身兼数据科学家和自由职业者,算算我在2022赚了多少钱?
2022年,我作为自由职业者数据科学家赚了多少钱?
长按关注《Python学研大本营》,加入读者群,分享更多精彩
扫码关注《Python学研大本营》,加入读者群,分享更多精彩
大家好,首先,我已经等了很久了。
2021 年我在土耳其以自由职业者的身份工作,2022 年我意识到我已经准备好通过做出重大决定来从事全球工作。
我可以说,对于个人发展和开展各种项目来说,这是非常好的一年。
我从 Upwork 平台和各种额外平台接触到客户。
今天分享Upwork给大家的数据,我们来做一个数据分析。祝你读书愉快。

第一步:导入库
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport plotly.express as pxfrom plotly.offline import init_notebook_mode, iplotinit_notebook_mode(connected = True)第二步:导入数据集
df = pd.read_csv('upwork_gelir.csv')df.head()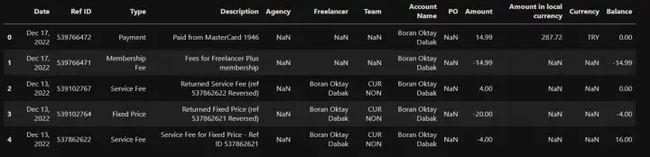
第三步:数据准备
df.info()当我们第一眼看到它时,我们可以了解到 Agency 和 PO 值有很多缺失的数据。
df.isnull().sum()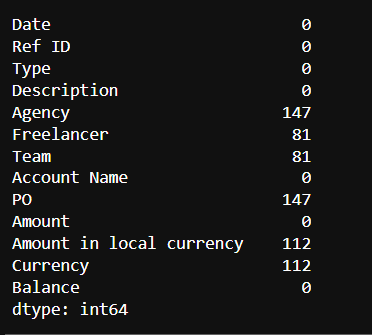
当我们查询缺失数据时,我们看到 Agency、PO、Amount in local currency、Currency、Freelancer 和 Team 列有太多缺失数据。
df.drop(columns = ['Ref ID','Description','Agency','PO','Amount in local currency','Currency'],axis=1,inplace = True)这就是为什么我们需要从数据集中删除无用的列和缺失数据过多的列。
df['Date'] = pd.to_datetime(df["Date"])df.set_index('Date',inplace = True)删除丢失的数据后,我们将 Date 列分配给我们的索引。
现在我们的数据集已准备好进行处理。
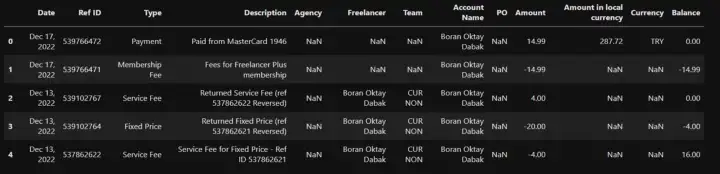
df.head()
第四步:EDA
我从公司赚取的收入分布:
fig = px.scatter(df,x = 'Amount',y = 'Team',color = 'Team')fig.show()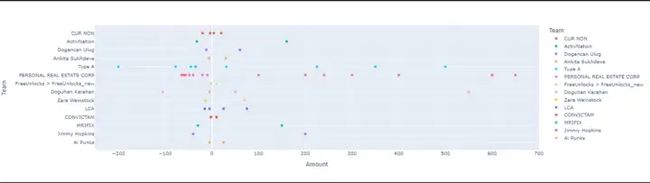
当我们检查图表时,我们可以了解到项目数量最多和收入最高的项目属于房地产公司。
前20名项目:
top_20_project = df.sort_values(by=['Amount'],ascending=False)[:20]top_20_project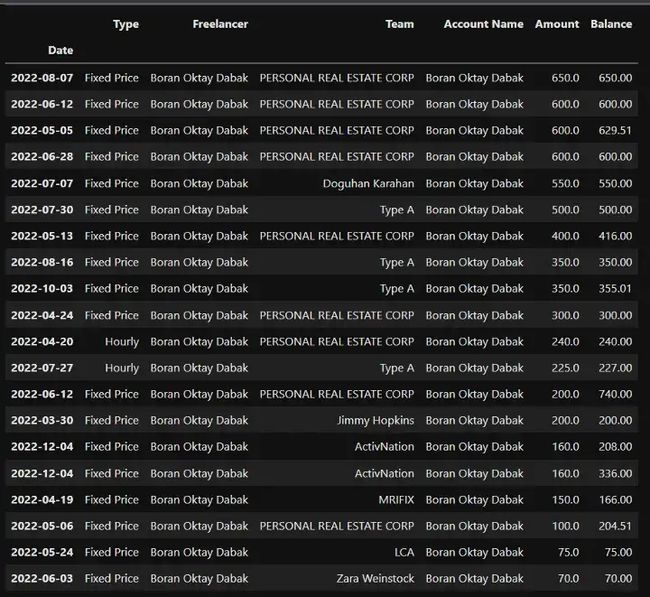
