德育知识元素挖掘系统设计 软件工程 spring boot + Vue.js + python机器学习
第一章 绪论
-
- 摘要
当今社会发展迅速,机器学习相关技术快速在各行各业普及,制作数据挖掘系统的需求日益增长。同时,随着社会发展不断推进,对学生进行德育教育的规模越做越大,成为了教育行业发展的一大趋势。对于较大规模的系统,传统的纸笔和文件系统记录和分析学生德育教育数据已经无法满足大数据时代成千上万学生德育教育信息的管理和维护。因此,为教育行业从业人员定制一款基于Web系统的德育元素挖掘系统成为了迫在眉睫的任务。
本项目开发了一款基于Spring Boot和Vue.js框架的德育元素挖掘系统,其中数据挖掘模块使用Python实现。功能涵盖登录、学生信息管理、学生德育教育元素挖掘模块,充分体现了互联网信息系统中软件工程的思想方法。
项目前端以网页的形式呈现,可以在主流浏览器中流畅运行。后端采用Java语言编写,使用MySQL数据库存储系统相关的数据信息。德育数据挖掘模块使用Python的NumPy、pandas、sklearn库实现。采用了良好的设计模式,易于维护,可扩展性好,在不同操作系统和浏览器中适应性强,体现了软件工程的开发思想。
-
- 研究背景和研究意义
近年来教育行业的快速发展,促成了互联网应用的巨大规模和快速发展趋势。当今时代,大数据和我们生活息息相关,涉及到工业生产和人民生活的方方面面。但是,在德育信息挖掘系统规模越来越大、学生信息越发复杂、日志越来越难以记录的情况下,如何更好地进行高效分析、搭建一个新的系统,成为了近年来国内外许多研究人员正在不断探究的一个新课题。
为了解决这一问题,新的德育信息挖掘系统,尤其是在Web端基于Spring Boot的德育信息挖掘系统的发展极为迅速。通过不断完善德育信息挖掘系统,教育从业人员可以逐步实现越来越好的学生信息管理,减少了信息的不对称性,提升了资源的利用效率,人们也逐步开始解决这一困扰大家的难题。
21世纪以来,随着互联网技术的快速发展,计算机逐渐普及到企业中每个人的办公桌上。本项目针对德育信息挖掘的问题,设计并实现了基于Spring Boot框架的Web服务器和基于Vue.js框架的网页,用户通过Web浏览器登录系统,将学生信息和德育教育信息录入并保存在阿里云云端服务器中,并且可以与教育系统内其他人员共享和维护记录,减少人员流动成本。因此,开发一款德育信息挖掘系统对于学生德育教育相关领域实际生产的需要具有重要的意义,有广泛的应用前景。
第二章 技术介绍
-
- Java 和Java Web
Java 是一门面向对象的编程语言,也是一门非常强大的语言。Java语言作为静态面向对象编程语言的代表,极好地实现了面向对象理论,允许程序员以优雅的思维方式进行复杂的编程。Java具有简单性、面向对象、分布式、健壮性、安全性、平台独立与可移植性、多线程、动态性等特点。Java可以编写桌面应用程序、Web应用程序、分布式系统和嵌入式系统应用程序等。
Java Web是用Java技术来解决相关Web互联网领域的技术栈。Web包括:Web服务端和Web客户端两部分。Java在服务器端的应用非常的丰富,如Servlet,JSP、第三方框架等等。Java技术对Web领域的发展注入了强大的动力。
-
- Spring Boot
Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。通过这种方式,Spring Boot致力于在蓬勃发展的快速应用开发领域(rapid application development)成为领导者。
SpringBoot基于Spring4.0设计,不仅继承了Spring框架原有的优秀特性,而且还通过简化配置来进一步简化了Spring应用的整个搭建和开发过程。另外SpringBoot通过集成大量的框架使得依赖包的版本冲突,以及引用的不稳定性等问题得到了很好的解决。
SpringBoot所具备的特征有:
(1)可以创建独立的Spring应用程序,并且基于其Maven或Gradle插件,可以创建可执行的JARs和WARs;
(2)内嵌Tomcat或Jetty等Servlet容器;
(3)提供自动配置的“starter”项目对象模型(POMS)以简化Maven配置;
(4)尽可能自动配置Spring容器;
(5)提供准备好的特性,如指标、健康检查和外部化配置;
(6)绝对没有代码生成,不需要XML配置。
-
- Vue.js
Vue (读音 /vjuː/,类似于 view) 是一套用于构建用户界面的渐进式JavaScript框架。与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用。Vue 的核心库只关注视图层,不仅易于上手,还便于与第三方库或既有项目整合。另一方面,当与现代化的工具链以及各种支持类库结合使用时,Vue 也完全能够为复杂的单页应用(SPA)提供驱动。
Vue.js是一套构建用户界面的渐进式框架。与其他重量级框架不同的是,Vue采用自底向上增量开发的设计。Vue 的核心库只关注视图层,并且非常容易学习,非常容易与其它库或已有项目整合。另一方面,Vue 完全有能力驱动采用单文件组件和Vue生态系统支持的库开发的复杂单页应用。
Vue.js 的目标是通过尽可能简单的 API 实现响应的数据绑定和组合的视图组件。
Vue.js 自身不是一个全能框架——它只聚焦于视图层。因此它非常容易学习,非常容易与其它库或已有项目整合。另一方面,在与相关工具和支持库一起使用时,Vue.js 也能驱动复杂的单页应用。
-
- Python、NumPy、pandas、sklearn
Python由荷兰数学和计算机科学研究学会的吉多·范罗苏姆 于1990 年代初设计,作为一门叫做ABC语言的替代品。Python提供了高效的高级数据结构,还能简单有效地面向对象编程。Python语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的编程语言,随着版本的不断更新和语言新功能的添加,逐渐被用于独立的、大型项目的开发。
Python解释器易于扩展,可以使用C语言或C++(或者其他可以通过C调用的语言)扩展新的功能和数据类型。Python 也可用于可定制化软件中的扩展程序语言。Python丰富的标准库,提供了适用于各个主要系统平台的源码或机器码。
NumPy(Numerical Python)是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix)),支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
Scikit-learn(也称为sklearn)是针对Python 编程语言的免费软件机器学习库。它具有各种分类,回归和聚类算法,包括支持向量机,随机森林,梯度提升,k均值和DBSCAN,并且旨在与Python数值科学库NumPy和SciPy联合使用。
-
- MySQL
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,属于 Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
MySQL是一种关系型数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
MySQL所使用的 SQL 语言是用于访问数据库的最常用标准化语言。MySQL 软件采用了双授权政策,分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发都选择 MySQL 作为网站数据库。
-
- Spring Security
