《Preservation of the Global Knowledge by Not-True Self Knowledge Distillation in Federated Learning》
《Preservation of the Global Knowledge by Not-True Self Knowledge Distillation in Federated Learning》
Abstract
1⃣️ Federated Learning’s convergence suffers from data heterogeneity.
2⃣️ forgetting could be the bottleneck of global convergence.
3⃣️ Continual Learning: fitting on biased local distribution shifts the feature on global distribution and results in forgetting of global knowledge.
4⃣️ Hypothesize that tackling down the forgetting in local training relives the data heterogeneity.
5⃣️ propose FedLSD(Federated Local Self-Distillation), which utilizes the global knowledge on locally available data.
6⃣️ extend FedLSD to FedLS-NTD, which only considers the not-true class signals to compensate noisy prediction of the global model.
Introduction
Federated Learning: train local models (need most computation), server aggregate local models to a single global model.
Base: FedAvg, heterogeneity is not resolved.
Local data (is not identically distributed) fails to represent the overall global distribution; makes the theoretical analysis difficult and degrades the FL algorithms’ performance.
CL (Continual Learning) causes catastrophic forgetting, because learning on the whole/different tasks.
FedAvg causes catastrophic forgetting(examine), because fitting on the biased local distribution -> forgetting of global knowledge.

tackle down forgetting -> heterogeneity decreased -> consistency increased.
Propose FedLSD
- preserve global knowledge
- local model self-distills the distributed global model’s prediction
FedLS-NTD
- by following not-true class signals noly
Forgetting global knowledge in FL
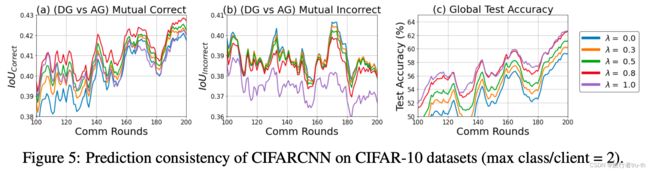
The prediction consistency degrades as data heterogeneity increases (less number of classes per client). As table 1 shows.
I o U c o r r e c t = ∣ D G c o r r e c t ∩ A G c o r r e c t ∣ ∣ D G c o r r e c t ∪ A G c o r r e c t ∣ IoU_{correct} = \frac{|DG_{correct} \cap AG_{correct}|}{|DG_{correct} \cup AG_{correct}|} IoUcorrect=∣DGcorrect∪AGcorrect∣∣DGcorrect∩AGcorrect∣
How the representation on the global distribution changes during local training?
Map CIFAR-10 input data to 2-dimensional vectors and normalize them to be aligned on the unit hypersphere S 1 = { x ∈ R 2 : ∥ x ∥ 2 = 1 } S^{1}=\{x\in \mathbb R^{2}:\Vert x \Vert_2 = 1 \} S1={x∈R2:∥x∥2=1}. Then estimate the probability density function. The global model learned on homogeneous locals (i.i.d.) and heterogeneous locals with different local distributions.
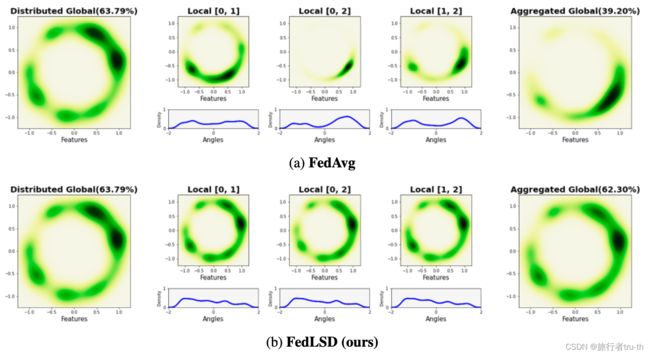
Results show:
FedAvg: The feature vector from global model learned with homogeneous locals are uniformly distributed to hypersphere S 1 S^1 S1. However, after local training, the entire feature region changed. The global model only reflects the feature regions where was dominant in the local models, and the knowledge of unseen classes is forgetten.
FedLSD: Preserving the knowledge on the global distribution prevents forgetting and relives the data heterogeneity problem.
Federated Local Self Distillation

Local self distillation
FedLSD: to preserve the global view on the local data, because the feature shifting occurs by fitting on the biased local distribution.
So, FedLSD conducts local-side self-distillation: using L F e d L S D \mathcal L_{FedLSD} LFedLSD and cross-entropy L C E \mathcal L_{CE} LCE.