px.histogram(top_20_project,x = 'Team' , y = 'Amount',color = 'Team')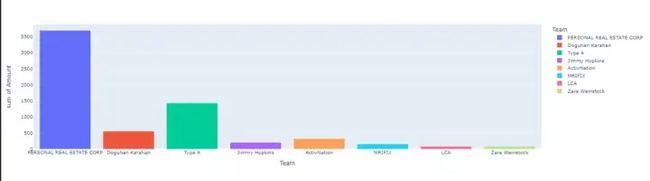
当我列出我赚得最多的20个项目时,我可以清楚地看到第一名是房地产公司,第二名是一家名为Type A的公司。
支付
payment = df[df[ 'Type' ] == 'Payment' ] payment
px.histogram(payment,x = payment.index, y = 'Amount' )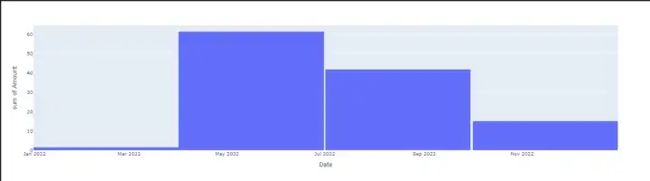
total_payment = round ( sum (payment.Amount), 2 ) total_payment全年,我总共向 Upwork 支付了 119.96美元。
会员费
membership = df[df['Type'] == 'Membership Fee']membership['Amount'] = membership['Amount'] * -1membership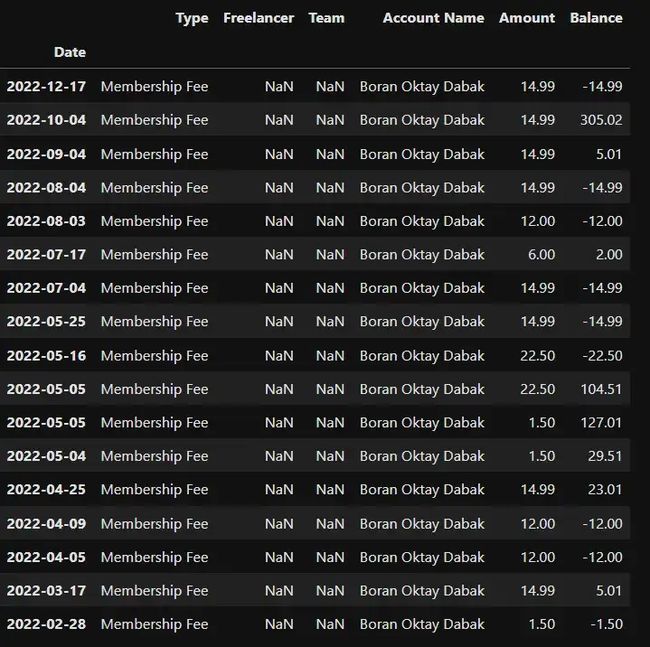
px.histogram(membership,x = membership.index , y = 'Amount')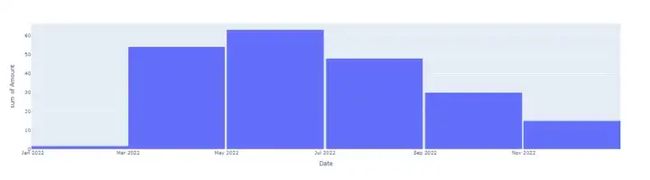
total_membership = round(sum(membership.Amount),2)total_membership总的来说,我还向 Upwork 支付了 211.42美元的会员交易费用。
Upwork 中有两种类型的工作。第一个是小时工资。第二个是固定价格协议。我是一个通常以固定价格在 Upwork 平台上工作的人。现在我们先来看每小时的价格数据。
小时工
hourly_price = df[df[ 'Type' ] == 'Hourly' ] hourly_price
小时工总收入
income_hourly = sum (hourly_price.Amount) income_hourly2022 年我的总收入是465 美元。
固定价格收入
fixed_price = df[df[ 'Type' ] == 'Fixed Price' ] fixed_price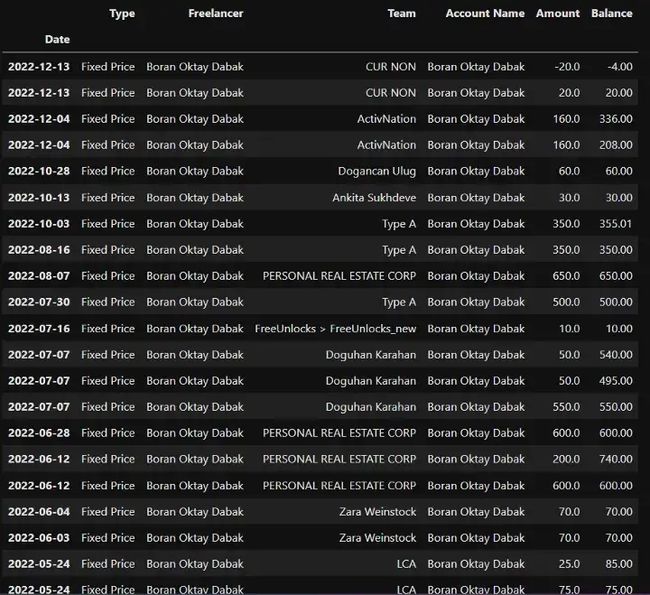
px.histogram(x=fixed_price.Team.value_counts().keys(),y = fixed_price.Team.value_counts().values,color = fixed_price.Team.value_counts().values)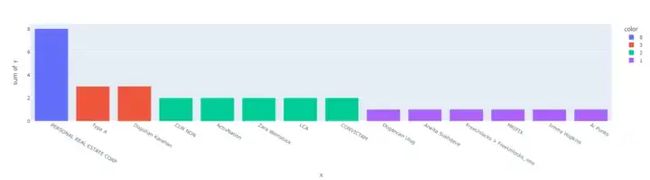
在这里,我们看到我们有 14 个不同的客户,与我们开展业务最多的是房地产公司。我合作最少的客户是 AI Punks 公司。
income_fixed_price = sum (fixed_price[ 'Amount' ])我最赚钱的客户
max_profit = fixed_price[fixed_price[ 'Team' ] == 'PERSONAL REAL ESTATE CORP' ] max_profit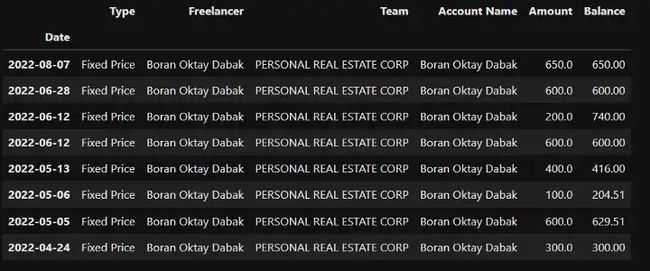
