【神经网络】深度学习训练时GPU显存不足 & 浮点数在计算机中的存储 & 大小端字节序 & 内存对齐
文章目录
- 问题描述
- 解决方法
- 浮点数在计算机中的存储
- 大端字节序 和 小端字节序
- 内存对齐
- 参考链接
问题描述
2020-07-20 10:48:49.753261: W tensorflow/core/common_runtime/bfc_allocator.cc:439] ****************************************___**____***************************************____________
2020-07-20 10:48:49.753329: W tensorflow/core/framework/op_kernel.cc:1753] OP_REQUIRES failed at cudnn_pooling_gpu.cc:140 : Resource exhausted: OOM when allocating tensor with shape[1098,16,128,128,3] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
tensorflow.python.framework.errors_impl.ResourceExhaustedError: OOM when allocating tensor with shape[1098,16,128,128,3] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[{{node gradients/max_pooling3d/MaxPool3D_grad/MaxPool3DGrad}}]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "testCNN.py", line 208, in <module>
_, mean_loss_val = sess.run([optimizer, mean_loss], feed_dict=train_feed_dict)
File "/root/caozx/22-anaconda3/envs/tensorflow/lib/python3.5/site-packages/tensorflow/python/client/session.py", line 958, in run
run_metadata_ptr)
File "/root/caozx/22-anaconda3/envs/tensorflow/lib/python3.5/site-packages/tensorflow/python/client/session.py", line 1181, in _run
feed_dict_tensor, options, run_metadata)
File "/root/caozx/22-anaconda3/envs/tensorflow/lib/python3.5/site-packages/tensorflow/python/client/session.py", line 1359, in _do_run
run_metadata)
File "/root/caozx/22-anaconda3/envs/tensorflow/lib/python3.5/site-packages/tensorflow/python/client/session.py", line 1384, in _do_call
raise type(e)(node_def, op, message)
tensorflow.python.framework.errors_impl.ResourceExhaustedError: OOM when allocating tensor with shape[1098,16,128,128,3] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[node gradients/max_pooling3d/MaxPool3D_grad/MaxPool3DGrad (defined at testCNN.py:188) ]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
Errors may have originated from an input operation.
Input Source operations connected to node gradients/max_pooling3d/MaxPool3D_grad/MaxPool3DGrad:
conv3d/Relu (defined at testCNN.py:98)
max_pooling3d/MaxPool3D (defined at testCNN.py:108)
解决方法
笔者将 float 32 改为 float 16 ,可以运行,不过这种办法也会导致精度的损失。
浮点数在计算机中的存储
详见 浮点类型(float、double)在内存中如何存储? 待整理
要表示浮点数,关键是小数如何使用二进制表示。
二进制表示整数时,最低位代表2的0次方,往高位依次是2的1次方,2次方,3次方……那么对应的,二进制数小数点后面,最高位则是2的-1次方,-2次方,-3次方……如下图所示:


浮点数有精度问题。因为这种二进制表示小数的方法,造成了一个隐含的问题:一些本来不是无限循环的十进制小数,表示成二进制之后成了无限循环小数。比如上图中的十进制数字0.6,表示成二进制之后成了循环体为1001的无限循环小数。这就是“浮点数有精度问题”的根源之一,你在代码中声明一个变量double a = 0.6;时,计算机底层其实是无法精确存储那个无限循环二进制数的,只能存一个四舍五入(准确说应该是零舍一入,毕竟是二进制)后的近似值。
将二进制表示为以2为底的科学计数法,如图:

对于任何数字表示成二进制科学计数法以后,一定是1点几(尾数)乘以2的多少次方(指数)。对于小于零的负数来说,就是负1点几(尾数)乘以2的多少次方(指数)。所以要存这个数,需要存储三个部分:正负号,尾数,指数。



大端字节序 和 小端字节序
详见 理解字节序 。
计算机硬件有两种储存数据的方式:大端字节序(big endian) 和 小端字节序(little endian) 。举例来说,数值0x2211使用两个字节储存:高位字节是0x22,低位字节是0x11。
- 大端字节序:高位字节在前,低位字节在后,这是人类读写数值的方法。
- 小端字节序:低位字节在前,高位字节在后,即以0x1122形式储存。
比如,0x1234567的大端字节序和小端字节序的写法如下图。
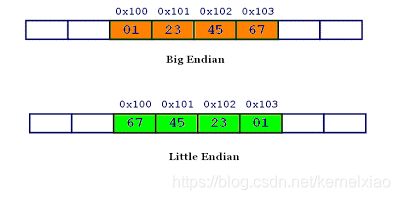
为什么会有小端字节序?
答案是,计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。但是,人类还是习惯读写大端字节序。所以,除了计算机的内部处理,其他的场合几乎都是大端字节序,比如网络传输和文件储存。
计算机处理字节序的时候,不知道什么是高位字节,什么是低位字节。它只知道按顺序读取字节,先读第一个字节,再读第二个字节。如果是大端字节序,先读到的就是高位字节,后读到的就是低位字节。小端字节序正好相反。
字节序的处理,"只有读取的时候,才必须区分字节序,其他情况都不用考虑。"
处理器读取外部数据的时候,必须知道数据的字节序,将其转成正确的值。然后,就正常使用这个值,完全不用再考虑字节序。即使是向外部设备写入数据,也不用考虑字节序,正常写入一个值即可。外部设备会自己处理字节序的问题。
举例来说,处理器读入一个16位整数。如果是大端字节序,就按下面的方式转成值。
x = buf[offset] * 256 + buf[offset+1];
上面代码中,buf是整个数据块在内存中的起始地址,offset是当前正在读取的位置。第一个字节乘以256,再加上第二个字节,就是大端字节序的值,这个式子可以用逻辑运算符改写。
x = buf[offset]<<8 | buf[offset+1];
上面代码中,第一个字节左移8位(即后面添8个0),然后再与第二个字节进行或运算。
如果是小端字节序,用下面的公式转成值。
x = buf[offset+1] * 256 + buf[offset];
32位整数的求值公式也是一样的。
/* 大端字节序 */
i = (data[3]<<0) | (data[2]<<8) | (data[1]<<16) | (data[0]<<24);
/* 小端字节序 */
i = (data[0]<<0) | (data[1]<<8) | (data[2]<<16) | (data[3]<<24);
内存对齐
内存对齐可以提高CPU读取数据的效率。
详见 C/C++内存对齐详解 - 忆臻的文章 - 知乎
//32位系统
//gcc默认是#pragma pack(4),并且gcc只支持1,2,4对齐
#include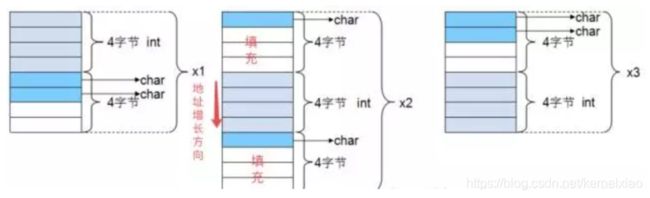
参考链接
CNN卷积神经网络训练时占多少显存(GPU)的计算
深度神经网络模型训练时GPU显存不足怎么办?
科普帖:深度学习中GPU和显存分析
tensorflow读取训练数据方法
浮点数在计算机中是如何存储的?
浮点类型(float、double)在内存中如何存储?
理解字节序
C/C++内存对齐详解 - 忆臻的文章 - 知乎
带你深入理解内存对齐最底层原理 - 张彦飞的文章 - 知乎