Pandas实战-Series对象
本文将主要介绍以下内容:
1. Series概述
2. 从Python对象创建Series
3. 读取最前面和最后面的数据
4. 数学运算
5. 将Series传递给Python的内置函数
Series是Pandas的两个主要数据结构之一,它是用于存储同质数据的一维标记数组。术语“同质”是指这些值具有相同的数据类型。
每个Series的值都被分配一个标签和顺序。标签是值的标识符,可以是任何数据类型;顺序用整数表示,第一个值位于位置0。数据结构是一维的,因为任何元素都可以通过其标签或顺序位置进行访问。标签和位置的组合被称为Series的索引。
Series结合并扩展了Python内置数据结构的最佳特性。像列表一样,Series按顺序保存值;像字典一样,每个值都可以通过键或标签来访问。
1. Series概述
我们将从导入pandas和numpy开始,后一个库用于生成一些随机数据。pandas和numpy的流行社区别名是pd和np:
In [1]: import pandas as pd
import numpy as np1.1 模块、类和实例
pandas是拥有超过100个类、函数、异常、常量等的组合。Jupyter Notebook提供了一种便捷的方式来搜索对象的属性,只需要在对象后输入一个点,然后按Tab键,Notebook将显示对象的属性和方法。当键入其它字符时,结果将被过滤为与搜索字词匹配的结果,请注意,搜索区分大小写。
下例显示pd所有以大写字母S开头的属性:
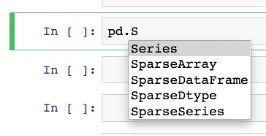
然后使用键盘的箭头键从下拉列表中选择Series,然后按Enter键。最后输入括号实例化Series对象:
In [2]: pd.Series()
Out [2]: Series([], dtype: object)就这样我们已经成功创建了第一个pandas对象!
1.2 用值填充Series
实例化对象时,可以为它的某些或所有属性传递初始值。这些值将传递给类构造函数,它是可通过类实例化对象的一种特殊方法。构造函数的参数可以按顺序传递,也可以用显式关键字参数传递,参数必须用逗号分隔。
Series构造函数的第一个参数是一个对象,其值可以用作Series的数据源。构造函数支持各种输入,包括列表、字典和元组。下面是使用Python列表来创建Series对象的例子:
In [3]: ice_cream_flavors = ["Chocolate", "Vanilla", "Strawberry", "Rum Raisin"]
pd.Series(ice_cream_flavors)
Out [3]: 0 Chocolate
1 Vanilla
2 Strawberry
3 Rum Raisin
dtype: object上例的Series有4个值,请注意,列表值的顺序会保留在Series中。每个构造函数参数都对应一个参数,每个参数都有指定的名称。上例ice_cream_flavors列表作为参数传递给构造函数的第一个参数,也就是名为data的参数。
我们可以在Jupyter Notebook中查看构造函数参数的完整列表,只要把鼠标光标放在括号之间,然后按Shift + Tab键:

Series构造函数定义了总共六个参数:data、index、dtype、name、copy和fastpath,等号右边的值是每个参数的默认值。当参数传递时没有指定参数名称时,Python会假定它们是按顺序传递的。在前面的示例中,我们的ice_cream_flavors列表作为第一个参数传递,因此将其分配给第一个参数data。index,dtype和name参数的默认值都是None;而copy和fastpath参数的默认值是False。
除了按顺序传递参数,还可以用显式关键字参数传递,这种方式允许以任何顺序传递:
In [4]: pd.Series(data = ice_cream_flavors)
Out [4]: 0 Chocolate
1 Vanilla
2 Strawberry
3 Rum Raisin
dtype: object1.3 自定义索引
Series左侧的递增数字列表称为索引,它的作用与列表中的索引位置相同:数字指示元素在行中的位置。pandas的索引既可以保存元素的位置,也可以保存标签。索引的标签可以包含任何不可变的数据类型。
Series构造函数定义了一个index参数,其参数将用作索引的数据源。如果未传递显式参数,pandas默认使用从0开始的数字索引,所以最后一个的索引号始终比该列中的值的总数小一。在下面的示例中,ice_cream_flavors是一个列表,days_of_week是一个元组,两个对象的长度均为4:
In [5]: ice_cream_flavors = ["Chocolate", "Vanilla", "Strawberry", "Rum Raisin"]
days_of_week = ("Monday", "Wednesday", "Friday", "Saturday")
pd.Series(data = ice_cream_flavors, index = days_of_week)
Out [5]: Monday Chocolate
Wednesday Vanilla
Friday Strawberry
Saturday Rum Raisin