Spring Security 基于 Spring 框架,提供了一套 Web 应用安全性的完整解决方案。一般来说,Web 应用的安全性包括用户认证(Authentication)和用户授权(Authorization)两个部分。用户认证指的是验证某个用户是否为系统中的合法主体,也就是说用户能否访问该系统。用户认证一般要求用户提供用户名和密码。系统通过校验用户名和密码来完成认证过程。用户授权指的是验证某个用户是否有权限执行某个操作。在一个系统中,不同用户所具有的权限是不同的。比如对一个文件来说,有的用户只能进行读取,而有的用户可以进行修改。一般来说,系统会为不同的用户分配不同的角色,而每个角色则对应一系列的权限。
在 Web 应用开发中,安全一直是非常重要的一个方面。从应用开发的第一天就应该把安全相关的因素考虑进来,并在整个应用的开发过程中。
第三章 开发配置
-
- 硬件
- CPU:Intel Core i7 Gen 11
- 显卡:NVIDIA RTX 3060
- 内存:16GB
- 软件
- 操作系统:Windows 10
- 后端集成开发环境:Intellij IDEA Ultimate 2020.2
- 前端集成开发环境:Visual Studio Code
- Python集成开发环境:PyCharm Professional 2021.2、Jupyter Notebook
- Python版本:Python 3.8
- 浏览器:Google Chrome
- 数据库:MySQL 8.0.12
第四章 挖掘算法
4.1分析与思路
本项目需要分析德育知识教育信息的类别,因此要求从互联网上的公开资源中获取德育教育相关的文本信息,并对这些信息使用数据挖掘的方法分析其中隐含的特征。注意到德育教育文本信息的类别需要开发人员自己指定,因此决定针对不同的文本,将类别作为监督学习的目标值,而对其他的文本信息,将这些数据进行量化,作为模型的特征值,并通过机器学习的算法建立和训练模型。得到模型后,就可以将模型保存在服务器中,方便Java Web后台调用,输出类别信息了。
数据挖掘的流程图如图4-1所示。
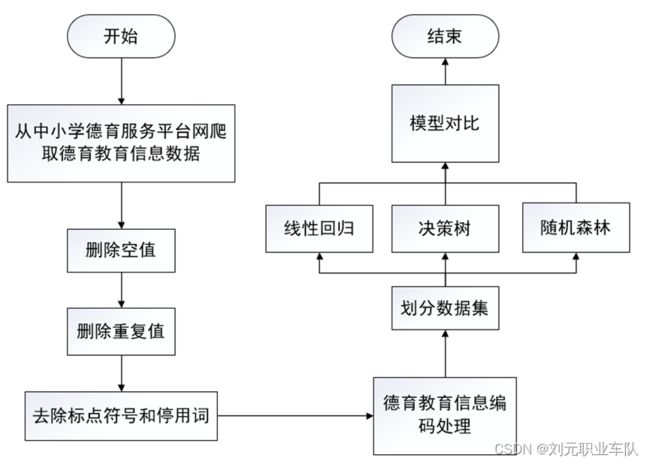
图 4-1 流程图
4.2获取数据
本项目从中小学德育服务平台网(http://www.deyuschool.cn/)上搜索各种类型的德育信息数据,发现其中可用的信息包括大量德育教育相关的文本。运用计算机网络的爬虫技术,从中小学德育服务平台网上爬取了上述信息,整理成1个csv数据集文件,以待分析。网络爬虫是利用一定的规则,自动地抓取互联网信息的程序或脚本。通过Request和Response和原理获取页面信息。浏览器就发送消息给该网址所在的服务器,这个过程叫做HTTP Request。服务器收到浏览器发送的消息后,能够根据浏览器发送消息的内容做出相应的处理,然后把消息回传给浏览器,这个过程叫做HTTP Response。浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后展示。可以利用Request编写程序,模拟请求,然后请求响应,就可以从HTML中获取想得到的数据[1]。
将数据赋予对应的类别,如“思想政治教育”、“品德教育”、“法律常识教育”等等,保存在表格中。
4.3数据预处理
原始数据是从中小学德育服务平台网,即互联网的公开数据中直接通过爬虫得到的,由于网络不可避免地存在延迟,网页上的元素信息存在误差、部分位点可能会出现问题,导致数据中存在异常值、空值等无意义数据,这些数据可能会影响某些变量的评分,甚至影响模型的准确性。为使各变量的数据集具有可用性,应在进行变量筛选前,对原始数据进行预处理,使异常数据和缺失数据得以有效去除。
4.3.1数据缺失值处理
多数情况下,通过网络爬虫方法采集的样本中会出现数据缺失的现象。造成该现象的原因可能是网页的元素标签和属性名未被网页前端开发的程序员设计成完全统一的样式,也可能是网页上本来就有某些数据存在缺失的问题。统计学中将数据缺失记录称为不完全观测,这类数据缺失会对模型的训练过程和预测结果产生较大的影响。因此需要对含有空值的变量数据进行缺失数据处理。
