Multi-Task GANs for View-Specific Feature Learning in Gait Recognition论文翻译以及理解
Multi-Task GANs for View-Specific Feature Learning in Gait Recognition论文翻译以及理解
今天想尝试一下翻译一篇自己读的论文。写的不好,后续慢慢改进。
Abstract
Abstract— Gait recognition is of great importance in the fields of surveillance and forensics to identify human beings since gait is the unique biometric feature that can be perceived efficiently at a distance. However, the accuracy of gait recognition to some extent suffers from both the variation of view angles and the deficient gait templates. On one hand, the existing cross-view methods focus on transforming gait templates among different views, which may accumulate the transformation error in a large variation of view angles. On the other hand, a commonly used gait energy image template loses temporal information of a gait sequence. To address these problems, this paper proposes multi-task generative adversarial networks (MGANs) for learning view-specific feature representations. In order to preserve more temporal information, we also propose a new multi-channel gait template, called period energy image (PEI). Based on the assumption of view angle manifold, the MGANs can leverage adversarial training to extract more discriminative features from gait sequences. Experiments on OU-ISIR, CASIA-B, and USF benchmark data sets indicate that compared with several recently published approaches, PEI + MGANs achieves competitive performance and is more interpretable to cross-view gait recognition.
Index Terms— Gait recognition, cross-view, generative adversarial networks, surveillance
译文
摘要–由于步态是一种可以在远处有效获得的独特生物特征,因此步态识别在监视和取证领域非常重要。然而,步态识别的正确率在某种程度上受到视角变化和缺乏统一的步态模板的困扰。一方面,现有的跨视角方法专注于在不同视角之间转换步态模板,这种方法在所跨视角较大时,误差会不断的累积。另一方面,常用的步态能量图模板丧失掉了步态序列的时间信息。为了解决这两个问题,本文提出了用于学习视角特征表示的多任务的生成对抗式网络。为了能保留更多的时间信息,我们提出了一种新的多通道步态模板,叫做period energy image(PEI)。基于视角变化的假设,MGAN可以利用对抗训练从步态序列中提取更多的判别特征。在基准数据集OU-ISIR,CASIA-B和USF上的实验表明,与最近发布的几种方法相比,PEI + MGANs具有可比的性能,并且可以更好地解释步态识别跨视角问题。
I. INTRODUCTION
DIFFERENT from other biometric features such as human faces, fingerprints, and irises which are usually obtained at a close distance, gait is the unique biometric feature that can identify humans at a far distance. However, the performance of gait recognition [1] suffers from various exterior factors including clothing [2], walking speed [3], low resolution [4] and so on. Among these factors, the change of view angles greatly influences the generalization ability of gait recognition models. For example, when a person walks across a camera located at a fixed position, the gait appearance of the person may vary along walking directions, making a formidable barricade in recognizing the human under the cross-view case.
与通常可以在近距离获得的生物特征(例如人脸,指纹和虹膜)不同,步态是可以识别远距离识别人物的独特生物特征。然而,步态识别[1]的性能受到各种外部因素的影响,包括服装[2],步行速度[3],低分辨率[4]等。在这些因素中,视角的变化极大地影响了步态识别模型的泛化能力。例如,当人走过位于固定位置的摄像机时,人体的步态外观会随着行走方向发生变化,这是在跨视角情况下步态识别的一大挑战。
To solve this problem, some researchers [5]–[8] proposed to learn transformations or projections between different view angles in cross-view gait recognition. Specifically, the View Transform Model (VTM) [9]–[12] transforms gait templates such as Gait Energy Image (GEI) [13] from one view to another. However, VTM requires predicting each pixel value of GEI independently, which is time-consuming and inefficient. To reduce the computational time, an auto-encoder based model [14] is used to reconstruct GEI and extract viewinvariant features. In order to achieve view transformations, these two methods reconstruct gait templates via transitional view angles. In this way, however, the reconstruction error may be accumulated if there is a large view variation between two view angles.