dtype: objectpandas是基于共享索引位置将ice_cream_flavors和days_of_week的值相关联。例如,Strawberry和Friday都在它们各自对象的索引位置2,因此被关联在一起。
Series索引与列表索引或字典键不同的是前者允许重复。在下例中,Wednesday在days_of_week元组中出现两次,在Series索引标签中出现两次:
In [6]: ice_cream_flavors = ["Chocolate", "Vanilla", "Strawberry", "Rum Raisin"]
days_of_week = ("Monday", "Wednesday", "Friday", "Wednesday")
# 下面两行代码是一样的
pd.Series(ice_cream_flavors, days_of_week)
pd.Series(data = ice_cream_flavors, index = days_of_week)
Out [6]: Monday Chocolate
Wednesday Vanilla
Friday Strawberry
Wednesday Rum Raisin
dtype: object如前所述,关键字参数允许以任何顺序传递值。因此,下面的两行代码是一样的:
pd.Series(data = ice_cream_flavors, index = days_of_week)
pd.Series(index = days_of_week, data = ice_cream_flavors)除了data和index之外,第三个参数dtype也很重要,它反映了Series值的数据类型。如果未将显式值传递给dtype参数,则默认为None,并推断适当的数据类型。有点困惑的是,pandas对于字符串值会显示dtype: object。对于其它数据类型,通常会看到更精确的输出。下面的示例根据浮点数,布尔值和整数值创建一些Series对象:
In [7]: stock_prices = [985.32, 950.44]
times = ["Open", "Close"]
pd.Series(data = stock_prices, index = times)
Out [7]: Open 985.32
Close 950.44
dtype: float64
In [8]: bunch_of_bools = [True, False, False]
pd.Series(bunch_of_bools)
Out [8]: 0 True
1 False
2 False
dtype: bool
In [9]: lucky_numbers = [4, 8, 15, 16, 23, 42]
pd.Series(lucky_numbers)
Out [9]: 0 4
1 8
2 15
3 16
4 23
5 42
dtype: int641.4 创建有缺失值的序列
在现实世界中,经常遇到的问题是缺少值。pandas会使用numpy库的nan对象表示,该对象代表无效或缺失的概念。NaN是“not a number”的缩写,是无效值的笼统术语。
在下例中,我们从包含一个缺失值的列表中创建一个Series。在输出中,我们可以看到索引位置2处的NaN:
In [10]: temperatures = [94, 88, np.nan, 91]
pd.Series(data = temperatures)
Out [10]: 0 94.0
1 88.0
2 NaN
3 91.0
dtype: float64请注意,输入的数据类型已从列表中的整数转换为Series中的浮点数。pandas会在发现nan值时自动进行此转换。
2. 从Python对象创建Series
Series构造函数中的data参数接受各种输入,包括许多内置的Python对象。
2.1 字典 Dictionaries
当传递一个字典,pandas将使用每个键作为Series中的相应索引标签:
In [11]: calorie_info = {
"Cereal": 125,
"Chocolate Bar": 406,
"Ice Cream Sundae": 342
}
diet = pd.Series(calorie_info)
diet
Out [11]: Cereal 125
Chocolate Bar 406
Ice Cream Sundae 342
dtype: int64Series是由几个较小的对象组成或由其构成,每个较小的对象都被赋予特定的职责。Series是对象的合并,例如numpy库的ndarray(用于存储值)和pandas库的Index对象(用于存储索引)。pandas内置了十几个索引对象,以支持各种数据类型的索引,例如integers、intervals、和datetimes。
Series的嵌套对象可通过属性的方法读取。例如,values属性返回存储值的ndarray对象:
In [12]: diet.values
Out [12]: array([125, 406, 342])我们可以将任何对象传递给Python的内置type函数,以查看其构造类。注意ndarray来自NumPy,而不是Pandas。 ndarray对象通过依赖于底层C编程语言进行许多计算来优化速度和效率。
In [13]: type(diet.values)
Out [13]: numpy.ndarray类似地,index属性返回Series内部存储的Index对象:
In [14]: diet.index
