支持向量机(SVM)保姆级入门
对于SVM,数学底子比较薄的人初学的时候可能会觉得比较难,今天我来带大家看看这个算法。
线性可分和线性不可分
首先我们了解一下什么是线性可分,和线性不可分。
线性可分是指能使用线性组合组成的超平面将两类集合分开,线性不可分则没有能将两类集合分开的超平面
超平面的方程:w T x + b = 0,其中,w与x都是d维列向量, x = (x 1, x 2, …, x d) 为平面上的点, w (w 1, w, …, w d) 为平面的法向量。
超平面,简单理解,一维空间中是一个点,二维空间中是一条直线,三维中空间是一个面,如下A图,二维空间中,有一条直线(一个超平面)能将两个类别的样本分开,所以A图是线性可分的,而B图不存在一条直线能够将两个类别分开,所以它是线性不可分的。

线性可分再严格一点的定义:
在训练集的样本{(xi,yi)},i=1~m 中,存在(w,b)使:
任意一个i,i=1~m 有:
若yi=1,则w T xi + b >0
若yi=-1,则w T xi + b <0
如下图w T x + b >0的点为一类,w T x + b <0的点为一类。

支持向量机
可以这么说,支持向量机是由线性可分演变而来

这是支持向量机的预测方法
对比于线性可分,>=,<=的右边为+-1
刚开始我想不明白为什么是1,如果你也想不明白,不着急,后面会讲。
接下来我们再来了解一些概念
支持向量:样本中距离超平面最近的一些点,如下图已标红的几个点
间隔 (margin):两个异类支持向量到超平面的距离之和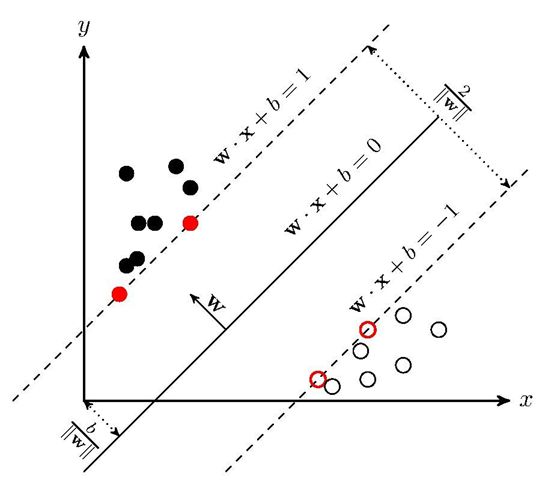
支持向量机的优化目标就是最大化间隔
在二维空间中,(x,y)到直线Ax+By+C=0的距离公式为
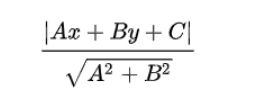

代入计算可知,支持向量到超平面的距离d=1/||w||,那么间隔magin就等于2/||w||。
现在来解答前面提到为什么右边是+-1
有些人可能会有疑惑,存不存在一些支持向量和超平面使|w T x + b |<1
好,那我们就假设它存在,证明如下:

既然我们假设存在,那么||w||d就是已知的常数,除以一个常数就相当于放缩这个超平面,同时我们发现|w T x + b |<1或者>1都是没有影响的,也就是说你存在一个线性可分的超平面,那就存在一个超平面满足wTx+b=+-1
其实使它满足+-常数也是可以的,至于为什么要放缩成+-1,是为了计算方便。

如果是+-1的话,我们能够把这两条式子合并成下面的式子(后面有大用)
得:
yi(WT*Xi+b)>=1,i=1,2,3...m
好,回到我们的正题,最大化我们的magin :2/||w||。
最大化2/||w||就等于最小化||w||/2
所以,我们的主要问题是
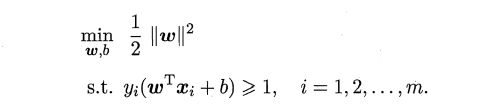
注释:
min下面的w,b,意思是w,b是变量,通过调整w,b来使得1/2||w||的最小值
s.t. 是subject to的缩写,意思是前面的函数受到s.t. 后面约束条件的约束
约束函数就是我们合并出来的式子
拉格朗日乘数法
因为受到条件的约束,所以我们不能直接求导来求极值,这个时候我们引进一个东西:
拉格朗日乘数法(又叫拉格朗日乘子法),为什么要引进它呢?因为拉格朗日函数的极值点包含原函数的极值点,同时没有约束条件
我们先利用高数课本来复习一下它

