLoader
- 模型声明
- Train
- 可视化结果
- 网图测试效果
- 项目总结
源地址.
项目背景
概述
图像的研究和应用中,人们往往对图像中的某些部分感兴趣,这些感兴趣的部分一般对应图像中特定的、具有特殊性质的区域(可以对应单一区域,也可以对应多个区域),称之为目标或前景;而其他部分称为图像的背景。为了辨识和分析目标,需要把目标从一幅图像中孤立出来,这就是图像分割要研究的问题。
图像分割是计算机视觉研究中的一个经典难题,已经成为图像理解领域关注的一个热点,图像分割是图像分析的第一步,是计算机视觉的基础,是图像理解的重要组成部分,同时也是图像处理中最困难的问题之一。所谓图像分割是指根据灰度、彩色、空间纹理、几何形状等特征把图像划分成若干个互不相交的区域,使得这些特征在同一区域内表现出一致性或相似性,而在不同区域间表现出明显的不同。简单的说就是在一副图像中,把目标从背景中分离出来。对于灰度图像来说,区域内部的像素一般具有灰度相似性,而在区域的边界上一般具有灰度不连续性。 关于图像分割技术,由于问题本身的重要性和困难性,从20世纪70年代起图像分割问题就吸引了很多研究人员为之付出了巨大的努力。虽然到目前为止,还不存在一个通用的完美的图像分割的方法,但是对于图像分割的一般性规律则基本上已经达成的共识,已经产生了相当多的研究成果和方法。
前言
- 目前利用深度学习的方法进行图像分割是一种常用的方法。
- 下面为我们基于 PSPNet 进行图像分割
PSPNet介绍
Pyramid Scene Parsing Network 论文
图像分割七日打卡营
- PSPNet 通过金字塔池模块和提出的金字塔场景解析网络,聚合了基于不同区域的上下文信息,来挖掘全局上下文信息的能力
- PSPNet为像素级场景解析提供了有效的全局上下文先验
- 金字塔池化模块可以收集具有层级的信息,比全局池化更有代表性
- 在计算量方面,PSPNet并没有比原来的空洞卷积FCN网络有很大的增加
- 在端到端学习中,全局金字塔池化模块和局部FCN特征可以被同时训练
为什么会提出PSPNet ?
基于FCN的模型的主要问题是缺乏合适的策略来利用全局场景中的类别线索 :
- 分割结果不够精细
- 没有考虑上下文
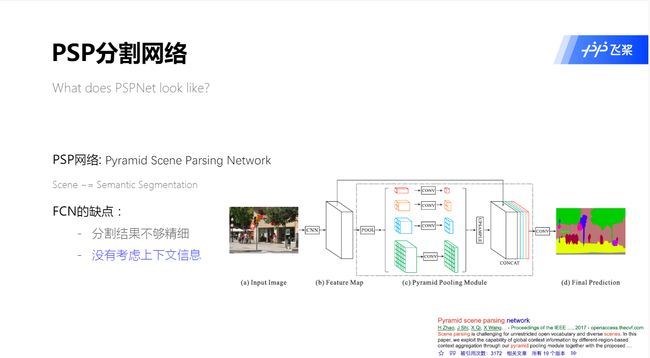
PSPNet 的效果为什么好 ?
- 多尺度特征融合
- 基于结构进行预测

PSPNet 是怎样考虑上下文信息的 ?
- 增大感受野(Receptive Field)

PSPNet 是怎样增大感受野的 ?
- 利用不同大小的池化
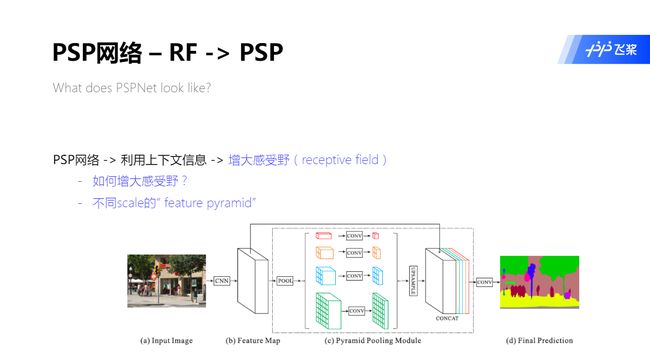
PSPNet - 金字塔模块(Pyramid Pooling)
- 为了进一步减少不同子区域间上下文信息的丢失,PSPNet 提出了一个有层次的全局先验结构(金字塔池化模块),包含不同尺度、不同子区域间的信息
- 可以在深层神经网络的最终层特征图上构造全局场景先验信息
PSP 模块:
- ① 将输入为 NCHW 特征图变成4个 HW 不同的特征图(1x1、2x2、3x3、6x6)
- ② 通过 1x1 的卷积给4个不同的特征图进行降维
- ③ 将4个不同的特征图通过上采样变为输入特征图大小
- ④ 将输入特征图和4个经过上采样后的特征图进行拼接
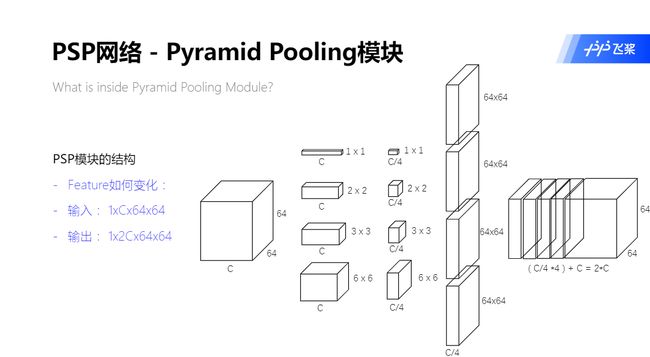
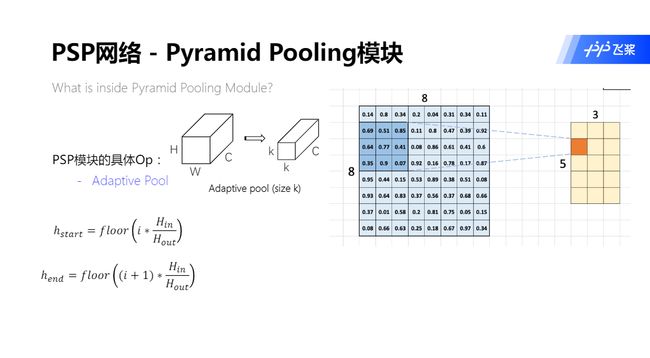
PSP 模块的具体操作:
- ① 自适应池化 : 将输入的特征图变成任意大小的特征图
- ② 1x1卷积 : 改变特征图的通道大小
- ③ Upsample : 将输入特征图的 HW 变大
- ④ Concat : 将多个特征图, 通过某一维度拼接起来
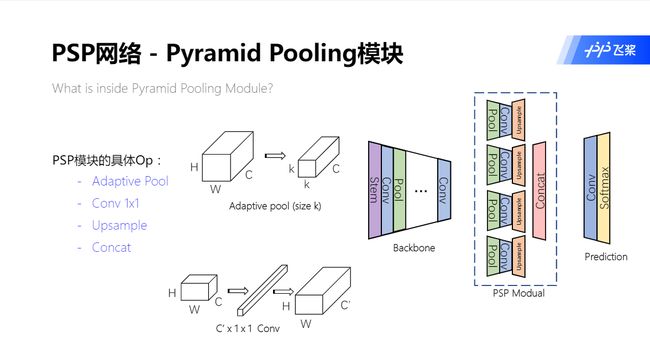
自适应池化
PSPNet 的总体结构
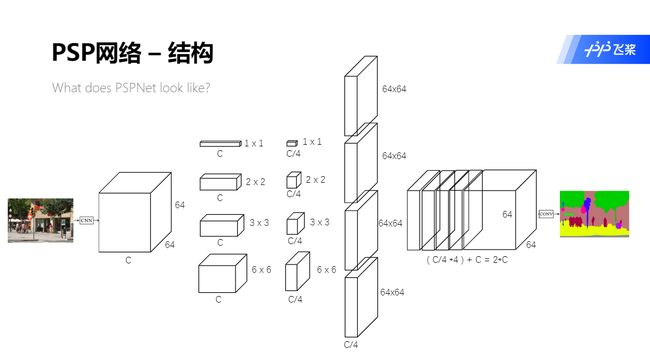
PSPNet - Backbone
Dilated Residual Networks 论文
- 空洞卷积

Dilated ResNet:
- 在 ResNet 的第4、5层(全连接层的前两层)采用 Dilation 为 2、4 的卷积
- 在 PSPNet 中我们只采用 Dilated ResNet 全连接层前的部分

代码
引入需要的包
import paddle
import os
import numpy as np
import cv2
import matplotlib.pyplot as plt
from tqdm import tqdm
# 一旦不再使用即释放内存垃圾,=1.0 垃圾占用内存大小达到10G时,释放内存垃圾
!export FLAGS_eager_delete_tensor_gb=0.0
# 启用快速垃圾回收策略,不等待cuda kernel 结束,直接释放显存
!export FLAGS_fast_eager_deletion_mode=1
# 该环境变量设置只占用0%的显存
!export FLAGS_fraction_of_gpu_memory_to_use=0
Pyramid Scene Parsing Network
ConvBNReluLayer
该类封装卷积、批归一化、ReLU,方便代码的复用。
class ConvBNReluLayer(paddle.nn.Layer):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, groups=1, dilation=1, padding=None, name=None):
"""
in_channels: 输入数据的通道数
out_channels: 输出数据的通道数
kernel_size: 卷积核大小
stride: 卷积步长
groups: 二维卷积层的组数
dilation: 空洞大小
padding: 填充大小
"""
super(ConvBNReluLayer, self).__init__(name)
if padding is None:
padding = (kernel_size-1)//2
self.conv = paddle.nn.Conv2D(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
dilation=dilation)