Out [14]: Index(['Cereal', 'Chocolate Bar', 'Ice Cream Sundae'], dtype='object')
In [15]: type(diet.index)
Out [15]: pandas.core.indexes.base.Indexsize属性返回Series中值的数量:
In [16]: diet.size
Out [16]: 3shape属性返回任何pandas数据结构的尺寸的元组。对于像Series这样的一维对象,元组的唯一值就是它的大小。3之后的逗号是Python中单元素元组的标准可视输出:
In [17]: diet.shape
Out [17]: (3,)is_unique属性返回Series中的值是否是唯一不重复的:
In [18]: diet.is_unique
Out [18]: True
In [19]: pd.Series(data = [3, 3]).is_unique
Out [19]: Falseis_monotonic属性返回Series中的值是否是递增的:
In [20]: pd.Series(data = [1, 3, 6]).is_monotonic
Out [20]: True
In [21]: pd.Series(data = [1, 6, 3]).is_monotonic
Out [21]: False2.2 元组 Tuples
Series也可以接受元组作为其数据源。提醒一下,元组是类似于列表的数据结构,但它是不可变的。一旦声明了元组,就不能在元组中添加,删除或替换元素。
In [22]: pd.Series(data = ("Red", "Green", "Blue"))
Out [22]: 0 Red
1 Green
2 Blue
dtype: object要将一个或多个元组用作Series值,可以将它们包装在一个较大的容器(如列表)中:
In [23]: pd.Series(data = [("Red", "Green", "Blue"), ("Orange", "Yellow")])
Out [23]: 0 (Red, Green, Blue)
1 (Orange, Yellow)
dtype: object2.3 集合Sets
集合是唯一值的无序集合。提醒一下,用于声明集合的大括号语法与用于声明字典的大括号语法相同。Python能够根据键值对的分配(或没有分配)区分两种类型。如果我们将集合传递给Series构造函数,pandas将抛出TypeError异常。集合中没有顺序的概念,字典也是无序的,但是键和值之间存在关联,pandas可以将其转换为索引标签和值的关联,但不能对集合执行相同的操作。
In [24]: my_set = { "Ricky", "Bobby" }
pd.Series(my_set)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in
1 my_set = { "Ricky", "Bobby" }
----> 2 pd.Series(my_set)
TypeError: 'set' type is unordered 不过可以把集合在传递给Series构造函数之前,将其转换为有序数据结构(如列表):
In [25]: pd.Series(list(my_set))
Out [25]: 0 Ricky
1 Bobby
dtype: object2.4 NumPy数组
Series构造函数的data参数还接受ndarray对象作为其参数。在下例中,我们使用randint方法生成1到101之间的10个随机值的一维数组:
In [26]: data = np.random.randint(1, 101, 10)
data
Out [26]: array([27, 16, 13, 83, 3, 38, 34, 19, 27, 66])
In [27]: pd.Series(data)
Out [27]: 0 27
1 16
2 13
3 83
4 3
5 38
6 34
7 19
8 27
9 66
dtype: int64Series是一维数据结构,仅支持单个“列”数据。因此,如果我们尝试将多维ndarray传递给构造函数,例如下面的randn方法生成5x10的ndarray,则pandas将抛出“Data must be 1-dimensional”异常:
In [28]: pd.Series(np.random.randn(5, 10))
---------------------------------------------------------------------------
Exception Traceback (most recent call last)
in
----> 1 pd.Series(np.random.randn(5, 10))
Exception: Data must be 1-dimensional 3. 读取最前面和最后面的数据
接下来让我们使用Python的range函数来创建一个大小合适的Series。range的第一个参数是下限,第二个参数是上限,第三个参数是步长,即两个数字之间的差。在下例中,我们生成一个介于0和500之间的序列,每两个值的步长是5:
In [29]: values = range(0, 500, 5)
nums = pd.Series(data = values)
nums
Out [29]: 0 0
1 5
2 10
3 15
4 20
...