为了解决这个问题,一些研究人员[5] - [8]提出在跨视角步态识别中学习不同视角之间的变换或投影。具体来说,视图变换模型(VTM)[9] - [12]将步态模板(如步态能量图像(GEI)[13])从一个视图转换为另一个视图。然而,VTM需要独立地预测GEI的每个像素值,这是耗时且低效的。为了减少计算时间,另一种是基于自动编码器的模型[14]用于重建GEI并提取视图变量特征。为了实现视角变换,这两种方法通过过渡阶段视角重建步态模板。然而,当两个视角之间存在较大的角度变化时,这种方式会累积重建误差。
The recently published Generative Adversarial Networks (GANs) interpolate facial poses or age variations along a low-dimensional manifold [15], [16]. It has the ability to model data distribution to improve the performance of different vision tasks such as super-resolution [17] and inpainting [18]. However, original GANs methods generate images from random noise, lacking features that can preserve identity information, which is undesirable for cross-view gait recognition.
最近发表的生成性对抗网络(GAN)可以沿着低维流形改变面部表情或年龄[15],[16]。它可以通过模拟数据的分布来提高不同视觉任务(例如,超分辨率和修复)的性能。然而,原始GAN方法从随机噪声中生成图像,缺少可以保存身份信息的特征,这对于跨视图步态识别是不利的。
In order to overcome the shortcomings mentioned above, this paper proposes Multi-task Generative Adversarial Networks (MGANs) to learn view-specific features from gait templates.Further, we propose a new multi-channel gait template,named Period Energy Image (PEI), which is a generalization of GEI. The PEI template can maintain more temporal and spatial information compared with other templates such as GEI and Chrono-Gait Image (CGI) [19], [20]. Extensive experiments on three gait benchmark datasets indicate that our MGANs model with PEI achieves competitive performance in cross-view gait recognition compared with several recently published approaches.
为了克服上述缺点,本文提出了多任务生成对抗网络(MGAN)来学习步态模板中的视图特征。此外,我们提出了一种新的多通道步态模板,称为周期能量图像(PEI)。这是GEI更加一般化的表达。与其他模板(如GEI和Chrono-Gait Image(CGI)[19],[20])相比,PEI模板可以保持更多的时间和空间信息。在三个步态基准数据集上的多组实验表明,与几种最近发表的方法相比,我们的用PEI来训练PEAN模型在跨视角步态识别中取得了具有竞争性的表现。
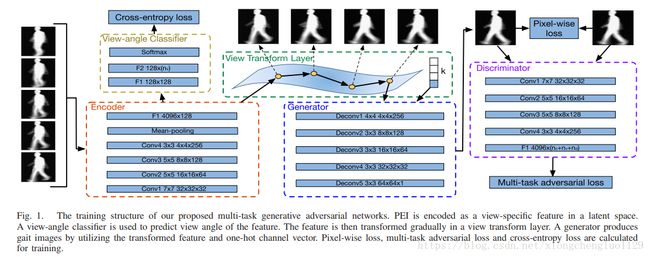
The training structure of the proposed MGANs models is illustrated in Fig. 1. Inspired by the recent success of deep networks for cross-view gait recognition [21], the convolutional neural network is utilized in our model. PEI is first encoded as a view-specific feature in a latent space by the encoder. Then, a view transform layer transforms the feature from one view to another. Finally, a modified GANs structure is trained with both pixel-wise loss and multi-task adversarial loss. In addition, a view-angle classifier is trained with crossentropy loss to predict the view angle of the PEI in the testing phase.
所提出的MGAN模型的训练结构如图1所示。最近深度网络在跨视角步态识别问题上取得了成功,受此[21]启发,我们的模型中也使用了卷积神经网络结构。 PEI首先被编码器编码为隐藏空间中的特定视角特征。紧接着,视图转换层将特征从一个视图转换为另一个视图。 最后,用像素对损失和多任务对抗性损失训练修改后的GAN结构。另外,我们利用交叉熵损失训练视角分类器,以预测测试阶段PEI的视角。(这里测试阶段需要这个PEI视角干什么,会具体说明)
The rest of this paper is organized as follows. Related work is reviewed in Section II. Section III presents the PEI template and explain the proposed MGANs model. Experimental results are analyzed in Section IV. Discussion and conclusion are given in Sections V and VI, respectively.
本文其余部分的组织结构如下。 相关工作在第II节中进行了回顾。 第三节介绍了PEI模板并详解提出的MGAN模型。 实验结果在第IV节中进行分析。 讨论和结论分别在第五节和第六节给出。
II. RELATED WORK
A. Cross-View Gait Recognition
The approaches of cross-view gait recognition can be divided into three categories. The first category devotes to reconstructing the 3D structure of a person through a set of gait images taken from multi-view cameras [22]–[24]. Constrained by the strict environmental requirement and expensive computational cost, however, it is less applicable in practice. The second category is to extract the hand-crafted view-invariant features from gait images to represent a person [25]–[28]. Due to the strong nonlinear relationship between view angles and gait images, extracting such view-invariant features from images is a challenge. As a result, the hand-crafted view invariant features cannot generalize well in the condition of a large view variation [21].
