COCO数据集解析生成语义分割mask
COCO数据集解析生成语义分割mask
通过coco数据集的标注文件 — instances_train2014.json / instances_val2014.json 生成语义分割mask存在不同类别区域重叠问题,导致重叠部分像素的数值超出 [0,80] 范围内,模型训练时报错:
103: block: [1,0,0], thread: [448,0,0] Assertiont >= 0 && t < n_classesfailed.
文章目录
- COCO数据集解析生成语义分割mask
-
- coco数据集
- 一、pycocotools --- 介绍
- 二、基于 pycocotools 提供的 api 生成 mask 标注
-
- 1.引入库
- 2.设置数据路径(train / val)
- 2.读入数据生成 mask(train / val)
- 完整代码
coco数据集
将coco数据集用于语义分割需要生成对应的mask,官方下载的coco2014/2017数据集的标注信息:
图片: 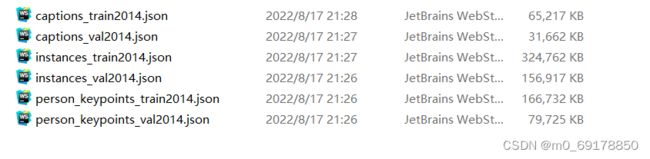
train/val 的注释文件分别有 caption,instance,person_keypoint 这三个任务方向,语义分割注释文件 instances_train2014.json 和 instances_val2014.json ,用于之后的mask提取。
train/val 的 image 文件在 train2014 、val2014、test2014 里,train2014 共有82783张图像,val2014 共有40504张图像。
一、pycocotools — 介绍
COCO是一个大型的图像数据集,用于目标检测、分割、人的关键点检测、实例分割和标题生成。pycocotools 提供了 Matlab、Python 和 luaapi,这些api有助于在COCO中加载、解析和可视化注释。请访问http://cocodataset.org/,可以了解关于COCO的更多信息,包括数据、论文和教程。COCO网站上也描述了注释的确切格式。
linux 安装 pycocotools
pip install pycocotools
因为 pycocotools 并不支持 windows 平台,采用上述命令会安装失败。采用以下方法安装:
- 查询 anaconda 对 pycocotools 的支持,点击 https://anaconda.org/search?q=pycocotools 在搜索栏输入 pycocotools :
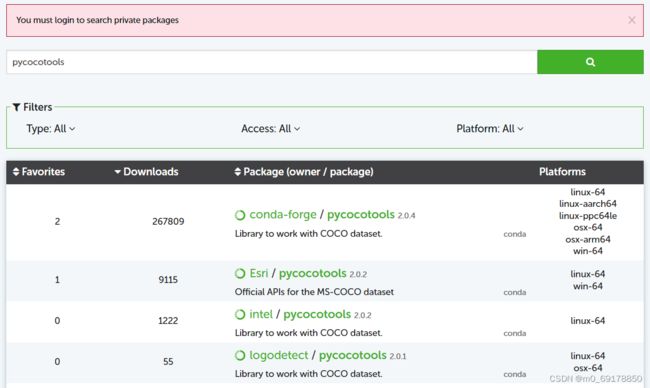
- 查看 conda-forge 支持的安装命令:
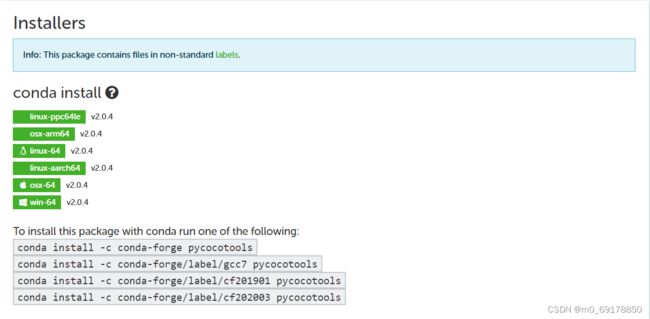
- 在终端输入上诉任一命令,安装 pycocotools 包
二、基于 pycocotools 提供的 api 生成 mask 标注
1.引入库
代码如下:
import shutil
import cv2
from PIL import Image
import imgviz
import argparse
import os
import tqdm
import numpy as np
from pycocotools.coco import COCO # COCO 数据集标注解析库
2.设置数据路径(train / val)
代码如下:
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--input_dir", default="/home/yc/onionDocument/code/model/MSCOCO2014/", type=str,
help="input dataset directory") # coco数据集路径
parser.add_argument("--split", default="train2014", type=str,
help="train2014 or val2014") # 解析训练数据(train)或者验证数据(val)
return parser.parse_args()
2.读入数据生成 mask(train / val)
- 标注信息保存路径
annotation_file = os.path.join(args.input_dir, 'annotations', 'instances_{}.json'.format(args.split)) # 标注文件路径
# 保存方式有两种,一种为灰度模式、一种为调色板模式
os.makedirs(os.path.join(args.input_dir, 'train2014_annotations'), exist_ok=True) # 灰度模式
os.makedirs(os.path.join(args.input_dir, 'Binary_map_aug'), exist_ok=True) # 调色板模式
os.makedirs(os.path.join(args.input_dir, 'JPEGImages'), exist_ok=True) # 所有处理的图片
- 获取 COCO 对象解析标注文件 — json
coco = COCO(annotation_file) # 解析 .json 文件生成 COCO 对象
catIds = coco.getCatIds() # 获取类别 id
imgIds = coco.getImgIds() # 获取图片 id
print("catIds len:{}, imgIds len:{}".format(len(catIds), len(imgIds)))
注意:coco 数据集共有 80 个类,但类别 id 并不是连续的 1~80,完整的类别标签如下图:

- 解析生成 mask
在分割任务里(语义分割/实例分割), Mask图像里的每个像素值代表了像素点所属的类别标签,一般这里mask是单通道也就是位深为8-bits。对于单个类别的数据集来说,一般是区分前景目标、背景,Mask像素值应该是{0,1},0为黑色表示背景,1为白色表示前景;对于多个类别的数据集,在图像当中分割多个类别目标,Mask像素值应该是[0,1,2,…]显示为彩色以区分不同目标,可以选择使用调色板彩图(单通道8位 [0,255] 表示不同的色彩)或者灰度图(单通道8位 [0,255] 表示不同的灰度)。
主要解决两个问题:1、将类别统一到0~80这个区间,需要建立索引重映射;2、部分注释区域是有重叠的,对重叠部分的处理。
for imgId in tqdm.tqdm(imgIds, ncols=100):
img = coco.loadImgs(imgId)[0]
annIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds, iscrowd=None)
anns = coco.loadAnns(annIds)
if len(annIds) > 0:
pre_cat_mask = coco.annToMask(anns[0])
mask = pre_cat_mask * (catIds.index(anns[0]['category_id']) + 1) # 将类别统一到0~80这个区间
for i in range(len(anns) - 1):
binary_mask = coco.annToMask(anns[i + 1])
mask += binary_mask * (catIds.index(anns[i + 1]['category_id']) + 1)
mask_area = pre_cat_mask + binary_mask
mask_intersection_area = np.where(mask_area == 2) # 重叠部分
if len(mask_intersection_area[0]) > 0:
mask[mask_intersection_area[0]][mask_intersection_area[1]] = \
catIds.index(anns[i + 1]['category_id']) + 1
mask_area[mask_intersection_area[0]][mask_intersection_area[1]] = 1
# for j in range(len(mask_intersection_area[0])):
# mask[mask_intersection_area[0][j]][mask_intersection_area[1][j]] = \
# catIds.index(anns[i + 1]['category_id']) + 1
# mask_area[mask_intersection_area[0][j]][mask_intersection_area[1][j]] = 1
pre_cat_mask = mask_area
- 调色板图保存
def save_colored_mask(mask, save_path):
lbl_pil = Image.fromarray(mask.astype(np.uint8), mode="P")
colormap = imgviz.label_colormap()
lbl_pil.putpalette(colormap.flatten())
lbl_pil.save(save_path)
完整代码
import shutil
import cv2
from PIL import Image
import imgviz
import argparse
import os
import tqdm
import numpy as np
from pycocotools.coco import COCO
def save_colored_mask(mask, save_path):
lbl_pil = Image.fromarray(mask.astype(np.uint8), mode="P")
colormap = imgviz.label_colormap()
lbl_pil.putpalette(colormap.flatten())
lbl_pil.save(save_path)
def main(args):
annotation_file = os.path.join(args.input_dir, 'annotations', 'instances_{}.json'.format(args.split))
os.makedirs(os.path.join(args.input_dir, 'train2014_annotations'), exist_ok=True)
os.makedirs(os.path.join(args.input_dir, 'Binary_map_aug'), exist_ok=True)
os.makedirs(os.path.join(args.input_dir, 'JPEGImages'), exist_ok=True)
coco = COCO(annotation_file)
catIds = coco.getCatIds()
imgIds = coco.getImgIds()
print("catIds len:{}, imgIds len:{}".format(len(catIds), len(imgIds)))
for imgId in tqdm.tqdm(imgIds, ncols=100):
img = coco.loadImgs(imgId)[0]
annIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds, iscrowd=None)
anns = coco.loadAnns(annIds)
if len(annIds) > 0:
pre_cat_mask = coco.annToMask(anns[0])
mask = pre_cat_mask * (catIds.index(anns[0]['category_id']) + 1)
for i in range(len(anns) - 1):
binary_mask = coco.annToMask(anns[i + 1])
mask += binary_mask * (catIds.index(anns[i + 1]['category_id']) + 1)
mask_area = pre_cat_mask + binary_mask
mask_intersection_area = np.where(mask_area == 2)
if len(mask_intersection_area[0]) > 0:
mask[mask_intersection_area[0]][mask_intersection_area[1]] = \
catIds.index(anns[i + 1]['category_id']) + 1
mask_area[mask_intersection_area[0]][mask_intersection_area[1]] = 1
# for j in range(len(mask_intersection_area[0])):
# mask[mask_intersection_area[0][j]][mask_intersection_area[1][j]] = \
# catIds.index(anns[i + 1]['category_id']) + 1
# mask_area[mask_intersection_area[0][j]][mask_intersection_area[1][j]] = 1
pre_cat_mask = mask_area
img_origin_path = os.path.join(args.input_dir, 'images', args.split, img['file_name'])
img_output_path = os.path.join(args.input_dir, 'JPEGImages', img['file_name'])
seg_output_path = os.path.join(args.input_dir, 'train2014_annotations', img['file_name'].replace('.jpg', '.png'))
seg_output_path_show = os.path.join(args.input_dir, 'Binary_map_aug', img['file_name'].replace('.jpg', '.png'))
if len(np.where(mask > 80)[0]) > 0:
print("error")
shutil.copy(img_origin_path, img_output_path)
cv2.imwrite(seg_output_path, mask)
save_colored_mask(mask, seg_output_path_show)
print("process end")
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--input_dir", default="/home/yc/onionDocument/code/model/MSCOCO2014/", type=str,
help="input dataset directory")
parser.add_argument("--split", default="train2014", type=str,
help="train2014 or val2014")
return parser.parse_args()
if __name__ == '__main__':
args = get_args()
main(args)