L F e d L S D = ( 1 − β ) ⋅ L C E ( q , p y ) + β ⋅ L L S D ( q τ , q τ g ) ( 0 < β < 1 ) (1) \mathcal L_{FedLSD}=(1-\beta) \cdot \mathcal L_{CE}(q, p_y) + \beta \cdot \mathcal L_{LSD}(q_{\tau},q_{\tau}^{g}) (0<\beta<1) \tag{1} LFedLSD=(1−β)⋅LCE(q,py)+β⋅LLSD(qτ,qτg)(0<β<1)(1)
where, { q τ ( c ) = e x p ( z c / τ ) ∑ i = 1 C e x p ( z i / τ ) ; q τ g ( c ) = e x p ( z c g / τ ) ∑ i = 1 C e x p ( z i g / τ ) ; \begin{cases} q_{\tau}(c) = \frac{exp(z_{c}/\tau)}{\sum_{i=1}^{C}exp(z_{i}/\tau)} ;\\ q_{\tau}^{g}(c)=\frac{exp(z_c^g/\tau)}{\sum_{i=1}^Cexp(z_i^g/\tau)}; \end{cases} ⎩⎨⎧qτ(c)=∑i=1Cexp(zi/τ)exp(zc/τ);qτg(c)=∑i=1Cexp(zig/τ)exp(zcg/τ); , L L S D ( q τ , q τ g ) = − ∑ c = 1 C q τ g ( c ) l o g ( q τ ( c ) q τ g ( c ) ) \mathcal L_{LSD}(q_\tau,q_{\tau}^g)=-\sum_{c=1}^Cq_{\tau}^g(c)log(\frac{q_{\tau}(c)}{q_{\tau}^g(c)}) LLSD(qτ,qτg)=−∑c=1Cqτg(c)log(qτg(c)qτ(c))
where q q q, q g q^g qg is the softmax probability of each local client model and global model at last round, and p y p_y py is the one-hot label.
C is the number of the classes
For distillation loss, the logins are divided by τ \tau τ to soften the prediction probability.
L L S D \mathcal L_{LSD} LLSD is the KL-Divergence loss between local prediction and global prediction.
where FedLSD resembles memory-based CL algorithms, which exploits distillation loss to avoid forgetting by preserving the knowledge on old tasks. ->not allowed due to data privacy in FL.
Instead, the global model’s predictions can be utilized as a reference of the previous data distribution to induce a similar effect to that of using the episodic memory in CL.
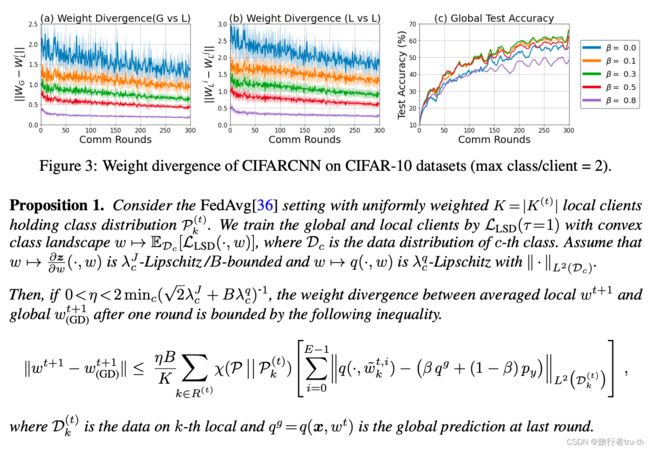
Proposition 1 implies that increasing β \beta β in local objective reduces the weight divergence ∣ ∣ w t − w G D t ∣ ∣ || w^t -w_{GD}^t|| ∣∣wt−wGDt∣∣.
Local self not-true distillation
FedLSD is sub-optimal to prevent forgetting.
1⃣️ noisy global model’s predictions : FL updates with only a few local steps -> noisy -> KD-loss can’t good at tempreture softening -> teacher noisy should use a small temperature.
2⃣️ local information priority issues : information not included in the local distribution should have a higher priority to prevent forgetting.
3⃣️ FedLSD-NTD by distilling the global view on the relationship between not-true classes only.