其中l 为拉格朗日乘子,并且大于等于0.
为拉格朗日乘子,并且大于等于0.
再来道例题感受一下它

 直接将对应的拉格朗日函数求偏导,得到对应方程组,一解就是我们的极值点
直接将对应的拉格朗日函数求偏导,得到对应方程组,一解就是我们的极值点
不过高数课本的题目偏简单,只有一个等式约束,而回到我们优化目标的约束条件,它是一个不等式的约束条件,所以我们的求解肯定没有那么简单啦

原问题的不等式转化为函数g(x)
有了这个不等式约束,我们在求解的过程中可以使用KKT条件来帮忙,下面是B站讲得挺不错的一个视频
拉格朗日乘子法+KKT条件

我直接把结论拿来
然后我解释一下,当约束起作用时(极大值在约束条件外), 局部极值的地方,g(x,y)的偏导数与f(x,y)的偏导数平行,此时g(x,y)=0(g()<=0,在这个地方取0)
约束条件不起作用时,f(x,y)的偏导数为0,g(x,y)的偏导数在这里不为0,要使结论1成立,拉格朗日乘子必须为0
相当于1-->3
条件5是说L函数的海塞矩阵是半正定矩阵,保证函数不凹(这里的凹在西方是上凸),就是有极小值,刚开始可以不管先
构造我们的拉格朗日函数

alpha是我们的拉格朗日乘子,m是样本数
值得注意的是,普通带有约束条件求极值的函数可以转化为跟拉格朗日函数有关的函数
通用例子如下:

几何解释:(结合上面提到的B站课程)当全局最优值在约束条件外,max后面的约束条件把x的解限制在g(x)=0,或者h(x)=0处,解就在这条曲线/直线上,再去找最小值,因为当全局最优值在约束条件外,局部最优值一定是在直线/曲线上,所以二者等价
代数证明如下:

简单理解:后面部分在满足约束的情况下,最大值为0

回到我们的问题:

对偶问题
这里先求max部分显然比较困难,这里我们要引入对偶问题,通过对偶问题,我们可以先求min部分
我们先来了解一下min-max不等式
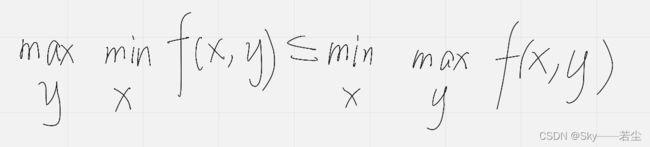
差不多长这样,左边为对偶问题,右边为原问题
上述不等式性质称为弱对偶
当它们取等号时,则为强对偶关系
那么接下来我们显然要让他们取等号,但是取等号有一些条件,我们称为Slater条件
1,原问题为凸函数
2,满足KKT条件
3,约束条件g(x)<=0,g(x)为仿射函数(最高次项为1的线性函数)
凸函数的定义大家可以自行查找,这里不过多叙述了
在SVM中Slater条件是成立的,这里就不证明了
回到我们的问题:

我们把原问题转化为对偶问题,然后看画红线部分
当函数L取得极小值,偏导数为0

再把我们求出来的代回我们对偶问题的式子
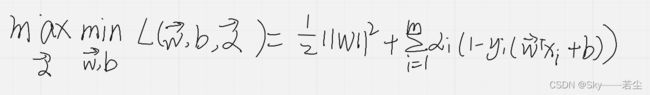

这个时候就求解a了,因为x,y已知,求解的时候为了降低时间复杂度,可以采用SMO算法,这里不讲
好假设我们已经求解完a,我们来看看怎么求解w,b
之前我们提到过

为什么可以推出上述结论,因为w,b和a有关
可能这就是它为什么叫支持向量机的由来
我们不妨从样本集中提出一个子集S代表仅包含支持向量的部分:



核函数
上面的模型是针对线性可分的,那么线性不可分的样本能否用支持向量机呢?
答案是能!不过需要一些转化,通过一个映射函数,把样本从线性不可分的样本空间映射到线性可分的空间中,如下图,二维空间线性不可分映射到三维空间就变成线性可分的
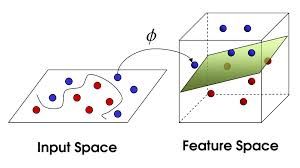
映射函数如何将x映射到高维空间呢?
我举个例子:
有四个点(两个类),在二维空间中找不到一条直线,通过映射函数可以映射到三维空间中去,这个时候我们就能找出一个超平面来分开这两个类



上面为西瓜书对核函数的引入
假设我们在计算两个映射到高维度的向量的内积,例如两个向量x(x1,x2,x3),y(y1,y2,y3),映射函数为f(.),计算f(x)*f(y);
1、(假设映射到10维空间才能线性可分)先算出高维度空间向量f(x),f(y),然后两个向量再点乘,假设算出来f(x)*f(y)=(x1*y1+x2*y2+x3*y3)^5
2、有个函数k(x,y)=(x1*y1+x2*y2+x3*y3)^5=f(x)*f(y)
这个核函数k(..)也算出了它们的内积,显而易见计算的时间复杂度远远小于第一种方法,因为核函数在计算的时候,向量还是在低维度空间,大大减少了计算时间
当然减少计算时间是有代价的,我们把压力给到:找到相应的核函数
显然,若己知合适映射 f(.) 的具体形式,则可写出核函数 κ(. .)。但在现实任务中我们通常不知道 f(.) 是什么形式,那么,合适的核函数是否一定存在呢? 什么样的函数能做核函数呢?我们有下面的定理:

有意思的是,这里又出现了半正定矩阵,前面也有提到过
下面列举一下常见的核函数:

前面提到过的k(x,y)=(x1*y1+x2*y2+x3*y3)^5=f(x)*f(y)就是一个多项式核
通过前面的讨论可知,我们希望样本在特征空间内线性可分,因此特征空间的好坏对支持向量机的性能至关重要.需注意的是,在不知道特征映射的形式时,我们并不知道什么样的核函数是合适的,而核函数也仅是隐式地走义了这个特征空间。于是,"核函数选择"成为支持向量机的最大变数.若核函数选择不合适,则意味着将样本映射到了一个不合适的特征空间,很可能导致性能不佳.
这方面有一些基本的经验,例如对文本数据通常采用线性核,情况不明时可先尝试高斯核
最后总结一下SVM的优缺点
SVM优缺点
优点
因此支持向量机目前只适合小批量样本的任务,无法适应百万甚至上亿样本的任务。
- 有严格的数学理论支持,可解释性强,不依靠统计方法,从而简化了通常的分类和回归问题;
- 能找出对任务至关重要的关键样本(即:支持向量);
- 采用核技巧之后,可以处理非线性分类/回归任务;
- 最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。
缺点
- 训练时间长。当采用 SMO 算法时,由于每次都需要挑选一对参数,因此时间复杂度为
 ,其中 N 为训练样本的数量;
,其中 N 为训练样本的数量; - 当采用核技巧时,如果需要存储核矩阵,则空间复杂度为
 ;
; - 模型预测时,预测时间与支持向量的个数成正比。当支持向量的数量较大时,预测计算复杂度较高。
参考资料:
《机器学习》周志华
大海-老师的个人空间_哔哩哔哩_Bilibili
MLIA/第六章:支持向量机/上 - 知乎