常见的缺失数据的处理规则包括数据插补法、删除法等。数据插补法是对缺失数据进行统计学补充,包括统计量填充、插值法填充等。对于本项目观测数据的缺失,使用“Unknown”字符串填充空值。这样,数值型数据的空值记录不会过多影响后续模型训练的效果,字符串型数据填充的“Unknown”字符串会经过后续的编码转换,变成一个新的变量,使得空字符串也成为影响目标值的其中一个因素。
4.3.2异常数据处理
除缺失数据外,采集样本过程中还可能出现重复生成同一样本的数据异常现象。在样本的采集过程中,由于网络可能存在延迟,爬虫的程序不能准确地每个待提取特征的网页都只提取一次,往往会出现样本重复的现象。所以,本文检查了样本中是否存在重复行。
对样本的部分属性进行了处理,将整个表格进行重复值删除的操作,以删除与其中某一行完全相同的其他行;再将整个表的转置矩阵逐行遍历进行删去操作,最后将所得矩阵再转置,得到删除变量后的数据集,以删除与其中某一列完全相同的其他列。
4.4自然语言处理
中小学德育服务平台网上的德育教育信息数据是自然语言。因此,决定使用自然语言处理(NLP)[2]相关的技术处理德育教育信息。
4.4.1 去除标点符号
去除标点符号是自然语言处理中较为简单的一个操作。查找了爬取的文本数据中的英文标点符号(.,!?等)和中文标点符号(。,!?等),并将这些标点符号以空格代替。不使用简单删除的方法,因为前后两句或一句之间的不同分句之间有可能形成本不该存在的词汇,这可能使得数据增加一些噪声点,影响后续训练的模型性能及其准确性。
4.4.2 分词
中文自然语言处理过程中,分词是必不可少的一项操作。中文具有不同于英文、法文、韩文等其他语言的一大特点,即词语和词语之间没有空格标记,这对于计算机而言是理解中文文本的一个不小的障碍。如果简单地只以每个字或Unicode字符为单位进行编码,无法准确地提取中文文本中词语和语素及其前后语序之间可能存在的特征。因此,将文本进行分词操作。使用中文语料库相关的开源数据集,将中文文本中常出现的所有名词、动词、形容词、介词等语素均进行分隔。例如,“红色文化承载共产党人的初心使命 为中国人民谋幸福 为中华民族谋复兴是党的初心和使命 也是红色文化的前进方向和根本主题”这条信息,经过分词操作后,转换为“红色 文化 承载 共产党 人 的 初心 使命 为 中国 人民 谋 幸福 为 中华民族 谋 复兴 是 党 的 初心 和 使命 也 是 红色 文化 的 前进 方向 和 根本 主题”。这样,后续的编码转换就容易地多,也有效地多了。
4.4.3 去除停用词
在自然语言处理的很多领域,如数据挖掘、信息检索中,为了节省机器运算需要的性能、计算机内存的存储空间和提高模型训练的准确度,在处理自然语言文本时,应该过滤掉某些字或词语。英文文本中的“the”、“is”、“a”等词语,以及中文文本中的“的”、“得”、“了”等字词出现的频率很高,对于模型理解文本而言没有实际意义。因此,从互联网的开源语料库中获取了中文和英文的停用词,对德育教育信息文本中的这些词进行了删除处理。
4.4.4 编码
将德育信息文本进行上述处理后,将所有英文字母均转为小写,然后,将这些处理好的数据进行编码。统计文本中各个词语出现的次数,将这些文本中划分好的词语转换为词频矩阵。然后,使用这些词频信息,计算每个句子中每个词的TF-IDF (Term Frequency-Inverse Document Frequency,词频-逆向文件频率)[3]值。TF-IDF是一种加权技术,常用于自然语言处理相关的数据挖掘任务中。其中,TF指词频,IDF指逆文本频率指数。TF-IDF值的作用是统计某个词对于一句话或一篇文章在整个文本集合中的重要程度。在每条德育教育信息中,一个字或词语的重要性随着在德育教育信息句子中出现的次数而减少。如果某个词语在一条文本信息中出现的频率(即TF)高,并在其他大多数文本信息中出现频率较小,那么认为这个词语可以显著地区分这条文本信息所属的类别。如果包含一个词语的文本越少,这个词的IDF就越大。一个词语的TF-IDF值等同于这个词的TF值乘以这个词的IDF值。
