【语音识别】基于matlab DWT算法0~9数字语音识别【含Matlab源码 1726期】
一、简介
[摘 要]以一个能识别数字0~9的语音识别系统的实现过程为例,阐述了基于DTW算法的特定人孤立词语音识别的基本原理和关键技术。其中包括对语音端点检测方法、特征参数计算方法和DTW算法实现的详细讨论,最后给出了在Matlab下的编程方法和实验结果。
1语音识别系统概述
语音识别系统的典型原理框图如图1-1所示。从图中可以看出语音识别系统的本质就是一种模式识别系统,它也包括特征提取、模式匹配、参考模式库等基本单元。由于语音信号是一种典型的非平稳信号,加之呼吸气流、外部噪音、电流干扰等使得语音信号不能直接用于提取特征,而要进行前期的预处理。预处理过程包括预滤波、采样和量化、分帧、加窗、预加重、端点检测等。经过预处理的语音数据就可以进行特征参数提取。在训练阶段,将特征参数进行一定的处理之后,为每个词条得到一个模型,保存为模板库。在识别阶段,语音信号经过相同的通道得到语音参数,生成测试模板,与参考模板进行匹配,将匹配分数最高的参考模板作为识别结果。后续的处理过程还可能包括更高层次的词法、句法和文法处理等,从而最终将输入的语音信号转变成文本或命令。

图1-1 语音识别系统原理框图
本文所描述的语音识别系统(下称本系统)将对数字0~9共10段参考语音进行训练并建立模板库,之后将对多段测试语音进行识别测试。系统实现了上图中的语音输入、预处理、特征提取、训练建立模板库和识别等模块,最终建立了一个比较完整的语音识别系统。
2语音信号预处理
语音信号的预处理模块一般包括预滤波、采样和量化、分帧、加窗、预加重、端点检测等。在不同的系统中对各子模块会有不同的要求,如在嵌入式语音识别系统中一般要求有防混叠滤波电路[5]、A/D转换电路和采样滤波电路等,而在计算机上实验时则可由音频采集卡完成,无需实验者亲自动手。
2.1语音信号采集
在Matlab环境中语音信号的采集可使用wavrecord(n,fs,ch,dtype)函数录制,也可使用Windows的“录音机”程序录制成.wav文件然后使用wavread(file) 函数读入。为了进行批量的的训练和识别处理,本系统的训练语音和识别语音全部使用“录音机”程序预先录制。如图2-1所示为数字0的训练语音00.wav的信号波形图,第(I)幅图为完整的语音波形,第(II)、(III)幅图分别为语音的起始部分和结束部分的放大波形图。