跨视角步态识别的方法可以分为三类。 第一类致力于通过从多视图相机[22] - [24]拍摄的一组步态图像来来重建人的3D结构。 然而,这种方法受到严格的环境要求和昂贵的计算成本的限制,使得它在实践中不太适用。 第二类是从步态图像中提取手工视图不变特征来代表一个人[25] - [28]的步态特征。 由于视角和步态图像之间是极度的非线性关系,从图像中提取这种视图不变特征将会是一个难题。 因此,提取的手工视图变形特征在视图变化情况较大的的情况下不具有很好的泛化性能[21]。
Most of the state-of-the-art methods belonging to the third category directly learn transformations or projections of gaits in different view angles. For example, Makihara et al. [10] proposed a View Transformation Model (VTM) to transform gait templates from one view to another. In their work, Singular Value Decomposition (SVD) was used to compute the projection matrix and view-invariant features for each GEI. Further, a truncated SVD was proposed to overcome the overfitting problem of the original VTM [11]. Moreover, they refined a VTM-based method to learn a nonlinear transformation between different view angles [9] by employing suppor vector regression.
大多数最先进的方法都是属于第三类的,这种方法直接学习不同视角的步态的变换或投影。 例如,Makihara等人[10]提出了一种视图转换模型(VTM),用于将步态模板从一个视图转换为另一个视图。 在他们的工作中,奇异值分解(SVD)用于计算每个GEI的投影矩阵和视图不变特征。与此同时,截断的SVD可以用来克服原始VTM的过度拟合问题[11]。 此外,他们改进了一种基于VTM的方法,通过支持向量回归来学习不同视角之间的非线性变换[9]。
Different from VTM-based methods, Canonical Correlation Analysis (CCA) based approaches project the gait templates from multiple view angles onto a latent space with maximal correlation [5], [8], [12], [29]. For example, Bashir et al. [5] modeled the correlation of gait sequences from different view angles using CCA. Kusakunniran et al. [12] claimed that there might exist some local correlations in GEIs of different view angles. Xing et al. [8] proposed Complete Canonical Correlation Analysis (C3A) to overcome the shortcomings of CCA when directly dealing with two sets of high dimensional features. In their method, the original CCA was decomposed into two stable eigenvalue decomposition problems to avoid inconsistent projection directions between Principle Component Analysis (PCA) and CCA.
与基于VTM的方法不同,基于典型相关分析(CCA)的方法将步态模板从多个视角投影到具有最大相关性的隐藏空间[5],[8],[12],[29]。 例如,Bashir等人 [5]使用CCA来建模来自不同视角的步态序列的相关性。 Kusakunniran等人 [12]声称在不同视角的GEI中可能存在一些局部相关性。 Xing等人[8]提出了使用完全典型相关分析(C3A)来克服CCA在直接处理两组高维特征时的缺点。 在他们的方法中,原始CCA被分解为两个稳定的特征值分解问题,以避免主成分分析(PCA)和CCA之间投影方向不一致的问题。
However, CCA-based methods assume that view angles are known in advance. Therefore, Hu et al. [7] proposed an alternative View-invariant Discriminative Projection (ViDP) to project the gait templates onto a latent space without knowing the view angles.
然而,基于CCA的方法假设视角是预先已知的。 因此,胡等人[7]提出了一种替代的视图不变判别投影(ViDP),在不需要知道视角的情况下,可以将步态模板投影到隐藏空间。
Recently, deep neural networks based gait recognition methods were introduced in [2], [21], and [30]–[32]. The CNN-based method proposed by Wu et al. [21] automatically recognized the discriminative features to predict the similarity given a pair of gait images. The model they used is opaque on how the view variation affects the similarities between different samples. Instead of using silhouette images which are sensitive to the clothing and carrying variations, a posebased temporal-spatial network [2] is proposed to extract dynamic and static information from the key-point of human bodies [33]. The experimental results show that it may be a challenge for a pose-based method to extract discriminative information from key-points of a human body.