95 475
96 480
97 485
98 490
99 495
Length: 100, dtype: int64现在,我们有了一个具有100个值的Series!请注意出现在数据中间的三个点,为了避免拖垮Jupyter Notebook,pandas方便地将Series截短仅显示前五行和后五行的数据。
返回数据集的最前面一行或多行可以使用head方法,它接受一个表示要读取的行数的参数n:
In [30]: nums.head(3)
Out [30]: 0 0
1 5
2 10
dtype: int64上面的代码等同于nums.head(n = 3),参数n的默认值是5。如果调用head方法未显式传递n的参数,则将返回数据集的前五行:
In [31]: nums.head()
Out [31]: 0 0
1 5
2 10
3 15
4 20
dtype: int64返回数据集的最后面一行或多行可以使用tail方法,参数n的默认值也是5:
In [32]: nums.tail(3)
Out [32]: 97 485
98 490
99 495
dtype: int64
In [33]: nums.tail()
Out [33]: 95 475
96 480
97 485
98 490
99 495
dtype: int644. 数学运算
Series对象包含用于数学和统计运算的多种方法。在介绍它们之前,我们先使用一个递增列表来定义一个Series。在它的中间,我们用np.nan来表示缺失值:
In [34]: s = pd.Series([1, 2, 3, np.nan, 4, 5])sum方法返回所有值的总和,默认会忽略缺失值:
In [35]: s.sum()
Out [35]: 15.0大多数方法都包含一个skipna的参数,可以将其设置为False以计算缺失值,但因为空值不能与任何值相加,所以返回值也是一个空值:
In [36]: s.sum(skipna = False)
Out [36]: nanmin_count参数用于设置必须存在的最少非空值数量。在上例中s包含5个有效数值。在下面的前两个例子中,满足指定的要求。但在第三个中,有效数值少于指定的6个,因此sum返回nan:
In [37]: s.sum(min_count = 3)
Out [37]: 15.0
In [38]: s.sum(min_count = 5)
Out [38]: 15.0
In [39]: s.sum(min_count = 6)
Out [39]: nanproduct方法将Series的值相乘,像sum一样,它有skipna和min_count参数:
In [40]: s.product()
Out [40]: 120.0cumsum(累加和)方法返回一个新的Series,其值是滚动的累加和。每个索引位置都是该索引处的值和之前值的总和,这有助于确定哪些值对最终总数贡献最大。
In [41]: s.cumsum()
Out [41]: 0 1.0
1 3.0
2 6.0
3 NaN
4 10.0
5 15.0
dtype: float64在索引位置0的值是1,在索引位置1的累加和为1 + 2 = 3。最终索引位置的累加总和等于sum方法的返回值。
请注意,NaN值默认包含在返回的Series中。如果设置skipna参数为False,则返回的值会在出现nan时为NaN,然后剩下的值全部为NaN:
In [42]: s.cumsum(skipna = False)
Out [42]: 0 1.0
1 3.0
2 6.0
3 NaN
4 NaN
5 NaN
dtype: float64pct_change方法返回Series相邻值的百分比差异。数学公式等于将当前值和先前值相减,然后将结果除以先前值。pct_change方法默认会使用前一个有效值代替NaN:
In [44]: s.pct_change()
Out [44]: 0 NaN
1 1.000000
2 0.500000
3 0.000000
4 0.333333
5 0.250000
dtype: float64- 在索引0处,因为没有先前的值,所以返回NaN;
- 在索引1处,将值2.0与先前的值1.0相比较,百分比变化为(2.0 - 1.0)/1.0 = 100%,所以返回1.000000;
- 在索引3处,当前值是NaN,使用最后一个有效值(索引2中的3.0)代替,所以变化是0,返回0.000000;
- 在索引4处,将值4.0与上一行的值进行比较。再次,将索引3的NaN替换为最后一个有效值3.0。4和3之间的百分比变化为(4.0 - 3.0)/3.0 = 0.333333(即增加了33%)。
我们可以使用fill_method参数来自定义pct_change方法用来替代NaN值的逻辑。该参数默认值是pad,也就是之前提到过的使用前一个有效值代替NaN。下面的代码都会返回一样的结果:
s.pct_change()
s.pct_change(fill_method = "pad")
s.pct_change(fill_method = "ffill")处理缺失值的另外一种策略是使用后一个有效值代替NaN,fill_method参数值为bfill或backfill:
In [46]: s.pct_change(fill_method = "bfill") # is the same as