self.bn = paddle.nn.BatchNorm2D(num_features=out_channels)
self.relu = paddle.nn.ReLU()
def forward(self, inputs):
x = self.conv(inputs)
x = self.bn(x)
x = self.relu(x)
return x
BottleneckBlock
该类封装了ResNet层数大于等于50用的代码块,结构如下图:
包括3次卷积操作和1次元素相加操作;
元素相加 : 最开始的输入与最后的输出相加,当输入和输出的通道数不匹配时,会进行1x1卷积操作,进行维度匹配。
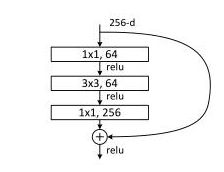
class BottleneckBlock(paddle.nn.Layer):
expansion = 4 # 最后的输出的通道数会变成4倍
def __init__(self, in_channels, out_channels, stride=1, shortcut=True, dilation=1, padding=None, name=None):
"""
shortcut: 最开始的输入和输出是否能进行直接相加的操作, 能=True, 不能=False(会进行1x1卷积操作进行维度匹配)。
"""
super(BottleneckBlock, self).__init__(name)
# 3次 (卷积、批归一化、ReLU) 操作
self.conv0 = ConvBNReluLayer(in_channels=in_channels, out_channels=out_channels, kernel_size=1)
self.conv1 = ConvBNReluLayer(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=stride, padding=padding, dilation=dilation)
self.conv2 = ConvBNReluLayer(in_channels=out_channels, out_channels=out_channels*4, kernel_size=1, stride=1)
if not shortcut:
# 不能直接相加时, 进行维度匹配
self.short = ConvBNReluLayer(in_channels=in_channels, out_channels=out_channels*4, kernel_size=1, stride=stride)
self.shortcut = shortcut
self.num_channel_out = out_channels * 4 # 最后的输出通道数变成4倍
def forward(self, inputs):
conv0 = self.conv0(inputs)
conv1 = self.conv1(conv0)
conv2 = self.conv2(conv1)
if self.shortcut:
short = inputs
else:
short = self.short(inputs)
y = paddle.add(x=short, y=conv2) # 元素相加
y = paddle.nn.functional.relu(x=y) # ReLU激活
return y
Dilated Resnet50
该类封装了 Dilated Resnet50 的代码,具体结构类似如下图,把原始 ResNet 的一些卷积操作改为了空洞卷积。
该类结构从上到下包括:
- 卷积核大小为7x7,卷积核通道数为64,步长为2的卷积操作
- 池化核大小为3x3,步长为2的最大池化层
- 16个 BottleneckBlock (4种,个数分别为3,4,6,3)
- 全局平均池化
- 全连接层
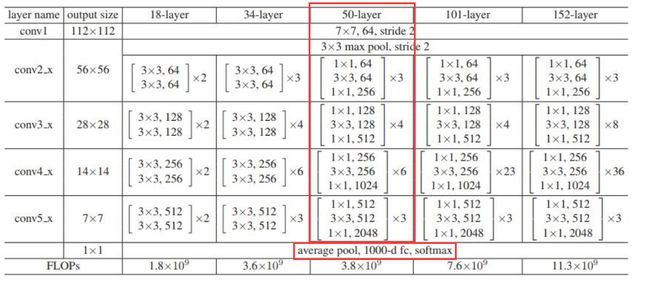
class DilatedResnet50(paddle.nn.Layer):
def __init__(self, block=BottleneckBlock, num_classes=1000):
super(DilatedResnet50, self).__init__()
# 4种BottleneckBlock, 每种个数如下
depth = [3, 4, 6, 3]
# 4种BottleneckBlock的输入数据通道数
num_channels = [64, 256, 512, 1024]
# 4种BottleneckBlock的第一个卷积核的通道数,最后输出会变为4倍
num_filters = [64, 128, 256, 512]
# 卷积操作
self.conv = ConvBNReluLayer(in_channels=3, out_channels=64, kernel_size=7, stride=2)
# 全局池化
self.pool2d_max = paddle.nn.MaxPool2D(kernel_size=3, stride=2, padding=1)
# BottleneckBlock的输入和输出是否能直接相加
l1_shortcut = False
# 第1种BottleneckBlock, 共3个, 将列表的操作解包依次添加到顺序容器Sequential中
self.layer1 = paddle.nn.Sequential(
*self.make_layer(
block,
num_channels[0],
num_filters[0],
depth[0],
stride=1,
shortcut=l1_shortcut,
name='layer1'
)
)
# 第2种BottleneckBlock, 共4个
self.layer2 = paddle.nn.Sequential(
*self.make_layer(
block,
num_channels[1],
num_filters[1],
depth[1],
stride=2,
name='layer2'
)
)
# 第3种BottleneckBlock, 共6个
self.layer3 = paddle.nn.Sequential(
*self.make_layer(
block,
num_channels[2],
num_filters[2],
depth[2],
stride=1,
name='layer3',