最近,基于深度神经网络的步态识别方法在[2],[21]和[30] - [32]中有所介绍。 Wu等人提出的基于CNN的方法 [21]可以自动识别判别特征以预测给定一对步态图像的相似性。 他们使用的模型对于视图变化如何影响不同样本之间的相似性的学习过程是隐式的。 与使用对服装和携带变化敏感的轮廓图像不同,基于姿态的时空网络[2]来从人体的关键点来提取动态和静态信息[33]。 实验结果表明,基于姿势的方法从人体关键点提取判别信息还是一个具有挑战性的任务。
However, there are some shortcomings remained in the existing methods. For example, VTM-based methods suffer from error accumulation stemming from large view variations. CCA-based methods and ViDP only model the linear correlation between features. CNN-based method lacks the interpretability of view variations. In order to overcome these shortcomings, our MGANs model benefits from the feature transformation in a latent space and the nonlinear deep model. Different from directly predicting the similarity given a pair of samples as in [21], our method learns view-specific features by utilizing prior knowledge about the view angles. This greatly facilitates the understanding of the view variation to the learned features
但是,现有方法仍存在一些缺点。 例如,基于VTM的方法中,当视图变化较大时会引起的误差的累积。 基于CCA的方法和ViDP仅模拟特征之间的线性相关性。 基于CNN的方法缺乏视图变化现象的可解释性。为了克服这些缺点,我们提出的MGANs模型主要优点是在隐空间中学习特征变换和采用非线性深度模型。 与[21]中给出的直接预测一对样本相似性不同,我们的方法通过利用有关视角的先验知识来学习特定的视图特征。 这极大地促进了对学习特征的视图变化的理解。
B. Generative Adversarial Networks
Recently, Generative Adversarial Networks (GANs) [34] were introduced as a novel way to model data distributions. Specifically, GANs are a pair of neural networks consisting of a generator G and a discriminator D. In the original GANs, the generator G generates fake data from a distribution of Pz. The goal of the discriminator D is to distinguish fake data from real data x. We assume that the distribution of real data is Pdata. Both the generator and discriminator are iteratively optimized against each other in a minimax game as follows [34]:
最近,Generative Adversarial Networks(GANs)[34]作为一种模拟数据分布的新方法被引入。 具体地,GAN是由生成器G和判别器D组成的一对神经网络。在原始GAN中,生成器G从Pz的分布产生伪数据。 判别器D的目标是区分伪数据和真实数据x。 我们假设实际数据的分布是Pdata。 生成器和判别器都相互迭代优化,minimax优化规则如下所示[34]:
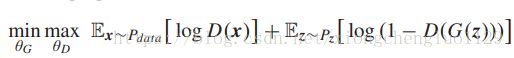
where θG and θD are the parameters of G and D, respectively. However, the training of original GANs suffers from the problems of low quality, instability and mode collapse. Several variants of GANs were thus introduced to solve these problems. For example, WGANs [35], [36] and DCGANs [15] were proposed to improve the stability of training and to alleviate mode collapse.
其中 θ G \theta _{G} θG和 θ D \theta _{D} θD分别是G和D的参数。 然而,原始GAN的训练存在质量低,不稳定和模式崩溃的问题。 因此引入了几种GAN变体来解决这些问题。 例如,WGANs [35],[36]和DCGANs [15]被提出用来提高训练的稳定性和缓解模式崩溃。(我不知道这个 mode collapse到底该怎么翻译)。
Research on original GANs has also focused on utilizing supervised information. For example, conditional GANs [37] was proposed to generate samples by providing label information. Various vision problems such as super-resolution [17] and inpainting [18] were advanced based on conditional GANs.
对原始GAN的研究也集中在利用监督信息f方面。 例如,条件生成式对抗网络 [37]通过提供标签信息来生成样本。 基于条件生成式对抗网络有效的提高了超分辨率[17]和修复[18]等各种视觉问题性能。
Recent researches on GANs are capable of interpolating facial poses or age variations along a low-dimensional manifold [15], [16]. In order to capture the manifold of view angles and model the distribution of gait images, we also introduce the GANs into our model. The structure of GANs in our proposed model is composed of one generator and several subdiscriminators. Each sub-discriminator is responsible to ensure that the generated gait images belong to a certain domain such as a view angle domain, an identity domain, or a channel domain of gait images.