将转换后的句子以每个词为单位进行one-hot编码,并将每个1值替换为这一列对应的词语的TF-IDF值。保存上述矩阵,准备下一步建模。
4.5建模
经过数据的预处理,获得了一个TF-IDF值组成的特征矩阵,以及一个包含各种文本信息所属类别的表格。将两个表格按相同的ID合并,形成一张更大的表格,这个新表格包含着爬取的数据的全部特征。将这个表格的所有文本赋予类别,将类别数据设置为监督学习的目标值,将其他数据设置为特征值。然后,将数据按行打乱,按照90%:10%的比例划分为训练集和测试集。
按照9:1的比例划分数据后,选择多个模型进行训练。为使模型的预测性能更好,使用了交叉验证和网格搜索的方法对模型中的参数进行优化。网格搜索是一个反复训练和结果比较的过程,需要设置给定参数值的搜索方法,通过对指定的参数输入模型并分别进行模型训练和验证,得到最优的一组参数和对应的模型。
首先,用训练集中的数据对线性回归模型进行训练。多元线性回归的优势在于它更加简单和方便。在使用的模型和数据相同的情况下,通过标准的统计方法可以计算出唯一结果。同时回归分析可以准确地计量各个因素之间的相关程度与回归拟合程度的高低,提高预测方程式的效果。但在现实世界中,变量间呈线性关系的很少,因此线性回归算法在某种程度上存在不可测性。通过对准确率的求取,可以发现线性回归的准确率值只有0.69,精度有所欠缺。
接着,采用决策树训练模型。使用gini系数作为选择特征的标准,叶子结点需要的最小样本数设置为1,不设置最大叶子节点数和最大深度。由于单棵决策树的性能始终有限,因此经过调参,准确率值最高只能达到0.73,还不满足预期的需求。
最后,使用随机森林进行模型训练。本文对随机森林中的四个重要参数分别是N Estimators, Max Depth, Min Samples Leaf, Min Samples Split,选择范围进行网格搜索,以选出最好的一个随机森林模型。随机森林的参数N Estimators取值范围设置为[70, 90, 110, 130],Max Depth选择range(10, 17)区间,Min Samples Leaf设置为[1, 2, 3],Min Samples Split设置为[2, 3, 4],将这些参数带入到函数中进行训练。通过循环不断选取某一种参数组合,通过测试集计算准确率。当准确率值最大时,将该树的参数暂存,作为暂优解。当将所有组合的准确率值计算完毕后,获得最优组合,即当随机森林的参数为表4-1中的值时,拟合效果达到最好。
表4-1 最佳拟合效果对应随机森林各参数取值
| 参数 |
最优取值 |
| N Estimators |
90 |
| Max Depth |
15 |
| Min Samples Leaf |
1 |
| Min Samples Split |
3 |
根据上表中参数组合计算得到的准确率值为0.79。
4.6 模型对比
为了进一步验证三个预测模型的合理性及准确性,本文对所述的三种方法分别进行了对比分析,除拟合优度指标准确率外,Precision、Recall与F1-score也作为评价模型预测性能重要的指标进行对比,如表4-2所示。
表4-2 三个方法的指标结果对比
| 线性回归 |
决策树 |
随机森林 |
|
| 准确率 |
0.69 |
0.73 |
0.79 |
| Precision |
0.66 |
0.74 |
0.77 |
| Recall |
0.61 |
0.66 |
0.73 |
| F1-score |
0.62 |
0.68 |
0.76 |
通过上表,可以对比得出德育知识元素对类别的预测效果。随机森林的预测性能最好,决策树次之,多元线性回归最差。这是由于在大量样本数据的情况下,随机森林算法能够最大程度上避免陷入局部最优解,同时能准确求得全局最优解。此外,随机森林还有能处理高维特征输入样本、能够评估各个特征的重要性等优点。
综上可以看出,随机森林算法在本项目中取得了不错的表现,预测结果比较贴近实际情况。