dilation=2
)
)
# 第4种BottleneckBlock, 共4个
self.layer4 = paddle.nn.Sequential(
*self.make_layer(
block,
num_channels[3],
num_filters[3],
depth[3],
stride=1,
name='layer4',
dilation=4
)
)
# 全局平均池化
self.last_pool = paddle.nn.AdaptiveAvgPool2D(output_size=(1, 1))
# 将全局池化的 NCHW -> NC, 用于全连接层
self.out_dim = num_filters[-1] * block.expansion
# 全连接层
self.fc = paddle.nn.Linear(in_features=num_filters[-1] * block.expansion, out_features=num_classes)
def forward(self, inputs):
x = self.conv(inputs)
x = self.pool2d_max(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.last_pool(x)
x = paddle.reshape(x, shape=[-1, self.out_dim])
x = self.fc(x)
return x
def make_layer(self, block, in_channels, out_channels, depth, stride, dilation=1, shortcut=False, name=None):
"""
用于生成4种BottleneckBlock
block: BottleneckBlock
depth: 该种BottleneckBlock的个数
"""
layers = paddle.nn.LayerList() # 用于保存子层列表,它包含的子层将被正确地注册和添加。
if dilation > 1:
# 如果进行了空洞卷积的操作, 则进行填充大小为空洞的大小
padding = dilation
else:
padding = None
# 添加BottleneckBlock
layers.append(block(
in_channels=in_channels,
out_channels=out_channels,
stride=stride,
shortcut=shortcut,
dilation=dilation,
padding=padding,
name=f'{name}.0'
))
# 添加BottleneckBlock, 这里添加的BottleneckBlock有相同的规律
for i in range(1, depth):
layers.append(block(
in_channels=out_channels * block.expansion,
out_channels=out_channels,
stride=1,
dilation=dilation,
padding=padding,
name=f'{name}.{i}'
))
return layers
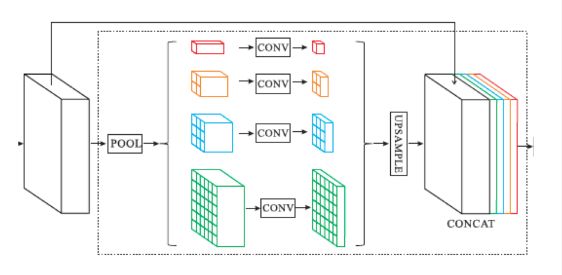
PSPModule
该类封装了金字塔池化模块,结构如下图。
该类操作包括:
- 将输入为 NCHW 特征图变成4个 HW 不同的特征图(1x1、2x2、3x3、6x6)
- 通过 1x1 的卷积给4个不同的特征图进行降维
- 将4个不同的特征图通过上采样变为输入特征图大小
- 将输入特征图和4个经过上采样后的特征图进行拼接
class PSPModule(paddle.nn.Layer):
def __init__(self, in_channels, bin_size_list):
"""
bin_size_list: 不同池化, 例如, 将输入为 NCHW 特征图变成4个 HW 不同的特征图(1x1、2x2、3x3、6x6),
则bin_size_list=[1, 2, 3, 6]
"""
super(PSPModule, self).__init__()
# 通过金字塔池化模块后得到的输出通道数为输入通道数2倍, 因此在不同池化结果通道数相加为输入通道数
out_channels = in_channels // len(bin_size_list)
# 用于保存子层列表,它包含的子层将被正确地注册和添加。
self.features = paddle.nn.LayerList()
for i in range(len(bin_size_list)):
# 添加池化层、1x1卷积层改变通道数、批归一化层
self.features.append(
paddle.nn.Sequential(
paddle.nn.AdaptiveMaxPool2D(output_size=bin_size_list[i]),
paddle.nn.Conv2D(in_channels=in_channels, out_channels=out_channels, kernel_size=(1, 1)),
paddle.nn.BatchNorm2D(num_features=out_channels)
)
)
def forward(self, inputs):
out = [inputs] # 添加输入数据,用于最后输出的拼接
for idx, f in enumerate(self.features):
x = f(inputs)
# 进行插值操作, 将不同池化的结果通过上采样变为输入数据的大小(HW维度上)
x = paddle.nn.functional.interpolate(x=x, size=inputs.shape[2::], mode='bilinear', align_corners=True)
out.append(x)
# 将所有特征图拼接起来
out = paddle.concat(x=out, axis=1) # NCHW
return out
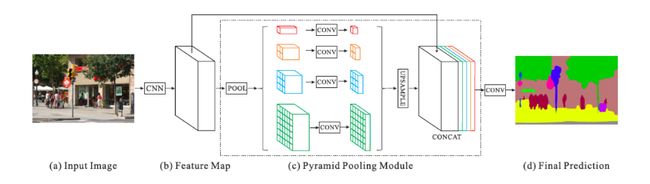
PSPNet
该类封装了整个PSPNet网络,用于进行图像分割,结构如下图。
该类包括:
- Dilated Resnet50 平均池化层以前的操作
- 金字塔模块
- 进行像素点分类的卷积操作