px.histogram(max_profit,x = max_profit.index, y = 'Amount' )
我们看图,好像每个月都在增加,但是7-8月之间是没有项目的。
sum(max_profit['Amount'])我从房地产公司总共赚了3450.0 美元。
总收入
total_income = income_fixed_price + income_hourly total_income当我计算我所有的客户时,我的总收入是6820.0 美元。
结论:
如果我必须计算我在 2022 年的收入,网络和 Upwork 的总体收入,我可以说我赚了 10,000 美元作为额外收入。当然,这个数字听起来不错,但我不得不说,对于真正刚刚起步的人来说,这将是一个非常艰难的过程。我为总共 14 家不同的公司和 5 个不同的国家做过专业项目。
你认为我明年会服务多少个不同的国家?

推荐书单
《PyTorch深度学习简明实战 》

本书针对深度学习及开源框架——PyTorch,采用简明的语言进行知识的讲解,注重实战。全书分为4篇,共19章。深度学习基础篇(第1章~第6章)包括PyTorch简介与安装、机器学习基础与线性回归、张量与数据类型、分类问题与多层感知器、多层感知器模型与模型训练、梯度下降法、反向传播算法与内置优化器。计算机视觉篇(第7章~第14章)包括计算机视觉与卷积神经网络、卷积入门实例、图像读取与模型保存、多分类问题与卷积模型的优化、迁移学习与数据增强、经典网络模型与特征提取、图像定位基础、图像语义分割。自然语言处理和序列篇(第15章~第17章)包括文本分类与词嵌入、循环神经网络与一维卷积神经网络、序列预测实例。生成对抗网络和目标检测篇(第18章~第19章)包括生成对抗网络、目标检测。
本书适合人工智能行业的软件工程师、对人工智能感兴趣的学生学习,同时也可作为深度学习的培训教程。
作者简介:
日月光华:网易云课堂资深讲师,经验丰富的数据科学家和深度学习算法工程师。擅长使用Python编程,编写爬虫并利用Python进行数据分析和可视化。对机器学习和深度学习有深入理解,熟悉常见的深度学习框架( PyTorch、TensorFlow)和模型,有丰富的深度学习、数据分析和爬虫等开发经验,著有畅销书《Python网络爬虫实例教程(视频讲解版)》。
购买链接(新书限时5.5折):https://item.jd.com/13528847.html

精彩回顾
《Pandas1.x实例精解》新书抢先看!
【第1篇】利用Pandas操作DataFrame的列与行
【第2篇】Pandas如何对DataFrame排序和统计
【第3篇】Pandas如何使用DataFrame方法链
【第4篇】Pandas如何比较缺失值以及转置方向?
【第5篇】DataFrame如何玩转多样性数据
【第6篇】如何进行探索性数据分析?
【第7篇】使用Pandas处理分类数据
【第8篇】使用Pandas处理连续数据
【第9篇】使用Pandas比较连续值和连续列
【第10篇】如何比较分类值以及使用Pandas分析库
长按关注《Python学研大本营》
长按二维码,加入Python读者群
扫码关注《Python学研大本营》,加入读者群,分享更多精彩