s.pct_change(fill_method = "backfill")
Out [46]: 0 NaN
1 1.000000
2 0.500000
3 0.333333
4 0.000000
5 0.250000
dtype: float64不难发现索引3和4的返回值和之前的例子刚好相反,因为当遇到NaN时会使用后一个有效值来代替,而不是前一个。
mean方法返回Series值的平均值,使用值的总和除以值的数量(15/5=3):
In [47]: s.mean()
Out [47]: 3.0median方法返回Series值的中位数,也就是说有一半的值将大于中位数,另一半的值将小于中位数。
In [48]: s.median()
Out [48]: 3.0std方法返回Series值的标准差,即数据变化量的统计量度:
In [49]: s.std()
Out [49]: 1.5811388300841898max和min方法返回Series值的最大和最小值:
In [50]: s.max()
Out [50]: 5.0
In [51]: s.min()
Out [51]: 1.0如果Series的值由字符串组成,则它们将按字母顺序排序。最大值是最接近字母z的值,最小值是最接近字母a的值:
In [52]: animals = pd.Series(["koala", "aardvark", "zebra"])
animals.max()
Out [52]: 'zebra'
In [53]: animals.min()
Out [53]: 'aardvark'describe方法返回一系列常见的统计评估,包括计数、均值、标准差等:
In [54]: s.describe()
Out [54]: count 5.000000
mean 3.000000
std 1.581139
min 1.000000
25% 2.000000
50% 3.000000
75% 4.000000
max 5.000000
dtype: float64sample方法返回Series中的一个随机值集合,它是一个新的Series对象。随机分类使新Series中的值顺序可能与原始Series中的值顺序不一致。在下例中,请注意,如果返回值没有NaN会使pandas返回Series的值为整数而不是浮点数:
In [55]: s.sample(3)
Out [55]: 1 2
3 4
2 3
dtype: int64sample方法有一个参数n,用于定义返回随机值的数量,默认为1:
In [56]: s.sample()
Out [56]: 0 1
dtype: int64unique方法返回Series中唯一值的ndarray对象:
In [57]: authors = pd.Series(["Hemingway", "Orwell", "Dostoevsky", "Fitzgerald", "Orwell"])
authors.unique()
Out [57]: array(['Hemingway', 'Orwell', 'Dostoevsky', 'Fitzgerald'], dtype=object)nunique方法返回Series中唯一值的数量:
In [58]: authors.nunique()
Out [58]: 44.1 算术运算
让我们创建一个新的Series。提醒一下,任何NaN值都会将Series中的值强制转换为浮点数:
In [59]: s1 = pd.Series(data = [5, np.nan, 15], index = ["A", "B", "C"])
s1
Out [59]: A 5.0
B NaN
C 15.0
dtype: float64标准算术运算(例如加、减、乘、除)可以应用于Series中的每个值。在下例中,我们将s1中的每个值加3,返回一个新的Series对象:
In [60]: s1 + 3
Out [60]: A 8.0
B NaN
C 18.0
dtype: float64NaN值保持不变,这些规则也适用于减法、乘法和除法:
In [61]: s1 - 5
Out [61]: A 0.0
B NaN
C 10.0
dtype: float64
In [62]: s1 * 2
Out [62]: A 10.0
B NaN
C 30.0
dtype: float64
In [63]: s1 / 2
Out [63]: A 2.5
B NaN
C 7.5
dtype: float64运算符 // 执行除法后取整。例如,15 / 4 = 3.75,15 // 4 = 3。
In [64]: s1 // 4
Out [64]: A 1.0
B NaN
C 3.0
dtype: float64模运算符 % 返回除法的余数:
In [65]: s1 % 3
Out [65]: A 2.0
B NaN
C 0.0
dtype: float644.2 Broadcasting
数学运算也可以应用于多个Series对象。根据一般经验,pandas将始终尝试通过共享索引标签关联数据值。在下例中,s1和s2有相同的三元素索引,因此把索引A(1和4),索引B(2和5)和索引C(3和6)的值加在一起:
In [66]: s1 = pd.Series([1, 2, 3], index = ["A", "B", "C"])