class PSPNet(paddle.nn.Layer):
def __init__(self, backbone='DilatedResnet50', num_classes=20):
"""
num_classes: 分类类别
"""
super(PSPNet, self).__init__()
res = DilatedResnet50()
# Dilated Resnet50 平均池化层以前的操作
self.layers = paddle.nn.Sequential(
res.conv,
res.pool2d_max,
res.layer1,
res.layer2,
res.layer3,
res.layer4
)
# self.layers out_channels = 2048
in_channels = 2048
# 金字塔模块, psp: 2048 -> 2048*2
self.pspmodule = PSPModule(in_channels=in_channels, bin_size_list=[1, 2, 3, 6])
in_channels *= 2
# 进行像素点分类的卷积操作, cls: 2048*2 -> 512 -> num_classes
self.classifier = paddle.nn.Sequential(
paddle.nn.Conv2D(in_channels=in_channels, out_channels=512, kernel_size=3, padding=1),
paddle.nn.BatchNorm2D(num_features=512),
paddle.nn.ReLU(),
paddle.nn.Dropout(0.1),
paddle.nn.Conv2D(in_channels=512, out_channels=num_classes, kernel_size=1)
)
def forward(self, inputs):
x = self.layers(inputs)
x = self.pspmodule(x)
x = self.classifier(x)
x = paddle.nn.functional.interpolate(x=x, size=inputs.shape[2::], mode='bilinear', align_corners=True)
return x
# 打印模型结构
paddle.summary(PSPNet(), (-1, 3, 600, 400))
解压数据集
!unzip data/data74563/humanparsing.zip -d data/
数据处理部分
将原图和分割图路径保存为 .txt文件
- JPEGImages : 原图文件夹
- SegmentationClassAug : 分割图文件夹
- 图片编号一一对应, 原图.jpg, 分割图.png
data = []
path1 = 'data/humanparsing/JPEGImages'
path2 = 'data/humanparsing/SegmentationClassAug'
for item in os.listdir(path1):
data.append([
os.path.join(path1, item), # 原图路径
os.path.join(path2, item.split('.')[0] + '.png') # 分割图路径
])
# 打乱数据集
np.random.shuffle(data)
# 划分训练集和验证集
train_data = data[len(data)//10:]
val_data = data[:len(data)//10]
# 将路径写入.txt文件
def write_path(data, path):
with open(path, 'w') as f:
for item in tqdm(data):
f.write(item[0] + ' ' + item[1] + '\n') # 原图路径 分割图路径
write_path(train_data, 'train.txt')
write_path(val_data, 'val.txt')
# 画图
def draw(img_list, name=None):
plt.figure(figsize=(15, 15))
for i in range(len(img_list)):
plt.subplot(1, len(img_list), i+1)
plt.imshow(img_list[i])
if name:
plt.title(name[i])
plt.legend()
plt.show()
# 查看数据
img1 = cv2.cvtColor(cv2.imread('data/humanparsing/JPEGImages/2500_818.jpg'), cv2.COLOR_BGR2RGB) # BGR -> RGB
img2 = cv2.imread('data/humanparsing/SegmentationClassAug/2500_818.png')[..., 0]
draw([img1, img2])
img3 = cv2.cvtColor(cv2.imread('data/humanparsing/JPEGImages/dataset10k_1073.jpg'), cv2.COLOR_BGR2RGB) # BGR -> RGB
img4 = cv2.imread('data/humanparsing/SegmentationClassAug/dataset10k_1073.png')[..., 0]
draw([img3, img4])


自定义数据集类
在自定义数据集类的时候,如有数据增强操作,由于是进行的分割,所有图像和标签要进行相同的操作。
class MyDataset(paddle.io.Dataset):
def __init__(self, mode, img_size=(600, 400)):
super(MyDataset, self).__init__()
assert mode in ['train', 'val'], "mode is one of ['train', 'val']"
self.mode = mode
self.img_size = img_size
self.data = []
with open(mode + '.txt', 'r') as f:
for line in f.readlines():
line = line.strip()
self.data.append([
line.split(' ')[0],
line.split(' ')[1]
])
# 将输入数据变成适合Conv2D的输入, NHWC -> NCHW
self.t = paddle.vision.transforms.Compose([
paddle.vision.transforms.Transpose((2, 0, 1)),
paddle.vision.transforms.Normalize(mean=127.5, std=127.5)
])
def __getitem__(self, idx):
img = cv2.imread(self.data[idx][0])
label = cv2.imread(self.data[idx][1])
img = paddle.vision.transforms.resize(img=img, size=self.img_size)
label = paddle.vision.transforms.resize(img=label, size=self.img_size)
if self.mode == 'train':
img, label = self.__transform(img, label)
img = self.t(img).astype('float32')
label = label[..., 0].astype('int64')
return img, label
def __len__(self):
return len(self.data)
def __transform(self, img, label):
flag = np.random.random()
if flag < 0.1:
angle = np.random.randint(360)
# 旋转
img = paddle.vision.transforms.rotate(img=img, angle=angle)
label = paddle.vision.transforms.rotate(img=label, angle=angle)
padding = [0, 0, 0, 0]
top = np.random.randint(self.img_size[0])
left = np.random.randint(self.img_size[1])
padding[2] = left
padding[3] = top
# 裁剪
img = paddle.vision.transforms.crop(img=img, top=top, left=left, height=self.img_size[0], width=self.img_size[1])
label = paddle.vision.transforms.crop(img=label, top=top, left=left, height=self.img_size[0], width=self.img_size[1])
# 填充
img = paddle.vision.transforms.pad(img=img, padding=padding)
label = paddle.vision.transforms.pad(img=label, padding=padding)
return img, label
# 数据增强效果演示
img_size = (600, 400)
def t(img, label):
"""
将自定义数据集里增强操作拿出来用一下
"""
angle = np.random.randint(360)
# 旋转
img = paddle.vision.transforms.rotate(img=img, angle=angle)
label = paddle.vision.transforms.rotate(img=label, angle=angle)
padding = [0, 0, 0, 0]
top = np.random.randint(img_size[0])
left = np.random.randint(img_size[1])
padding[2] = left
padding[3] = top
# 裁剪
img = paddle.vision.transforms.crop(img=img, top=top, left=left, height=img_size[0], width=img_size[1])
label = paddle.vision.transforms.crop(img=label, top=top, left=left, height=img_size[0], width=img_size[1])
# 填充
img = paddle.vision.transforms.pad(img=img, padding=padding)
label = paddle.vision.transforms.pad(img=label, padding=padding)
return img, label
# 画图
def draw(img_list, name=None):
plt.figure(figsize=(15, 15))
for i in range(len(img_list)):
plt.subplot(1, len(img_list), i+1)
plt.imshow(img_list[i])
if name:
plt.title(name[i])
plt.legend()
plt.show()
# 查看数据
img1 = cv2.cvtColor(cv2.imread('data/humanparsing/JPEGImages/2500_818.jpg'), cv2.COLOR_BGR2RGB) # BGR -> RGB
mask1 = cv2.imread('data/humanparsing/SegmentationClassAug/2500_818.png')
t_img1, t_mask1 = t(img1, mask1)
draw([img1, mask1[..., 0], t_img1, t_mask1[..., 0]], ['Img', 'Label', 'Transform_Img', 'Transform_Label'])
