TFRecord的一些用法
1.TFRecord的用法
首先,TFRecord是把你的数据存成文件的一个东西。所以首先要有个写文件的东西,就是
writer = tf.io.TFRecordWriter(filename, options=None)
很明显writer有个函数就是writer.write(),就是把什么东西写到文件里,那要写的是什么东西呢?然后你可能就会看到教程里:
·················································下面是图片,不是我打的内容····························································

·······················································上面是图片·······························································
或者
官网上的
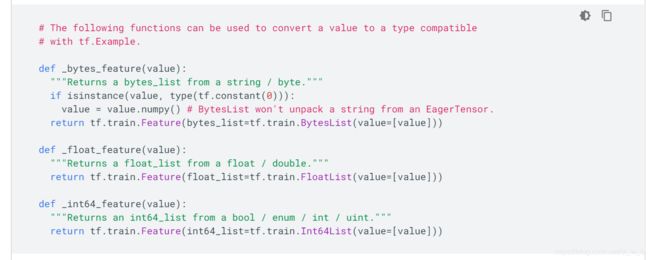
???但是这东西和要存的数据有啥关系???(实际这是官方教程的开篇,好多人也拿这个来开头,让人看的一头雾水)
其实上面这些用几行代码就很清楚了。
writer = tf.io.TFRecordWriter(file_name)
example = tf.train.Example(
features=tf.train.Features(
feature={
'name' : tf.train.Feature(bytes_list=tf.train.BytesList(value=[value1])),
'label': tf.train.Feature(int64_list=tf.train.Int64List(value=[value2])),
'data' : tf.train.Feature(bytes_list=tf.train.BytesList(value=[bytes(value3)]))
}
)
)
writer.write(example.SerializeToString())
实际上这东西就是个套娃, 只有value123是你的数据,这个套娃的最外层,叫Example,就理解成字面意思吧。然后Example里面要包含Features,Features这个类有个参数feature,feature是key和value的键值对{}。然后,value就是你的值了。不过value的数据类型得是Feature,所以需要再套一下
tf.train.Feature(bytes_list=tf.train.BytesList(value=[bytes(value3)])
tf.train.Feature(float_list=tf.train.FloatList(value=[value3])
tf.train.Feature(int64_list=tf.train.Int64List(value=[int(value3)])
然后构造完之后就可以用write()把Example写进文件了,这里需要example.SerializeToString()序列化一下。
理解了结构之后就可以反向读出来了,有个dataset = tf.data.TFRecordDataset(filenames)返回的就是一个tensorflow的dataset。dataset是一种数据类型,提供了方便的操作数据的函数比如shuffle, 划分batch啊啥的,dataset里面得元素就是我们的数据。但是这里面的数据还是序列化之后的数据,所以还得反序列化一下才能用。
feature_description = {
'name': tf.io.FixedLenFeature([], tf.string, default_value=''),
'label': tf.io.FixedLenFeature([], tf.int64, default_value=0),
'data': tf.io.FixedLenFeature([], tf.float, default_value=0)
}
可以用:
tf.io.parse_single_example(example, feature_description)
来反序列化一个example,然后因为tf.data.TFRecordDataset 读出来的dataset里面有很多个Example,所以一般把反序列化一个Example的部分写成一个函数,然后使用dataset的map把每个Example反序列化。
parsed_dataset = dataset.map(_parse_function)
这时候,再去看官网的例子:
https://tensorflow.google.cn/tutorials/load_data/tfrecord
这玩意里面还是有其他坑的,不过别人基本都踩过了,一般都能搜到。
上面说了基本用法,下面说下具体到自己存数据的时候怎么搞。
这里基于temsorflow 2.x来写的,不一定好,做个记录,希望能帮到有需要的人。
方案1
官方套娃式写法:
# 序列化
example = tf.train.Example(
features=tf.train.Features(
feature={
'feature0': tf.train.Feature(bytes_list=tf.train.BytesList(value=[feature0])),
'feature1': tf.train.Feature(float_list=tf.train.FloatList(value=[feature1])),
'feature2': tf.train.Feature(int64_list=tf.train.Int64List(value=[feature2])),
}))
example.SerializeToString()
# 反序列化
feature_description = {
'feature0': tf.io.FixedLenFeature([], tf.string),
'feature1': tf.io.FixedLenFeature([], tf.float32),
'feature2': tf.io.FixedLenFeature([], tf.int64),
}
tf.io.parse_single_example(parsed_example, feature_description)
优点:格式自由;缺点:在这个过程中,无法保存feature的shape,所以解决方案是把shape也保存起来,反序列化之后先获得shape,再reshape,这种方法需要在用的时候根据具体情况调整,不适合数据格式多变的情况。
方案2
后来找到了一个函数,可以直接把Tensor序列化和反序列化
# 序列化
serialized_example = tf.io.serialize_tensor(tensor)
# 反序列化
tf.io.parse_tensor(serialized_example, dtype)
优点:此种方法能保持shape的将一个Tensor进行序列化和反序列化;缺点:如果想把输入输出存一起就得魔改一下,比如把输入输出拼成一个Tensor,还是不够灵活。
方案3
结合两者特点:再进一步套娃
# 序列化
def serialize_example(feature0, feature1):
feature = {
'feature0': tf.train.Feature(bytes_list=tf.train.BytesList(value=[tf.io.serialize_tensor(feature0).numpy()])),
'feature1': tf.train.Feature(bytes_list=tf.train.BytesList(value=[tf.io.serialize_tensor(feature1).numpy()])),
}
example_proto = tf.train.Example(features=tf.train.Features(feature=feature))
return example_proto.SerializeToString()
# 反序列化
feature_description = {
'feature0': tf.io.FixedLenFeature([], tf.string, default_value=''),
'feature1': tf.io.FixedLenFeature([], tf.string, default_value=''),
}
example = tf.io.parse_single_example(serialized_example, feature_description)
feature0 = tf.io.parse_tensor(example['feature0'], dtype)
feature1 = tf.io.parse_tensor(example['feature1'], dtype)
这种方法既有格式自由的优点,还有保持数据shape的优点,那缺点肯定是有的,这种方案进一步套娃,时间和空间复杂度都上去了。
经测试,这种方案和方案2中的序列化Tensor方案对比:不读写文件的情况下,序列化之后再反序列化一个数据,时间复杂度差异为这种套娃方案比序列化方案高10倍以上。在预先写入序列化数据到tfrecord中,然后比较两者读出数据的时间,前者比后者所用高5倍左右。文件大小方面,前者比后者高约20%。(粗略测试)