第五章 需求分析和系统设计
-
- 需求分析
为了确定德育信息挖掘系统开发方向,需要对系统进行需求分析,确定德育信息挖掘系统需要开发的功能。好的需求分析可以减少返工时间和代码修改时间。因此,系统需求分析应谨慎进行。
在系统需求分析阶段,开发人员通过对教育行业从业人员进行走访和资料采集,了解到人员之间的沟通交流仅通过语言、短信传输的方式进行,沟通起来比较麻烦,并且不同的人员之间掌握的资料都不相同,资料的整合变得相当困难。开发者通过对各个人员之间掌握的数据和调查结果进行归纳和收集,为本系统得到了构建一个德育信息挖掘系统的基本要求。
本次课题设计和实现的德育信息挖掘系统,其主要思想是将学生德育信息管理的日常工作流程化,展示德育信息挖掘系统的人机界面,让用户操作界面上的员工信息与后台程序进行数据交互,后台程序将进行修改的记录上传至服务器,并实时返回和显示操作结果。本系统的实现,使得教育行业从业人员工作成本大大减少,实现了远程办公。
-
- 用例分析
表5-1 登录用例分析
| 项目 |
描述 |
| 用例名称 |
登录 |
| 前置条件 |
无 |
| 基本流 |
|
| 其他事件流 |
无 |
| 分支与异常 |
若系统读取用户名或密码错误,则报告异常 若用户被禁用,则报告异常 |
| 后置条件 |
无 |
表5-2 德育信息挖掘用例分析
| 项目 |
描述 |
| 用例名称 |
德育信息挖掘 |
| 前置条件 |
登录 |
| 基本流 |
|
| 其他事件流 |
无 |
| 分支与异常 |
无 |
| 后置条件 |
无 |
表5-3 学生管理用例分析
| 项目 |
描述 |
| 用例名称 |
学生管理 |
| 前置条件 |
登录 |
| 基本流 |
|
| 其他事件流 |
无 |
| 分支与异常 |
输入的数据不符合规范,报告异常 输入的信息包括空值,报告异常 |
-
- 用例图
在需求分析阶段,借助统一建模语言(UML)用例图,可以实现对软件产品线需求的明确描述[4]。在面向对象程序设计中,UML常用于软件的说明、设计、分析和功能可视化展示,独立于具体的面向对象开发语言。用例图展示了软件使用过程中用户和系统各功能之间详细的交互形式,以便于后期设计和编码阶段中,让设计人员和开发人员清楚地获知系统的用户、用例以及它们之间的关系。
为了更形象地体现德育信息挖掘系统具备的功能,这里将每个功能通过用例图的方式体现出来。如下图所示。

图5-1 用例图
-
- E-R图
在软件设计中,实体-关系图(E-R图)常用于描述软件系统后台存储在数据库中的信息的类型和它们之间的关系[5]。人员需要使用德育信息挖掘系统将每一条学生信息记录上传到表中,也要为每一个学生添加学习记录。系统需要保存学习的德育知识的记录,使用训练好的模型进行分类。这可以归纳成为以下的实体、属性以及它们的关系,实体-关系图的绘制结果如下图所示。

图5-2 E-R图
-
- 时序图
通常使用UML时序图展示用户和对象间交互操作的顺序和业务流程[6]。时序图横向的小人表示参与者,长方形表示对象,纵向排列的箭头按照时间顺序进行箭头上描述的行为,可以清晰直观地描述系统业务之间的顺序。

图5-3 时序图
第六章 软件质量要求
-
- 功能测试
本章节聚焦于对系统的测试工作。在编码的过程中或者编码完成后,通常需要对系统进行测试,以验证预期的功能是否正确实现。本次测试采用黑盒测试的方法进行。测试分为验证功能是否实现和性能是否满足条件两个部分。
测试的目的在于查找到隐藏在系统中的潜在问题,原则上是找出越多的问题,说明测试得越成功。因此,想要尽量减少代码返工的问题,最好在写完代码后进行单元测试,提前把能解决的问题先解决好。这样不仅可以减少测试工作量,也可以避免系统集成后问题定位困难,导致开发成本高的问题。
表6-1 用户登录测试用例
| 测试需求 |
输入/动作 |
输出/响应 |
| 登录功能 |
未被禁用的用户输入正确账号,输入正确密码,点击登录按钮 |
登录成功 |
| 被禁用的用户输入正确账号,输入正确密码,点击登录按钮 |