img2 = cv2.cvtColor(cv2.imread('data/humanparsing/JPEGImages/4565_1375.jpg'), cv2.COLOR_BGR2RGB) # BGR -> RGB
mask2 = cv2.imread('data/humanparsing/SegmentationClassAug/4565_1375.png')
t_img2, t_mask2 = t(img2, mask2)
draw([img2, mask2[..., 0], t_img2, t_mask2[..., 0]], ['Img', 'Label', 'Transform_Img', 'Transform_Label'])


# 测试自定义数据集读取情况
dataset = MyDataset(mode='train')
img, label = dataset[0]
print(img.shape, label.shape)
(3, 600, 400) (600, 400)
MIOU
- 评价图像分割效果的指标
- 分割每一类别的交并比(IOU)
import numpy as np
class IOUMetric:
"""
Class to calculate mean-iou using fast_hist method
"""
def __init__(self, num_classes):
self.num_classes = num_classes
self.hist = np.zeros((num_classes, num_classes))
def _fast_hist(self, label_pred, label_true):
# 找出标签中需要计算的类别,去掉了背景
mask = (label_true >= 0) & (label_true < self.num_classes)
# # np.bincount计算了从0到n**2-1这n**2个数中每个数出现的次数,返回值形状(n, n)
hist = np.bincount(
self.num_classes * label_true[mask].astype(int) +
label_pred[mask], minlength=self.num_classes ** 2).reshape(self.num_classes, self.num_classes)
return hist
# 输入:预测值和真实值
# 语义分割的任务是为每个像素点分配一个label
def evaluate(self, predictions, gts):
for lp, lt in zip(predictions, gts):
assert len(lp.flatten()) == len(lt.flatten())
self.hist += self._fast_hist(lp.flatten(), lt.flatten())
# miou
iou = np.diag(self.hist) / (self.hist.sum(axis=1) + self.hist.sum(axis=0) - np.diag(self.hist))
miou = np.nanmean(iou)
return miou
一些常用的函数
if os.path.exists('work/save_model') == False:
os.mkdir('work/save_model')
# 保存模型参数
def save_model(model, model_name):
print('{} model saving...'.format(model_name))
paddle.save(model.state_dict(), 'work/save_model/{}.pdparames'.format(model_name))
# 读取模型参数
def load_model(model, model_name):
if os.path.exists('work/save_model/{}.pdparames'.format(model_name)) == False:
print('No {} model pdparames...'.format(model_name))
else:
model.set_state_dict(paddle.load('work/save_model/{}.pdparames'.format(model_name)))
print('success loading {} model pdparames'.format(model_name))
# 保存指标列表
def save_miou_loss(data_list, name):
with open(name+'.txt', 'a') as f:
for data in data_list:
f.write(str(data) + '\n')
# 读取保存在文件的指标
def read_miou_loss(name):
data_list = []
with open(name+'.txt', 'r') as f:
for data in f.readlines():
data_list.append(eval(data.strip()))
return data_list
DataLoader
- 用于模型训练、验证
- 每次返回一个batch的数据
# 数据集
train_dataset = MyDataset(mode='train')
val_dataset = MyDataset(mode='val')
# dataloader
batch_size = 4
train_loader = paddle.io.DataLoader(dataset=train_dataset, batch_size=batch_size, places=paddle.CUDAPlace(0), shuffle=True, drop_last=True)
val_loader = paddle.io.DataLoader(dataset=val_dataset, batch_size=batch_size, places=paddle.CUDAPlace(0), shuffle=True, drop_last=True)
# 测试dataloader
count = 0
for (img, label) in train_loader:
print(img.shape, label.shape)
count += 1
