Center-based 3D Object Detection and Tracking(基于中心的3D目标检测和跟踪 / CenterPoint)论文笔记
原文链接:https://arxiv.org/pdf/2006.11275.pdf
1 引言
CenterPoint先使用基于激光雷达的主干网络如VoxelNet或PointPillars,压缩为BEV后,使用基于图像的关键点检测器寻找物体中心。然后对每个物体中心回归尺寸、朝向和速度。然后,第二阶段细化物体位置,提取估计的3D边界框每个面中心特征。
基于中心点的物体表达可学习到物体的旋转不变性,简化了跟踪任务,且使得两阶段检测更快,能达到近似实时的效果。
3 准备知识
2D CenterNet将目标检测重述为关键点检测。输入图像,为 个类别输出
个类别输出![]() 热图,其局部极大值点代表了被检测物体的中心。然后为所有类别生成公共的尺寸图
热图,其局部极大值点代表了被检测物体的中心。然后为所有类别生成公共的尺寸图![]() 以获得2D边界框。对每个被检测物体,尺寸图在中心位置存储了其高度和宽度。该网络使用全卷积图像主干和密集预测头。
以获得2D边界框。对每个被检测物体,尺寸图在中心位置存储了其高度和宽度。该网络使用全卷积图像主干和密集预测头。
训练时,为每个类别预测 在标注物体中心带有高斯核 的热图,并在标注边界框的中心处回归尺寸。为了补偿主干网络步长引起的量化误差,也回归了局部偏移量。
测试阶段,热图局部峰值处物体的置信度与该峰值成正比。从回归图(尺寸图)中检索峰值对应的所有回归值,并应用非最大抑制(NMS)。
4 CenterPoint
网络结构如下图所示。
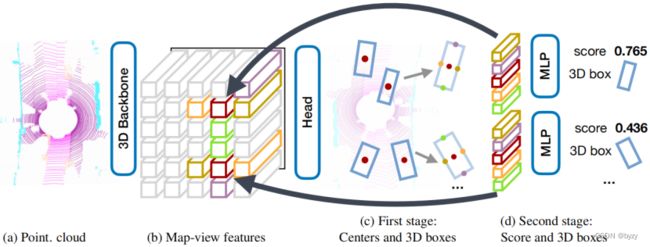
设![]() 是3D主干网络输出的2D BEV特征图,则第一阶段是预测与类别有关的热图、物体尺寸、子体素位置细化、旋转和速度。
是3D主干网络输出的2D BEV特征图,则第一阶段是预测与类别有关的热图、物体尺寸、子体素位置细化、旋转和速度。
中心热图头:使用focal损失。产生通道的热图,每个通道表示一个类别。目标是在 标注边界框的3D中心到BEV的投影处 产生2D高斯,高斯半径为![]() ,其中
,其中 为允许的最小高斯半径,
为允许的最小高斯半径, 是CornerNet中定义的半径函数。这样避免了监督的稀疏性。
是CornerNet中定义的半径函数。这样避免了监督的稀疏性。
回归头:在每个中心点特征处回归子体素位置细化![]() ,离地高度
,离地高度![]() ,3D尺寸
,3D尺寸![]() 和朝向角
和朝向角![]() 。子体素位置细化用于减小体素化和主干网络的步长带来的量化误差。训练时,以L1回归损失在真实物体中心进行监督。回归目标为对数值,以更容易处理不同尺寸的边界框。在推断时,提取密集回归图中物体峰值位置的属性。
。子体素位置细化用于减小体素化和主干网络的步长带来的量化误差。训练时,以L1回归损失在真实物体中心进行监督。回归目标为对数值,以更容易处理不同尺寸的边界框。在推断时,提取密集回归图中物体峰值位置的属性。
速度头和跟踪:为每个物体回归速度![]() ,需要当前帧的特征图和上一帧的特征图,通过物体位置差来估计。使用L1损失在当前帧真实物体位置进行监督。
,需要当前帧的特征图和上一帧的特征图,通过物体位置差来估计。使用L1损失在当前帧真实物体位置进行监督。
推断时,使用这个速度值贪心地关联当前帧和上一帧的被检测物体。即将当前帧物体中心根据其速度投影回上一帧,然后使用最近点匹配方法。对未匹配的物体保留一定帧数,并用最后已知的速度估计更新位置。
由于所有物体参数均由物体中心特征推断,可能缺少精确定位所需的信息。例如传感器只能看到物体的一个表面而非中心。因此在细化阶段(第二阶段)使用轻型点特征提取器。
4.1 两阶段CenterPoint
使用CenterPoint作为第一阶段。
第二阶段从主干输出提取额外的点特征。即从预测的边界框每个表面中心提取一个点特征,但由于BEV下顶面、底面和物体中心重合,故仅考虑4个侧面中心点和物体中心点。使用双线性插值从主干输出 中提取特征,拼接后通过MLP,预测类别无关的置信度分数并细化边界框。
中提取特征,拼接后通过MLP,预测类别无关的置信度分数并细化边界框。
置信度分数目标为![]() ,其中
,其中![]() 是第
是第 个提案框和真实框的3D IoU。使用二值交叉熵损失监督训练。推断时,将第一阶段预测的类别置信度和上述置信度分数进行几何平均:
个提案框和真实框的3D IoU。使用二值交叉熵损失监督训练。推断时,将第一阶段预测的类别置信度和上述置信度分数进行几何平均:
![]()
![]()
作为最终预测置信度。
边界框回归是在第一阶段边界框的基础上进行的。使用L1损失训练。
两阶段CenterPoint简化和加速了以前的两阶段3D检测器,因为后者使用了昂贵的基于PointNet的特征提取器和RoI对齐操作。
4.2 网络结构
第一阶段所有输出共享卷积+BN+ReLU的结构,然后各自再通过2层带BN和ReLU的卷积。
第二阶段所有输出共享带BN、ReLU和Dropout的2层MLP,然后各自通过3层全连接层。
5 实验
训练第二阶段时,随机采样1:1的正负提案框(若一个提案框与真实框的IoU大于阈值,则为正提案框)。
测试时,在非最大抑制后的前 个提案框上进行第二阶段的细化。
个提案框上进行第二阶段的细化。
5.1 主要结果
3D检测:在所有类别物体上的检测精度均有提升,特别是在小物体和极端长宽比的物体上。
3D跟踪:精度相比基于卡尔曼滤波器的方法有提升,且无需运动模型;无隐藏状态的计算,仅为最近邻匹配问题,耗时可忽略。
5.2 消融研究
锚框vs中心:将基于锚框的方法改为基于中心的方法有性能提升。后者可更精确检测严重旋转或偏离平均尺寸的物体。
一阶段vs二阶段:第二阶段以小计算开销换来了大性能提升。与RoI对齐操作相比,本文的方法有相近的性能,但更快且更简单。
体素量化限制了对行人的检测精度提升。
在低分辨率激光雷达点云中,第二阶段不会带来提升。
不同特征成分的影响:本文第二阶段只使用BEV特征细化边界框。
如果结合以下方法提取的体素特征,只有很小的性能提升,但耗时增加。
- 体素set abstraction(VSA):扩展PointNet++中的set abstraction,聚合给定半径内体素的特征。
- 径向基函数(RBF)插值:使用径向基函数,从3个最近的非空3D特征网格聚合网格特征。
附录
A.跟踪算法

B.实施细节
使用沿 或
或 轴翻转、随机缩放、随机旋转、复制粘贴数据增广。
轴翻转、随机缩放、随机旋转、复制粘贴数据增广。