登录失败 |
|
| 用户输入错误账号,输入正确密码,点击登录按钮 |
登录失败 |
|
| 用户输入正确账号,输入错误密码,点击登录按钮 |
登录失败 |
表6-2 德育信息挖掘测试用例
| 测试需求 |
输入/动作 |
输出/响应 |
| 输入一条德育信息 |
输入一条德育信息 |
输出所属类别 |
| 输入一条异常的空值德育信息 |
输出异常 |
表6-3 学生管理测试用例
| 测试需求 |
输入/动作 |
输出/响应 |
| 查询学生信息 |
输入或选择属性进行查询 |
输出查询结果 |
| 添加学生信息 |
输入属性进行添加 |
添加成功 |
| 输入空的属性进行添加 |
添加失败 |
|
| 删除学生信息 |
删除一个学生 |
删除成功 |
| 修改学生信息 |
输入属性进行修改 |
修改成功 |
| 输入空的属性进行修改 |
修改失败 |
-
- 系统运行性能
在软件质量保证与测试中,性能测试通常通过一些软件(如集成开发环境或操作系统自带的性能监测可视化工具)检查或模拟一个软件正常运行时或发生异常的情况下,软件在操作系统中体现的各项性能上的数据指标。性能测试的结果通常是软件占用的内存、CPU百分比、网络上传或下载占用的带宽等等。软件开发过后进行专业的性能测试,可以帮助开发者更好地了解软件运行的表现,避免交付后可能出现的崩溃等问题,防止返工以增加开发时间和经济上的成本。
Google Chrome浏览器的开发者工具为开发者提供了测试网页性能的工具,可以看到网页在运行时对硬件和网速等关键指标的占用情况。
如下图所示,在登录、学生信息管理和德育信息挖掘分类时,系统可以在1秒左右处理所有请求,效果较好。

图6-1 网络响应速度
如图所示,系统对计算机CPU和显卡的占用较小,在市面上绝大多数计算机上都可以流畅运行。
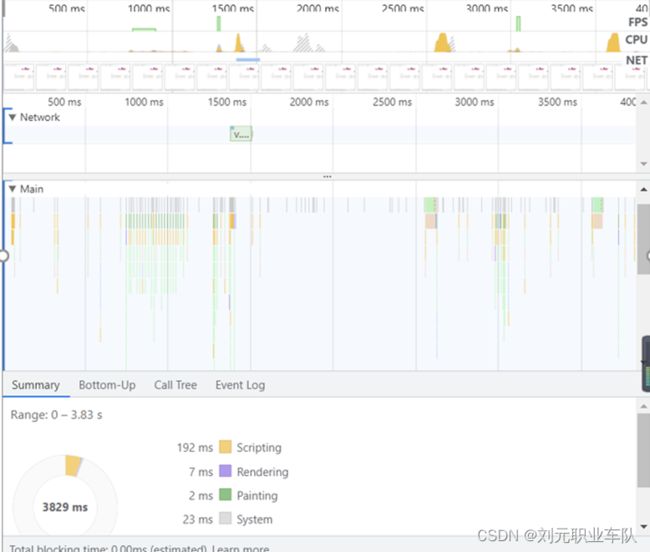
图6-2 系统占用
第七章 总结与展望
7.1 总结
本文以基于Spring Boot的服务器系统、基于Vue.js 的网页和Python机器学习模型作为研究对象,通过对当前德育知识信息挖掘领域所体现的突出问题进行了分析,并完成了Spring Boot框架服务器以及前端网页设计和测试。本项目通过HTTP协议与后台服务器通讯,进行数据相关信息的收发。
7.2 展望
基于Spring Boot、Vue.js和Python的德育知识信息挖掘系统涉及HTML5、CSS、JavaScript、Java和Python开发的多方面理论、技巧和技术。本系统还有很多没有涉及到的问题需要解决,需要在实际应用中不断发现、查找,获得经验的积累和完善。
系统没有对学生增删改查以外的功能进行实现,如登录用户权限管理等等。由于程序的可扩展性较好,今后可以以较方便的手段扩充该系统的功能。
随着计算机开发环境和编程语言的版本迭代,诞生了不少更新更快捷的开发框架,如Spring Cloud等,今后也可以使用其他框架进行编程尝试,为今后工作和科研活动做好基础。
第八章 参考文献
[1]刘晓魁.网络爬虫技术与策略分析[J].网络安全技术与应用,2022(05):17-19.
[2]崔浩亮. 基于机器学习的移动社交电商分类模型研究[D].北京邮电大学,2021.DOI:10.26969/d.cnki.gbydu.2021.003011.
[3]董伟,董思遥,王聪,陶金虎.基于TF-IDF算法和DTM模型的网络学习社区主题分析[J].现代教育技术,2022,32(02):90-98.
[4]陈宏媛.基于UML用例图的三维车体钢结构设计系统需求分析[J].自动化应用,2021(09):154-157.DOI:10.19769/j.zdhy.2021.09.048.
[5]汪萍萍,周亦敏.建筑火灾风险动态评估实体关系图[J].消防科学与技术,2011,30(04):344-347.
[6]李艳梅. 基于时序图的测试用例生成算法研究及自动化测试平台构建[D].北京交通大学,2018.