if count == 10:
break
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dataloader/dataloader_iter.py:89: DeprecationWarning: `np.bool` is a deprecated alias for the builtin `bool`. To silence this warning, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
if isinstance(slot[0], (np.ndarray, np.bool, numbers.Number)):
[4, 3, 600, 400] [4, 600, 400]
[4, 3, 600, 400] [4, 600, 400]
[4, 3, 600, 400] [4, 600, 400]
[4, 3, 600, 400] [4, 600, 400]
[4, 3, 600, 400] [4, 600, 400]
[4, 3, 600, 400] [4, 600, 400]
[4, 3, 600, 400] [4, 600, 400]
[4, 3, 600, 400] [4, 600, 400]
[4, 3, 600, 400] [4, 600, 400]
[4, 3, 600, 400] [4, 600, 400]
模型声明
num_classes = 20
model_name = 'PSPNet'
model = PSPNet(num_classes=num_classes)
# 优化器
optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
# 损失函数
loss = paddle.nn.CrossEntropyLoss(axis=1)
# 分割效果指标
miou = IOUMetric(num_classes=num_classes)
# 模型加载
load_model(model=model, model_name=model_name)
success loading PSPNet model pdparames
Train
epochs = 5
train_loss_list = []
train_miou_list = []
val_loss_list = []
val_miou_list = []
print('Start Training...')
for epoch in range(1, epochs+1):
print('Epoch/Epochs:{}/{}'.format(epoch, epochs))
print('Train...')
train_loss = 0
train_miou = 0
model.train()
for batch_id, (img, label) in enumerate(train_loader):
optimizer.clear_grad()
pred = model(img)
step_loss = loss(pred, label)
train_loss += step_loss.numpy()[0]
# 计算miou, pred: num_loss * NCHW -> NHW
mask = np.argmax(pred.numpy(), axis=1)
step_miou = 0
for i in range(mask.shape[0]):
# print(mask[i].shape, label.shape)
step_miou += miou.evaluate(mask[i], label.numpy()[i])
step_miou /= mask.shape[0]
train_miou += step_miou
step_loss.backward()
optimizer.step()
# 打印信息
if (batch_id + 1) % 50 == 0:
print('Epoch/Epochs:{}/{} Batch/Batchs:{}/{} Step Loss:{} Step Miou:{}'.format(epoch, epochs, batch_id+1, len(train_loader), \
step_loss.numpy(), step_miou))
print('Train Loss:{} Train Miou:{}'.format(train_loss/len(train_loader), train_miou/len(train_loader)))
train_loss_list.append(train_loss/len(train_loader))
train_miou_list.append(train_miou/len(train_loader))
print('Val...')
val_loss = 0
val_miou = 0
model.eval()
for batch_id, (img, label) in tqdm(enumerate(val_loader)):
pred = model(img)
step_loss = loss(pred, label)
val_loss += step_loss.numpy()[0]
# 计算miou, pred: num_loss * NCHW -> NHW
mask = np.argmax(pred.numpy(), axis=1)
step_miou = 0
for i in range(mask.shape[0]):
# print(mask[i].shape, label.shape)
step_miou += miou.evaluate(mask[i], label.numpy()[i])
step_miou /= mask.shape[0]
val_miou += step_miou
print('Val Loss:{} Val Miou:{}'.format(val_loss/len(val_loader), val_miou/len(val_loader)))
val_loss_list.append(val_loss/len(val_loader))
val_miou_list.append(val_miou/len(val_loader))
save_model(model, model_name)
print('Train Over...')