最近对GAN的研究主要是能够沿着低维流形嵌入面部姿势或年龄变化[15],[16]信息。 为了捕捉视角的多样性并对步态图像的分布进行建模,我们也将GAN引入到我们的模型中。 我们提出的模型中的GAN结构由一个生成器和几个子判别器组成。 每个子判别器负责确保所生成的步态图像属于某个域,例如视角域,身份域或步态图像的信道域。
Note that the recently published GaitGAN [38] also introduced the GANs to learn view-invariant features. The proposed two discriminators were used to ensure that the generated gait images are realistic and the identity can be preserved. There are two main differences between their work and ours. The first is that their work directly transformed the gait template from arbitrary view angles to the side view angle without utilizing the assumption of view angle manifold. The second is that the two discriminators proposed in their work are mutually independent, whereas different discriminators will share the weights of the network in our method.
值得注意的是,最近发布的GaitGAN [38]还引入了GAN来学习视图不变特征。 提出的两个判别器用于确保生成的步态图像是真实的并且可以保持身份信息的。 我们之间工作的主要区别有两点。 首先,他们的工作直接将步态模板从任意视角转换为侧视角,而没有利用视角的多样性的假设。 第二,在他们的工作中提出的两个判别器是相互独立的,而在我们的方法中不同的判别器将中共享网络的权重。
III. METHOD
In this section, we first give an overview of our method for cross-view gait recognition. Then, we describe a novel gait template called Period Energy Image (PEI). We also formulate the model of our proposed Multi-task Generative Adversarial Networks (MGANs). Finally, we introduce the objective functions of our methods.
在本节中,我们首先概述我们的跨视图步态识别方法。 然后,我们描述了一种名为周期能量图像(PEI)的新型步态模板。 我们用公式详细解释我们提出的多任务生成对抗网络(MGAN)的模型。 最后,我们介绍了我们方法的目标函数。

A. Method Overview

识别流程如图二所示。给定一个在视角为p的probe模板 x p x^{p} xp和视角为g的n个gallery模板 { x 1 g , x 2 g , . . . , x n g { x_{1}^{g},x_{2}^{g},...,x_{n}^{g} } x1g,x2g,...,xng},gallery模板的n个身份定义为 { y 1 g , y 2 g , . . . , y n g { y_{1}^{g},y_{2}^{g},...,y_{n}^{g} } y1g,y2g,...,yng}。跨视角识别问题的目标就是识别 x p x^{p} xp的身份。步态模板 x p x^{p} xp首先被编码为一个在隐式空间中的特定视角特征 z p = E ( x p ) z^{p}=E(x^{p}) zp=E(xp),其中 E 是一个编码器。然后视角分类器预测probe 和 gallery 模板的视角。继此之后,视图转换层 V 将 z p z^{p} zp 从视图 p转化为视图 g,转换方程为 z g = E ( z p , p , g ) z^{g}=E(z^{p},p,g) zg=E(zp,p,g)。步态模板 x i g x_{i}^{g} xig也被编码为在隐空间的特征 z i p = E ( x i g ) z_{i}^{p}=E(x_{i}^{g}) zip=E(xig),其中, i ϵ { 1 , 2 , . . . , n } i\epsilon \left \{ {1,2,...,n} \right \} iϵ{1,2,...,n}。 x p x^{p} xp 身份用最近邻分类器记做 y i ∗ g y_{i*}^{g} yi∗g,其中,

∥ ∙ ∥ 2 \left \| \bullet \right \|_{2} ∥∙∥2代表2-范数。
B. Period Energy Image
C. Multi-Task Generative Adversarial Network
Our proposed MGANs model consists of five components: an encoder that encodes the gait templates as view-specific features in a latent space, a view-angle classifier that predicts the view angles of the view-specific features, a view transform layer that transforms the view-specific features from one view to another, a generator that generates the gait images from the view-specific features, and a discriminator that discriminates whether the generated gait images belong to certain domains or distributions. In this subsection, we detail each component as follows.