s2 = pd.Series([4, 5, 6], index = ["A", "B", "C"])
s1 + s2
Out [66]: A 5
B 7
C 9
dtype: int64Python的等于 == 和不等于 != 运算符可以比较两个Series中相同索引处的值。在下例中,返回值是一个新的布尔值Series,请注意,NaN值被认为是不相等的:
In [67]: s1 = pd.Series(data = [3, 6, np.nan, 12])
s2 = pd.Series(data = [2, 6, np.nan, 12])
s1 == s2
Out [67]: 0 False
1 True
2 False
3 True
dtype: bool
In [68]: s1 != s2
Out [68]: 0 True
1 False
2 True
3 False
dtype: bool如果索引之间存在差异,则Series之间的操作将变得更加复杂。一个索引可能比另一个索引具有更多或更少的值,或者这些值本身之间可能不匹配。在下例中,两个Series之间仅有两个索引标签(B和C)是相同的,对于其余索引(A,D和E),运算后返回NaN值,这是由于其中一个Series缺少相应的值。
In [69]: s1 = pd.Series(data = [5, 10, 15], index = ["A", "B", "C"])
s2 = pd.Series(data = [4, 8, 12, 14], index=["B", "C", "D", "E"])
s1 + s2
Out [69]: A NaN
B 14.0
C 23.0
D NaN
E NaN
dtype: float645. 将Series传递给Python的内置函数
让我们创建一个代表美国城市的字符串Series:
In [70]: cities = pd.Series(data = ["San Francisco", "Los Angeles", "Las Vegas"])len函数返回Series中的行数:
In [71]: len(cities)
Out [71]: 3如果Series包含NaN值,也将包括在计数中:
In [72]: mixed_data = [1, np.nan]
series_with_missing_values = pd.Series(data = mixed_data)
len(series_with_missing_values)
Out [72]: 2type函数返回构造对象的类:
In [73]: type(cities)
Out [73]: pandas.core.series.Seriesdir函数返回对象的属性和方法的列表。在Jupyter Notebook中执行代码以查看完整的输出 – 总共超过400个:
In [74]: dir(cities)
Out [71]: ['T',
'_AXIS_ALIASES',
'_AXIS_IALIASES',
'_AXIS_LEN',
'_AXIS_NAMES',
'_AXIS_NUMBERS',
'_AXIS_ORDERS',
'_AXIS_REVERSED',
'_HANDLED_TYPES',
'__abs__',
'__add__',
'__and__',
'__annotations__',
'__array__',
'__array_priority__',
'__array_ufunc__',
'__array_wrap__',
'__bool__', #...]list函数返回Series值的列表:
In [75]: list(cities)
Out [75]: ['San Francisco', 'Los Angeles', 'Las Vegas']dict函数将Series转换为字典,索引标签用作字典键:
In [76]: dict(cities)
Out [76]: {0: 'San Francisco', 1: 'Los Angeles', 2: 'Las Vegas' }max函数返回Series中的最大值,如果Series由字符串组成,则max按字母顺序返回最后一个值:
In [77]: max(cities)
Out [77]: 'San Francisco'min函数返回Series中的最小值,如果Series由字符串组成,则min按字母顺序返回第一个值:
In [78]: min(cities)
Out [78]: 'Las Vegas'in关键字查找给定值是否存在于Series的索引标签中,返回True或False:
In [79]: "Las Vegas" in cities
Out [79]: False
In [80]: 2 in cities # 2在索引标签能够找到
Out [80]: True要查找给定值是否包含在Series的值中,需要使用values属性返回的ndarray对象:
In [81]: "Las Vegas" in cities.values
Out [81]: Truenot in则相反,查找给定值是否不包含在Series中:
In [82]: 100 not in cities
Out [82]: True
In [83]: "Paris" not in cities.values
Out [83]: True
END O(∩_∩)O