# 保存数据
save_miou_loss(train_loss_list, 'train_loss')
save_miou_loss(train_miou_list, 'train_miou')
save_miou_loss(val_loss_list, 'val_loss')
save_miou_loss(val_miou_list, 'val_miou')
# 获得预测结果
def get_mask(img):
t = paddle.vision.transforms.Compose([
paddle.vision.transforms.Transpose((2, 0, 1)), # HWC -> CHW
paddle.vision.transforms.Normalize(mean=127.5, std=127.5)
])
img1 = paddle.to_tensor([t(img)]) # 输入网络的图片形状为 : NCHW
pred = model(img1) # NCHW
mask = np.argmax(pred.numpy(), axis=1) # NCHW -> NHW
return mask[0]
# 画图
def draw(img_list, name=None):
plt.figure(figsize=(15, 15))
for i in range(len(img_list)):
plt.subplot(1, len(img_list), i+1)
plt.imshow(img_list[i])
if name:
plt.title(name[i])
plt.legend()
plt.show()
model.eval()
img1 = cv2.imread('data/humanparsing/JPEGImages/4565_1912.jpg')
label1 = cv2.imread('data/humanparsing/SegmentationClassAug/4565_1912.png', 0)
mask1 = get_mask(img1)
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB) # BGR -> RGB
img2 = cv2.imread('data/humanparsing/JPEGImages/dataset10k_6890.jpg')
label2 = cv2.imread('data/humanparsing/SegmentationClassAug/dataset10k_6890.png', 0)
mask2 = get_mask(img2)
img2 = cv2.cvtColor(img2, cv2.COLOR_BGR2RGB) # BGR -> RGB
draw([img1, label1, mask1], ['Img', 'Label', 'Predict'])
draw([img2, label2, mask2], ['Img', 'Label', 'Predict'])


可视化结果
def show_list(data, name):
for i in range(len(data)):
plt.plot(np.array(data[i]), label=name[i])
plt.title(name[-1])
plt.xlabel('Epoch')
plt.legend()
plt.savefig(name[-1] + '.jpg')
plt.show()
train_loss_list = read_miou_loss('train_loss')
train_miou_list = read_miou_loss('train_miou')
val_loss_list = read_miou_loss('val_loss')
val_miou_list = read_miou_loss('val_miou')
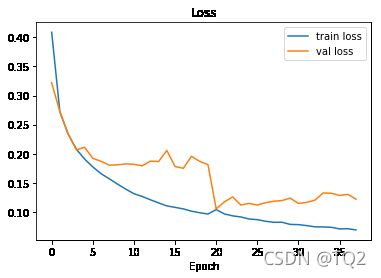
show_list(
[train_loss_list, val_loss_list],
['train loss', 'val loss', 'Loss']
)
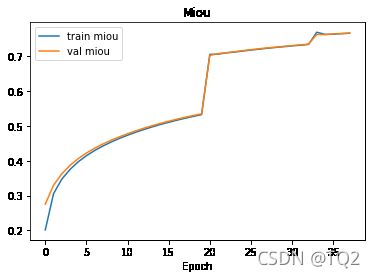
show_list(
[train_miou_list, val_miou_list],
['train miou', 'val miou', 'Miou']
)
网图测试效果
- 需要训练好的参数,效果才比较好
# 获得预测结果
def get_mask(img):
t = paddle.vision.transforms.Compose([
paddle.vision.transforms.Transpose((2, 0, 1)), # HWC -> CHW
paddle.vision.transforms.Normalize(mean=127.5, std=127.5)
])
img1 = paddle.to_tensor([t(img)]) # 输入网络的图片形状为 : NCHW
pred = model(img1) # NCHW
mask = np.argmax(pred.numpy(), axis=1) # NCHW -> NHW
return mask[0]
# 画图
def draw(img_list, name=None):
plt.figure(figsize=(15, 15))
for i in range(len(img_list)):
plt.subplot(1, len(img_list), i+1)
plt.imshow(img_list[i])
if name:
plt.title(name[i])
plt.legend()
plt.show()
# 读取模型
num_classes=20
model_name = 'PSPNet'
model = PSPNet(num_classes=num_classes)
# 模型加载
load_model(model=model, model_name=model_name)
model.eval()
# 预测
tsy_img = cv2.imread('tsy.jpg')
tsy_mask = get_mask(tsy_img)
draw(
[cv2.cvtColor(tsy_img, cv2.COLOR_BGR2RGB), tsy_mask]
)

项目总结
- 完成该项目需要对
ResNet网络和PSPNet网络有一定的了解,同时也需要了解PaddlePaddle API的用法,同时飞桨开源了很多模型代码,大家可以在PaddlePaddle下找到更多模型的开源代码学习,包括NLP,CV等。 - AI Studio平台也为我们提高了很多学习的资源,大家可以找到自己需要的学习资源。
- 更多基础的理论欢迎大家可以学习李宏毅老师课程专区。
- 大家在运行模型的时候遇见
OSError错误的时候,需要调小输入数据的批大小或者输入数据的尺寸,实在不行就只能换一个更小的模型了。 - 同时希望大家能在飞桨平台学习到更多的知识。