我们提出的MGAN模型由五个部分组成:编码器将步态模板编码为潜在空间中的特定视图特征,视角分类器预测特定视图特征的视角,视图转换层将特定视图特征从一个视图到另一个视图,生成器从特定视图特征中产生步态图像,判别器用来区分生成的步态图像是属于某些域或者特定的分布。 在本小节中,我们按如下方式详细说明每个组件。
1) Encoder:
In order to obtain a view-specific feature for recognition, a convolutional neural network is adopted as the encoder in our model. The structure of the encoder is shown in Fig. 1. The input x u x^{u} xu to the encoder is our proposed PEI template in view angle u. The size of the x u x^{u} xu is 64 × 64 × n c n_{c} nc where n c n_{c} nc is the number of channels in PEI. We use temporal pooling to aggregate temporal information in gait templates. Temporal pooling is commonly used to summarize several video frames into one feature vector in previous literature [41]. In our method, we treat each channel of PEI as one frame and aggregate the temporal information across all channels. Therefore, each channel of PEI is independently fed to the encoder. Mean-pooling is chosen as the implementation of temporal pooling in our method, which is the same as in [41]. We use four convolutional layers followed by batch-normalization layers to build the encoder. Each component in MGANs uses LeakyReLU as the nonlinear activation function. The negative slope of LeakyReLU is set as 0.01. Instead of using the max pooling layer, convolutional layers with a stride size of 2 are adopted. The number of filters is increased by a factor of 2 from 32 to 256.
为了获得用于识别的特定视图特征,我们采用卷积神经网络作为模型中编码器。编码器的结构如图1所示。编码器的输入 x u x^{u} xu 是我们在PEI在视角 u 下的模板。 x u x^{u} xu 的大小是64×64× n c n_{c} nc ,其中 n c n_{c} nc 是PEI中的通道数。我们使用时间池化来聚合步态模板中的时间信息。在以前的文献中,时间池话通常用于将几个视频帧汇总成一个特征向量[41]。在我们的方法中,我们将PEI的每个通道视为一个帧,并在所有通道上聚合时间信息。因此,PEI的每个通道独立地馈送到编码器。选择平均池化作为我们方法中时间池话的一种实现,这与[41]中的相同。我们使用四个卷积层,然后使用batch-normalization层来构建编码器。 MGAN中的每个组件都使用LeakyReLU作为非线性激活函数。 LeakyReLU的负斜率设置为0.01。与最大池化层不同,本方法采用步幅大小为2的卷积层来缩小特征图谱。滤波器的数量从32呈两倍的关系增加,一直到256。
2) View-Angle Classifier:
It should be noted that in the testing phase, the view transform layer requires the view angles of probe and gallery templates. Therefore, we employ a view-angle classifier to predict the view angles of gait templates. As shown in Fig. 1, the classifier consists of two fully connected layers and one softmax layer. The classifier takes the view-specific feature of the gait template as input and predicts its view angle. The prediction task can be seen as a classification problem which viewing each view angle as one class. Since this classifier relies on the effective feature of gait template, we start to train it once other four components (the encoder, the view transform layer, the generator and the discriminator) are done.
应该注意的是,在测试阶段,视图变换层需要probe 和 gallery模板的视角信息。 因此,我们使用视角分类器来预测步态模板的视角。 如图1所示,分类器由两个全连接层和一个softmax层组成。 视角分类器将步态模板的特定视图特征作为输入并预测其视角。 预测任务可以被视为分类问题,其中每个视角视为一个类(CASIA-B中有11个视角,一共11个类)。 由于该分类器依赖于步态模板的有效特征,因此一旦完成其他四个组件(编码器,视图变换层,生成器和判别器),我们就开始训练它。
3) View Transform Layer:
Assuming that gait images with view variations lie on a low-dimensional manifold, samples moving along this manifold can achieve transformation between different view angles while preserving its identity. Therefore, the view transformation from angle u to v can be formulated as:
假设具有视图变化的步态图像位于低维流形上,沿着该流形移动的样本可以实现不同视角之间的变换,同时保持其身份。 因此,从角度u到v的视图变换可以表示为:

where h i h_{i} hi is the view transform vector from view i to i + 1.Different from those methods that transform gait templates intransitional view angles, our model directly transforms views-pecific features in the latent space, which, in turn, reduces the accumulation reconstruction error. Specifically, we implement the view transformation in the form of a fully connected layer without bias parameter. The weight parameter of the fully connected layer is H = [ h 1 , h 2 , . . . , h n v ] H=\left [h_{1},h_{2},...,h_{n_{v}}\right ] H=[h1,h2,...,hnv] , where n v n_{v} nv is the number of views. By properly encoding the view angles u and v as a vector representation e u v = [ e 1 u v , e 2 u v , . . . , e n v u v ] T e^{uv}=\left [e_{1}^{uv},e_{2}^{uv},...,e_{n_{v}}^{uv}\right ]^{T} euv=[e1uv,e2uv,...,envuv]T where e i u v e_{i}^{uv} eiuv , i ϵ { 0 , 1 } i\epsilon \left \{ 0,1 \right \} iϵ{0,1}, the view transformation can be written as :
其中 h i h_{i} hi 是从视图i到i + 1的视图变换矢量。与那些一步一步变换步态模板的方法不同,我们的模型直接在潜在空间中变换特定视图特征,这样反而减少了重建过程中的累积误差。 具体来说,我们以没有偏置参数的全连接层的形式实现视图转换。 全连接层的权重参数是 H = [ h 1 , h 2 , . . . , h n v ] H=\left [h_{1},h_{2},...,h_{n_{v}}\right ] H=[h1,h2,...,hnv],其中 n v n_{v} nv是视图的数量。 通过将视角u和v适当地编码为矢量表示 e u v = [ e 1 u v , e 2 u v , . . . , e n v u v ] T e^{uv}=\left [e_{1}^{uv},e_{2}^{uv},...,e_{n_{v}}^{uv}\right ]^{T} euv=[e1uv,e2uv,...,envuv]T,其中 e i u v e_{i}^{uv} eiuv, i ϵ { 0 , 1 } i\epsilon \left \{ 0,1 \right \} iϵ{0,1},视图变换公式可以写为:

也就是根据视角的跨度大小决定转换层全连接的具体层数,嗯,我是这么理解的。
4) Generator:
The output of the view transform layer is then fed into the generator. The goal of the generator is to generate PEI which is indistinguishable from the real PEI. In our experiments, however, we cannot achieve stable training of GANs to generate PEI due to its high dimensions. We thus randomly select one channel of PEI to address this issue in the training phase. By concatenating z v z^{v} zv and the one-hot representation k of channel label, we define the input of the generator as [ z v z^{v} zv , k], As in Fig. 1, the generator is composed of five deconvolutional layers followed by batch-normalization layers.
然后将视图变换层的输出馈送到生成器中。 生成器的目标是生成与实际PEI无法区分的PEI。 然而,在我们的实验中,由于 PEI 的高维度特性,我们无法稳定训练GAN来产生PEI。 因此在训练阶段,我们通过随机选择一个通道的PEI来解决这个问题。 通过连接 z v z^{v} zv和用one-hot表示的k的通道标签,我们将生成器的输入定义为[ z v z^{v} zv,k],如图1所示,生成器由五个反卷积层后接BN层组成。
5) Discriminator:
The inputs of the discriminator are the generated gait image x v x^{v} xv and the real gait image x ^ v \hat{x}^{v} x^v . It is noted that the view v and the channel label k of xv and x ^ v \hat{x}^{v} x^v are same. In the original GANs model, the output of the discriminator is a scalar which aims to discriminate whether the generated image is real. In MGANs, however, the output of the discriminator is a vector with n v n_{v} nv+ n c n_{c} nc + n d n_{d} nd dimension, where n v n_{v} nv is the number of view angles, n c n_{c} nc is the number of channels in PEI and n d n_{d} ndis the number of subjects in the training set. We assign different tasks to each scalar output of the discriminator. In this way, there are a total of n v n_{v} nv+ n c n_{c} nc + n d n_{d} nd tasks which share the weights of network except for the last layer of the discriminator. The tasks can be concluded as three types as follows. 1) Discriminating whether x v x^{v} xv is in the view v for the first n v n_{v} nv tasks. 2) Discriminating whether x v x^{v} xv satisfies the distribution of gait images in channel k for the next n c n_{c} nc tasks. 3) Discriminating whether x v x^{v} xv preserves the identity information of the input KaTeX parse error: Expected '}', got 'EOF' at end of input: x^{u for the last n d n_{d} nd tasks. In the training phase, the last nd of these tasks are employed to preserve the identity information of the generated images. This is because the real images with certain identity only participate one of the last nd tasks. In the testing phase, we can just use the encoder and the view transform layer to generate viewspecific features.