FedLSD-NTD
L F e d L S D − N T D = ( 1 − β ) ⋅ L C E ( q , p y ) + β ⋅ L N T D ( q ~ τ , q ~ τ g ) ( 0 < β < 1 ) (2) \mathcal L_{FedLSD-NTD}=(1-\beta) \cdot \mathcal L_{CE}(q, p_y) + \beta \cdot \mathcal L_{NTD}(\tilde{q}_{\tau},\tilde{q}_{\tau}^{g}) (0<\beta<1)\tag{2} LFedLSD−NTD=(1−β)⋅LCE(q,py)+β⋅LNTD(q~τ,q~τg)(0<β<1)(2)
where, { q ~ τ ( c ) = e x p ( z c / τ ) ∑ i = 1 , i ≠ y C e x p ( z i / τ ) ; q ~ τ g ( c ) = e x p ( z c g / τ ) ∑ i = 1 , i ≠ y C e x p ( z i g / τ ) ; \begin{cases} \tilde{q}_{\tau}(c) = \frac{exp(z_{c}/\tau)}{\sum_{i=1,i\neq y}^{C}exp(z_{i}/\tau)} ;\\ \tilde{q}_{\tau}^{g}(c)=\frac{exp(z_c^g/\tau)}{\sum_{i=1,i\neq y}^Cexp(z_i^g/\tau)}; \end{cases} ⎩⎨⎧q~τ(c)=∑i=1,i=yCexp(zi/τ)exp(zc/τ);q~τg(c)=∑i=1,i=yCexp(zig/τ)exp(zcg/τ); ( ∀ x ≠ y ) (\forall x\neq y) (∀x=y), L N T D ( q ~ τ , q ~ τ g ) = − ∑ c = 1 , c ≠ y C q ~ τ g ( c ) l o g ( q ~ τ ( c ) q ~ τ g ( c ) ) \mathcal L_{NTD}(\tilde{q}_\tau,\tilde{q}_{\tau}^g)=-\sum_{c=1,c\neq y}^C\tilde{q}_{\tau}^g(c)log(\frac{\tilde{q}_{\tau}(c)}{\tilde{q}_{\tau}^g(c)}) LNTD(q~τ,q~τg)=−∑c=1,c=yCq~τg(c)log(q~τg(c)q~τ(c))
Loss function
L L S D → N T D = ( 1 − β ) ⋅ L C E ( q , p y ) + β ⋅ L ( λ ) \mathcal L_{LSD\to NTD}=(1-\beta)\cdot \mathcal L_{CE}(q,p_y) + \beta \cdot L(\lambda) LLSD→NTD=(1−β)⋅LCE(q,py)+β⋅L(λ)
where L ( λ ) = ( 1 − λ ) ⋅ L L S D ( q τ , q τ g ) + λ ⋅ L N T D ( q τ ~ , q ~ τ g ) L(\lambda) = (1-\lambda) \cdot \mathcal L_{LSD}(q_{\tau},q_{\tau}^g) + \lambda \cdot \mathcal L_{NTD}(\tilde{q_{\tau}},\tilde{q}_{\tau}^g) L(λ)=(1−λ)⋅LLSD(qτ,qτg)+λ⋅LNTD(qτ~,q~τg)
to improve the performance of the global model, an aggregated model should
1⃣️ preserve the correct prediction
2⃣️ discard the incorrect prediction of the previous global model.
Experiment
We evaluate our FedLSD and FedLS-NTD on various FL scenarios with data heterogeneity.
Performance on data heterogeneous FL scenarios
Compare the algorithms on different datasets to validate the efficacy of the proposed algorithms.
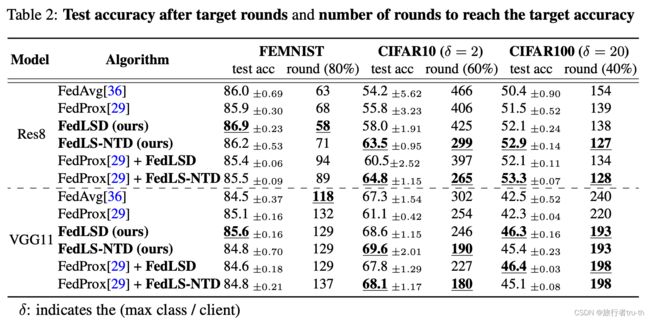
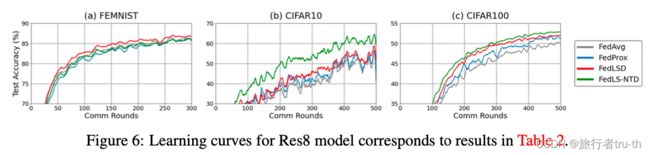
While FedLS-NTD generally performs better than FedLSD, the performance gap varies depending on the datasets and model architectures. We analyze that since FedLS-NTD learns not-true class relationships only, FedLSD may perform better when the prediction noise of the global model is not significant. We suggest that FedLS-NTD is more effective when the intensity of data heterogeneity is high, thereby following the global model possesses more risk to have biased distribution. For example, in FEMNIST datasets, almost all classes are included in the local data, but the hand-written data that belongs to the same class have different forms across the clients. In this case, FedLSD and FedLS-NTD show slow convergence in the early phase while they improve the final test accuracy.
We further investigate the performance by varying the data heterogeneity (Table 3) and sampling ratio (Table 4). The results show that the proposed algorithms significantly outperform the baselines in data heterogeneity cases.

Preservation of global knowledge
To empirically measure how well the global knowledge is preserved after local training, we examine the trained local models’ test accuracy on global distribution (Figure 7). If fitting on the local distribution preserves global knowledge, the trained local models could generalize well on the global distribution.
