首个可用于深度学习的ToF相关数据集——基于置信度的立体相机以及ToF相机深度图融合框架
作者 | cocoon
编辑 | 3D视觉开发者社区
✨如果觉得文章内容不错,别忘了三连支持下哦~
文章目录
- 1.导语
- 2. 方法以及网络结构
-
- 2.1使用网络学习置信度
-
- 2.11 训练细节
- 2.2双目以及ToF视差的fusion
- 3.合成数据
- 4.实验结果
-
- 4.1 测试集场景
- 4.2置信度估计结果
- 4.3视差估计定性以及定量结果
- 5.参考文献
- 附录: 数据说明

论文名称: Deep Learning for Confidence Information in Stereo and ToF Data Fusion
论文链接: https://openaccess.thecvf.com/content_ICCV_2017_workshops/papers/w13/Agresti_Deep_Learning_for_ICCV_2017_paper.pdf
数据链接: https://lttm.dei.unipd.it//paper_data/deepfusion/
1.导语
这篇文章提出了一个用于立体相机以及ToF相机深度图融合的框架。其中的关键在于分别得到ToF深度与立体深度的置信度。在两个深度图之间的融合过程中,基于置信度信息施加了局部一致性的约束。
此外,文章的一个比较大的贡献是,提供了一套可用于深度学习网络训练的合成数据集。网络的训练以及测试,均在该数据集上进行。
实验结果表明,该融合框架可以有效地提升深度图的精度。
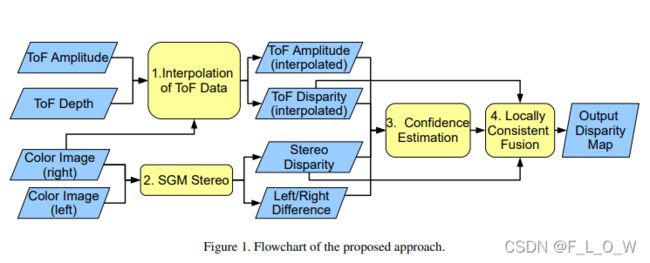
2. 方法以及网络结构
在假定立体采集系统以及ToF系统均已标定的情况下,算法包含以下四个步骤:
- 由ToF sensor得到的深度信息首先被投影到参考的立体相机视角上;
- 由立体匹配算法计算得到一个高分辨率的深度图。具体地,在该论文中使用了SGM算法;
- 使用CNN网络估计得到立体视差以及ToF深度图的置信度;
- 将上采样的ToF输出结果以及立体视差进行融合,融合的方式是LC(Mattoccia 等,2009)技巧的扩展版本。
2.1使用网络学习置信度
对于某一个场景 i i i而言,首先有以下定义:
- D T , i D_{T,i} DT,i:投影至立体系统的ToF视差图;
- A T , i A_{T,i} AT,i:投影至立体系统的幅值图;
- D S , i D_{S,i} DS,i:立体系统得到的视差图;
- I R , i I_{R,i} IR,i:已经转换为灰度的立体系统的右图
- I L ′ , i I_{L',i} IL′,i:warp到右图视角的左图(已经转换为灰度)
- Δ L R . i ′ \Delta '_{LR.i} ΔLR.i′:基于两步骤处理warp的左图和右图之间的差值,首先有:
Δ L R , i = ∣ I L , i μ L , i − I R , i μ R , i ∣ \Delta_{L R, i}=\left|\frac{I_{L, i}}{\mu_{L, i}}-\frac{I_{R, i}}{\mu_{R, i}}\right| ΔLR,i=∣∣∣∣μL,iIL,i−μR,iIR,i∣∣∣∣
其中,缩放因子 μ L , i \mu_{L,i} μL,i以及 μ R , i \mu_{R,i} μR,i分别由左右影像计算而得。该计算结果之后将再除以一个 σ Δ L R \sigma_{\Delta_{LR}} σΔLR,即训练数据集内所有场景下的 Δ L R , j \Delta_{LR,j} ΔLR,j的标准差的平均值:
Δ L R , i ′ = Δ L R , i / σ Δ L R \Delta_{L R, i}^{\prime}=\Delta_{L R, i} / \sigma_{\Delta_{L R}} ΔLR,i′=ΔLR,i/σΔLR
此外,还有:
D T , i ′ = D T , i / σ D T D S , i ′ = D S , i / σ D S A T , i ′ = A T , i / σ A T \begin{aligned} D_{T, i}^{\prime} &=D_{T, i} / \sigma_{D_{T}} \\ D_{S, i}^{\prime} &=D_{S, i} / \sigma_{D_{S}} \\ A_{T, i}^{\prime} &=A_{T, i} / \sigma_{A_{T}} \end{aligned} DT,i′DS,i′AT,i′=DT,i/σDT=DS,i/σDS=AT,i/σAT
其中的 σ D T \sigma_{D_T} σDT, σ D S \sigma_{D_S} σDS, σ A T \sigma_{A_T} σAT均为训练集内多个场景的标准差的平均值。
最终, Δ L R , i ′ \Delta'_{LR,i} ΔLR,i′, D T , i ′ D'_{T,i} DT,i′, D S , i ′ D'_{S,i} DS,i′, A T , i ′ A'_{T,i} AT,i′concat在一起,形成四通道的输入,喂入CNN,输出则为分别对应于ToF数据以及Stereo数据的置信度图 P T P_T PT和 P S P_S PS。
网络推理结构的示意图如下所示:

输入CNN的训练图像块的shape为 142 ∗ 142 142 * 142 142∗142大小的4通道图。
中间堆叠的网络则为6个带有ReLU的卷积层,除了最后一个卷积不带卷积层。前5个卷积层,每层都有128个绿滤波器,第一层的窗口大小为 5 ∗ 5 5 * 5 5∗5,其他则为 3 ∗ 3 3 * 3 3∗3。最后一层卷积只有两个滤波器,进而使得输出只有两个通道,这两个通道分别包含估计的ToF以及立体图的置信度。注意到,为了能够使得输出与输入同分辨率,没有使用任何的池化层。
同时,为了应对由卷积引起的尺寸缩减问题,事先将每张影像都向外pad 7个像素。
2.11 训练细节
通过从完整的影像上随机裁剪得到图像块(pad后为142 * 142),可以获得数量可观的训练数据。
在训练中,可以使用一些标准的数据增强方式,比如说旋转正负5°,水平以及垂直方向的翻转等。
在实验中,从每张图上提取30个patch,再考虑到其增强的版本,总共可以获取到6000个patch。
无论是ToF数据,还是双目数据,其置信度的GT均有估计得到的视差值与GT视差之间的绝对差值而决定。更为具体地,置信度的计算方式是:首先给定一个阈值,将大于该阈值的值clip掉,然后再除以该阈值,使得所有的置信度都落于 [ 0 , 1 ] [0,1] [0,1]之间。
用于训练的损失函数,则计算了网络估计得到的置信度与置信度GT之间的MSE。
优化器采用了SGD,动量大小为0.9。bs=16。权重初始化方式为Xavier初始化。初始的学习率为 1 0 − 7 10^{-7} 10−7,学习率衰减系数为0.9,每隔10轮衰减一次。网络具体的实现采用了MatConvNet的结构。在i7-4790CPU以及NVIDIA Titan X GPU配置的PC上,网络训练需要大约三个小时。
2.2双目以及ToF视差的fusion
LC指代Local Cosistent,是一个用于优化立体匹配数据的方法。在这个方法背后的思想是,每一个有效的深度估计都应当是关于数据颜色体现以及空间一致性的函数。
而这种合理性,更是会进一步地传播到邻近的像素上。在最后,每一个点上都会聚集来自各路的合理性,并经由WTA的方式得到最终的视差值。
在网络中使用的参数为: γ s = 8 \gamma_s =8 γs=8, γ c = γ t = 4 \gamma_c = \gamma_t = 4 γc=γt=4。
LC的扩展方法之一为:根据置信度对多源的深度估计进行加权处理,公式为:
Ω f ′ ( d ) = ∑ g ∈ A ( P T ( g ) P f , g , T ( d ) + P S ( g ) P f , g , S ( d ) ) \Omega_{f}^{\prime}(d)=\sum_{g \in \mathcal{A}}\left(P_{T}(g) \mathcal{P}_{f, g, T}(d)+P_{S}(g) \mathcal{P}_{f, g, S}(d)\right) Ωf′(d)=g∈A∑(PT(g)Pf,g,T(d)+PS(g)Pf,g,S(d))
其中, P T ( g ) P_T(g) PT(g)以及 P S ( g ) P_S(g) PS(g)分别是ToF系统以及Stereo系统在像素 g g g上的置信度。在文章中,该置信度由网络估计而得。
3.合成数据
这篇论文另一个比较大的贡献是,提供了一个名为SYNTH3的合成数据集,这个合成数据集可以直接被用于深度学习网络的训练,其中包含了40个场景(20个场景为各自不同的唯一的场景,另外20个为对前20个场景的不同角度的渲染结果)。
尽管场景数量并不多,但相比起当时所有的数据集来说,已经是最大的stereo-ToF数据集了,而且还能够保持不同场景的不同特性,已非易事。
测试集则包括从15个唯一的场景中采集的数据。
每一个合成数据都通过Blender的3D 渲染功能实现,具体是通过使用虚拟的相机对场景进行渲染。
不同的场景包括了家具以及其他不同形状的物体,也包括了室内的不同环境,比如说起居室、厨房或者办公室。此外,数据中还包括了一些几何结构不规则的室外场景。总的来说,数据看起来相对真实,且比较适合Stereo-ToF采集的模拟。场景中的深度距离在50cm到10m之间,提供了比较广的测量范围。
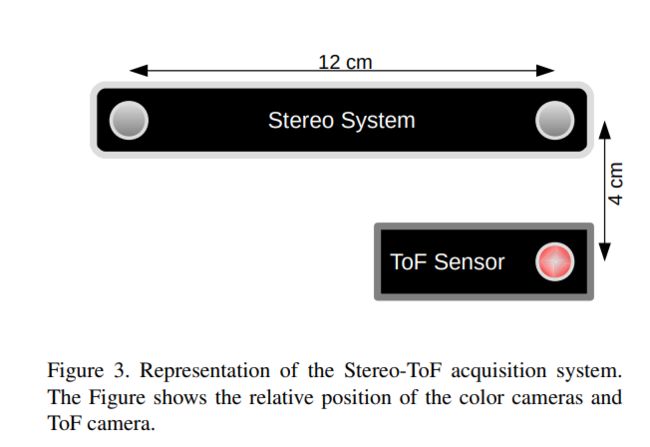
在仿真场景下,虚拟地放置了一个与ZED立体相机参数一致的立体相机,以及一个仿照了Kinect v2相机参数的ToF相机。立体成像系统的基线长度为12cm。二者的相关参数具体为:

Stereo-ToF系统的示意图:
对于每一个场景来说,数据集包括:
(1) 立体系统采集的左右图1920 * 1080 大小的彩色图像;
(2) ToF系统估计得到的深度图;
(3) ToF系统得到的相关幅值图。
彩色图像可以直接由Blender中的3D渲染器 LuxRender得到,
ToF相机则使用Sony EuTEC开发的ToF-Explorer仿真器得到。
ToF模拟器使用由Blender以及LuxBlender生成的场景信息作为输入。
此外,该数据集还包含了场景的深度真值(与立体相机的右图对齐)。SYNTH3应当是第一个可以用于深度学习的ToF合成数据集。
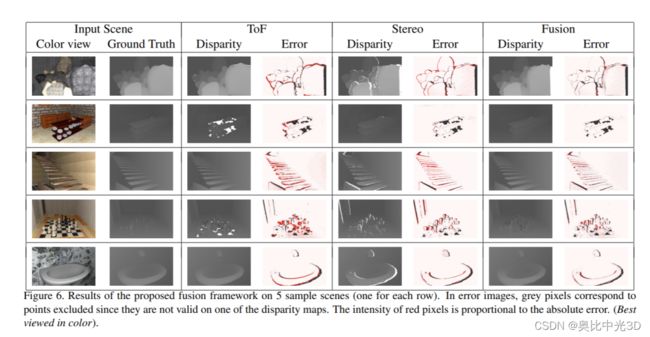
4.实验结果
文章提出的融合算法的训练以及测试都在SYNTH3数据集上。
4.1 测试集场景

4.2置信度估计结果

4.3视差估计定性以及定量结果

5.参考文献
[1] S. Mattoccia. A locally global approach to stereo correspondence. In Proc. of 3D Digital Imaging and Modeling (3DIM), October 2009. 2, 3, 5
附录: 数据说明
文章提供的SYNTH3 数据的下载地址为:https://lttm.dei.unipd.it//paper_data/deepfusion/。
对于数据集中的每一个场景,都有:
- 512 ∗ 424 512 * 424 512∗424 的 ToF深度图;
- 投影到立体系统视角的ToF深度图,分辨率为 960 ∗ 540 960*540 960∗540;
- 分别于16、80、120MHz频率采集的ToF amplitude图,分辨率为 512 ∗ 424 512 * 424 512∗424;
- 在120 MHz频率上获得的、且已经投影至立体相机视角的ToF amplitude图;
- 在16、80、120 MHZ频率上分别获得的 512 ∗ 424 512 * 424 512∗424分辨率的ToF 强度图;
- ToF视角的GT深度图;
- 立体系统获得的左右视角的彩色图像,分辨率分别为 1920 ∗ 1080 1920 * 1080 1920∗1080;
- 由立体相机估计得到的视差图以及深度图,分辨率为 960 ∗ 540 960 * 540 960∗540,右图视角;
- 立体相机右图视角上的GT深度以及GT视差图。
版权声明:本文为奥比中光3D视觉开发者社区特约作者授权原创发布,未经授权不得转载,本文仅做学术分享,版权归原作者所有,若涉及侵权内容请联系删文
3D视觉开发者社区是由奥比中光给所有开发者打造的分享与交流平台,旨在将3D视觉技术开放给开发者。平台为开发者提供3D视觉领域免费课程、奥比中光独家资源与专业技术支持。点击加入3D视觉开发者社区,和开发者们一起讨论分享吧~
也可移步微信关注官方公众号 3D视觉开发者社区 ,获取更多干货知识哦~