判别器的输入是生成的步态图像 x v x^{v} xv 和实际步态图像 x ^ v \hat{x}^{v} x^v 。值得注意的是,生成的步态图像 x v x^{v} xv 和实际步态图像 x ^ v \hat{x}^{v} x^v的通道标签和视角是相同的。在原始GAN模型中,判别器的输出是标量,其旨在区分所生成的图像是否是真实的。然而,在MGAN中,鉴别器的输出是具有 n v n_{v} nv+ n c n_{c} nc + n d n_{d} nd维度的向量,其中 n v n_{v} nv是视角的数量, n c n_{c} nc是PEI中的通道的数量, n v n_{v} nv是训练集中的个体的数量。我们为判别器输出的每个标量赋予不同的任务含义。这样,除了最后一层鉴别器之外,总共有共享网络的权重的 n v n_{v} nv+ n c n_{c} nc + n d n_{d} nd个任务。 这些任务可以归结为以下三种类型。
1)在第一个( n v n_{v} nv)任务中,判断 x v x^{v} xv 是否在的视图v中。
2)在下一个 n c n_{c} nc任务中,判断 x v x^{v} xv是否满足的通道k中步态图像的分布。
3)在最后的 n d n_{d} nd任务中,判断 x v x^{v} xv 是否保留了输入 x u x_{u} xu的身份信息。
在训练阶段,使用这些任务的最后一个任务来保存所生成图像的身份信息。这是因为具有特定身份的真实图像仅参与最后的 n d n_{d} nd任务的训练。在测试阶段,我们可以使用编码器和视图变换层来生成特定于视图的特征。(感觉这句话没怎么理解)
D. Objective Function
In our cross-view gait recognition method, three losses are employed as follows:
在我们的跨视角步态识别方法中,采用如下三种损失:
1) Pixel-Wise Loss:
In order to enhance the ability to preserve the identity information in the view-specific features,we first minimize the pixel-wise reconstruction error between the fake images and the real images:
为了增强在特定视图特征中保留个人身份信息的能力,我们首先最小化伪造图像和真实图像之间的像素重建误差:

where ∥ ∙ ∥ 1 \left \| \bullet \right \|_{1} ∥∙∥1 denotes 1-norm. E, V and G represent the encoder, the view transform layer and the generator respectively.
其中, ∥ ∙ ∥ 1 \left \| \bullet \right \|_{1} ∥∙∥1代表 1-范数,E, V 和 G 分别表示编码器, 视图转换层和生成器。
2) Multi-Task Adversarial Loss:
Using the same token as in pixel-wise loss, the networks D, E, V , G can be trained by the following multi-task adversarial loss:
使用与逐像素损失相同的标记,可以通过以下多任务对抗性损失来训练网络D,E,V,G:
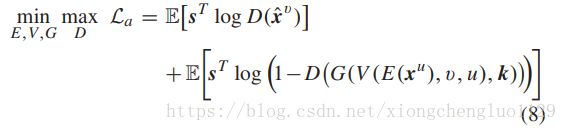
where s ϵ { 0 , 1 } n v + n c + n d s\epsilon \left \{ 0,1 \right \}^{n_{v}+n_{c}+n_{d}} sϵ{0,1}nv+nc+nd is one-hot encoding vector, represented by concatenating the one-hot representation of v, k and the identity of gait image. It is noted that the output of the discriminator is a vector with the same dimension as s and each scalar output corresponds to one adversarial task. Each value in s decides which adversarial tasks the gait images should join in.
其中, s ϵ { 0 , 1 } n v + n c + n d s\epsilon \left \{ 0,1 \right \}^{n_{v}+n_{c}+n_{d}} sϵ{0,1}nv+nc+nd是one-hot编码向量,它是通过将one-hot编码表示v,k和步态能量图身份的向量进行拼接得到的。 值得注意的是,判别器输出的是具有与s相同的维度的向量,并且输出的每个标量对应于一个对抗性任务。 s中的每个值决定步态图像应该参与哪些对抗性任务。
The final objective function of E, V , G and D is described as:
关于E,V,G和D的最终目标函数描述如下:
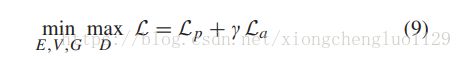
The parameter γ plays a trade-off between the pixel-wise loss and multi-task adversarial loss.
参数γ在像素损失和多任务对抗损失之间进行权衡。
3) Cross-Entropy Loss:
In our method, the view angle prediction is considered as a classification problem. Let C represent the view-angle classifier, then the cross-entropy loss is defined as follows:
在我们的方法中,预测视角被当做分类问题。 设C表示视角分类器,然后交叉熵损失定义如下:
![]()
where u is the one-hot representation of u.
其中,u 是当前人物视角的one-hot编码
IV. EXPERIMENTS
论文中已经写的很详细了。下一步就是总结看源码了。
参考链接:
- Training set,Gallery set 和Probe set的区别:
2.源码地址