图2-1 语音00.wav的信号波形图
2.2 分帧
语音信号是一种典型的非平稳信号,它的均值函数u(x)和自相关函数R(xl,x2)都随时间而发生较大的变化[5,9]。但研究发现,语音信号在短时间内频谱特性保持平稳,即具有短时平稳特性。因此,在实际处理时可以将语音信号分成很小的时间段(约1030ms[5,7]),称之为“帧”,作为语音信号处理的最小单位,帧与帧的非重叠部分称为帧移,而将语音信号分成若干帧的过程称为分帧。分帧小能清楚地描绘语音信号的时变特征但计算量大;分帧大能减少计算量但相邻帧间变化不大,容易丢失信号特征。一般取帧长20ms,帧移为帧长的1/31/2。
在Matlab环境中的分帧最常用的方法是使用函数enframe(x,len,inc),其中x为语音信号,len为帧长,inc为帧移。在本系统中帧长取240,帧移取80。
2.3 预加重
对于语音信号的频谱,通常是频率越高幅值越小,在语音信号的频率增加两倍时,其功率谱的幅度下降6dB。因此必须对高频进行加重处理,一般是将语音信号通过一个一阶高通滤波器1-0.9375z-1,即为预加重滤波器。其目的是滤除低频干扰,特别是50Hz到60Hz的工频干扰,将对语音识别更为有用的高频部分进行频谱提升。在计算短时能量之前将语音信号通过预加重滤波器还可起到消除直流漂移、抑制随机噪声和提升清音部分能量的效果。预加重滤波器在Matlab中可由语句x=filter([1-0.9375],1,x)实现。
2.4 加窗
为了保持语音信号的短时平稳性,利用窗函数来减少由截断处理导致的Gibbs效应。用的最多的三种为矩形窗、汉明窗(Hamming)和汉宁窗(Hanning)。其窗函数如下,式中的N为窗长,一般等于帧长。
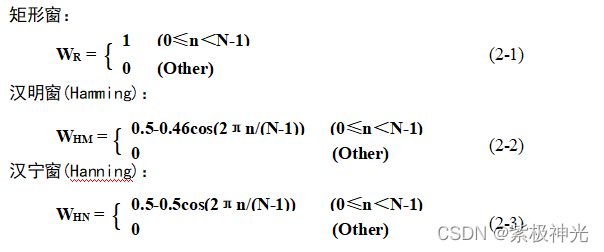
窗口的选择非常重要,不同的窗口将使能量的平均结果不同。矩形窗的谱平滑,但波形细节丢失;而汉明窗则刚好相反,可以有效克服泄漏现象,具有平滑的低通特性。因此,在语音的时域处理方法中,一般选择矩形窗,而在语音的频域处理方法中,一般选择汉明窗或汉宁窗。在Matlab中要实现加窗即将分帧后的语音信号乘上窗函数,如加汉明窗即为x=x.*hamming(N)。本系统中的端点检测采用时域方法故加矩形窗,计算MFCC系数时加汉明窗。
3 端点检测
在基于DTW算法的语音识别系统中,无论是训练和建立模板阶段还是在识别阶段,都先采用端点检测算法确定语音的起点和终点。语音端点检测是指用计算机数字处理技术从包含语音的一段信号中找出字、词的起始点及结束点,从而只存储和处理有效语音信号。对汉语来说,还可进一步找出其中的声母段和韵母段所处的位置。语音端点检测是语音分析、合成和识别中的一个重要环节,其算法的优劣在某种程度上也直接决定了整个语音识别系统的优劣。进行端点检测的基本参数主要有短时能量、幅度、过零率和相关函数等。端点检测最常见的方法是短时能量短时过零率双门限端点检测,近年来在此基础上发展出的动态窗长短时双门限端点检测方法也被广泛使用。
其他加参考论文
二、部分源代码
% dtwtest.m
clear;close all;clc;
disp('正在导入参考模板参数...');
load mfcc.mat;
disp('正在计算测试模板的参数...')
for i=0:9
fname = sprintf('test\\%d1.wav',i);
[k,fs]=audioread(fname);
[StartPoint,EndPoint]=vad(k,fs);
cc=mfcc(k);
cc=cc(StartPoint-2:EndPoint-2,:);
test(i+1).StartPoint=StartPoint;
test(i+1).EndPoint=EndPoint;
test(i+1).mfcc=cc;
end
disp('正在进行模板匹配...')
dist = zeros(10,10);
for i=1:10
for j=1:10
dist(i,j) = dtw(test(i).mfcc, ref(j).mfcc);
end
end
disp('正在计算匹配结果...')
for i=1:10
[d,j] = min(dist(i,:));
fprintf('测试模板 %d1.wav 的识别结果为:%d\n', i-1, j-1);
end
close all;
% enframe.m
function f=enframe(x,win,inc)
%ENFRAME split signal up into (overlapping) frames: one per row. F=(X,WIN,INC)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
nx=length(x);
nwin=length(win);
if (nwin == 1)
len = win;
else
len = nwin;
end
if (nargin < 3)
inc = len;
end
nf = fix((nx-len+inc)/inc);
f=zeros(nf,len);
indf= inc*(0:(nf-1)).';
inds = (1:len);
f(:) = x(indf(:,ones(1,len))+inds(ones(nf,1),:));
if (nwin > 1)
w = win(:)';
f = f .* w(ones(nf,1),:);
end
三、运行结果

四、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社,2019.
[2]柳若边.深度学习:语音识别技术实践[M].清华大学出版社,2019.
[3]郑展恒.数字语音识别系统[J].桂林电子科技大学学报. 2011,31(06)