深入理解ResNet原理解析及代码实现
参考 深入理解ResNet原理解析及代码实现 - 云+社区 - 腾讯云
目录
1、问题
2、如何解决
3、为何有效
4、网络实现
5、网络输入部分
6、网络中间卷积部分
7、残差块实现
8、网络输出部分
9、网络特点
10、总结如下
1、问题
梯度消失和梯度爆炸的问题阻止了刚开始的收敛,这一问题通过初始化归一化和中间层归一化得到了解决。解决了收敛的问题后又出现了退化的现象:随着层数加深,准确率升高然后急剧下降。且这种退化不是由过拟合造成,且向网络中添加适当多层导致了更大的训练误差。随着网络深度的增加,模型精度并不总是提升,并且这个问题并不是由过拟合(overfitting)造成的,因为网络加深后不仅测试误差变高了,它的训练误差竟然也变高了。作者提出,这可能是因为更深的网络会伴随梯度消失/爆炸问题,从而阻碍网络的收敛。这种加深网络深度但网络性能却下降的现象被称为退化问题。也就是说,随着深度的增加出现了明显的退化,网络的训练误差和测试误差均出现了明显的增长,ResNet就是为了解决这种退化问题而诞生的。
2、如何解决
于是作者提出了解决方案:在一个较浅的架构上添加更多层。 对于更深层次的模型:添加的层是恒等映射(identity mapping),其他层则从学习的浅层模型复制。在这种情况下,更深的模型不应该产生比其对应的较浅的网络更高的训练误差。残差学习基本单元:
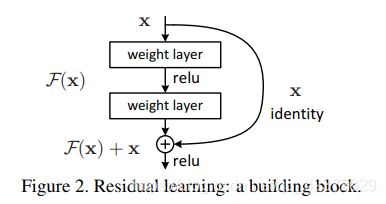
原先的网络输入x,希望输出H(x)。现在我们令H(x)=F(x)+x,那么我们的网络就只需要学习输出一个残差F(x)=H(x)-x。
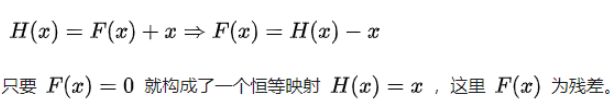
假设输入为 x,有两层全连接层学习到的映射为H(x),也就是说这两层可以渐进(asymptotically)拟合H(x)。假设 H(x)与x维度相同,那么拟合 H(x) 与拟合残差函数 H(x)-x 等价,令残差函数 F(x)=H(x)-x,则原函数变为 F(x)+x ,于是直接在原网络的基础上加上一个跨层连接,这里的跨层连接也很简单,就是 将x的**恒等映射(Identity Mapping)**传递过去。
3、为何有效
- 自适应深度:网络退化问题就体现了多层网络难以拟合恒等映射这种情况,也就是说 H(x)难以拟合 x ,但使用了残差结构之后,拟合恒等映射变得很容易,直接把网络参数全学习到为0,只留下那个恒等映射的跨层连接即可。于是当网络不需要这么深时,中间的恒等映射就可以多一点,反之就可以少一点。
- “差分放大器”:假设最优 H(x)更接近恒等映射,那么网络更容易发现除恒等映射之外微小的波动
- 缓解梯度消失:针对一个残差结构对输入 x 求导就可以知道,由于跨层连接的存在,总梯度在 F(x) 对 x 的导数基础上还会加1
普通网络与深度残差网络的最大区别在于,深度残差网络有很多旁路的支线将输入直接连到后面的层,使得后面的层可以直接学习残差,这些支路就叫做shortcut。传统的卷积层或全连接层在信息传递时,或多或少会存在信息丢失、损耗等问题。ResNet 在某种程度上解决了这个问题,通过直接将输入信息绕道传到输出,保护信息的完整性,整个网络则只需要学习输入、输出差别的那一部分,简化学习目标和难度。
4、网络实现
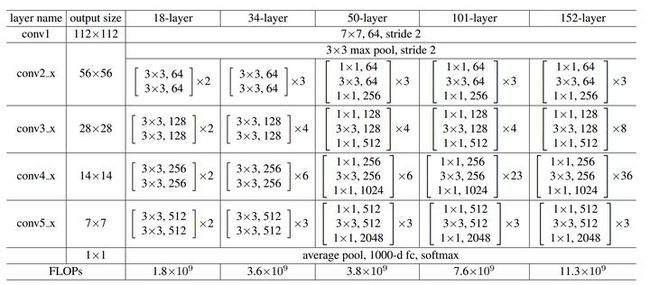
ResNet主要有五种主要形式:Res18,Res34,Res50,Res101,Res152;
如下图所示,每个网络都包括三个主要部分:输入部分、输出部分和中间卷积部分(中间卷积部分包括如图所示的Stage1到Stage4共计四个stage)。尽管ResNet的变种形式丰富,但都遵循上述的结构特点,网络之间的不同主要在于中间卷积部分的block参数和个数存在差异。下面我们以ResNet18为例,看一下整个网络的实现代码是怎样的。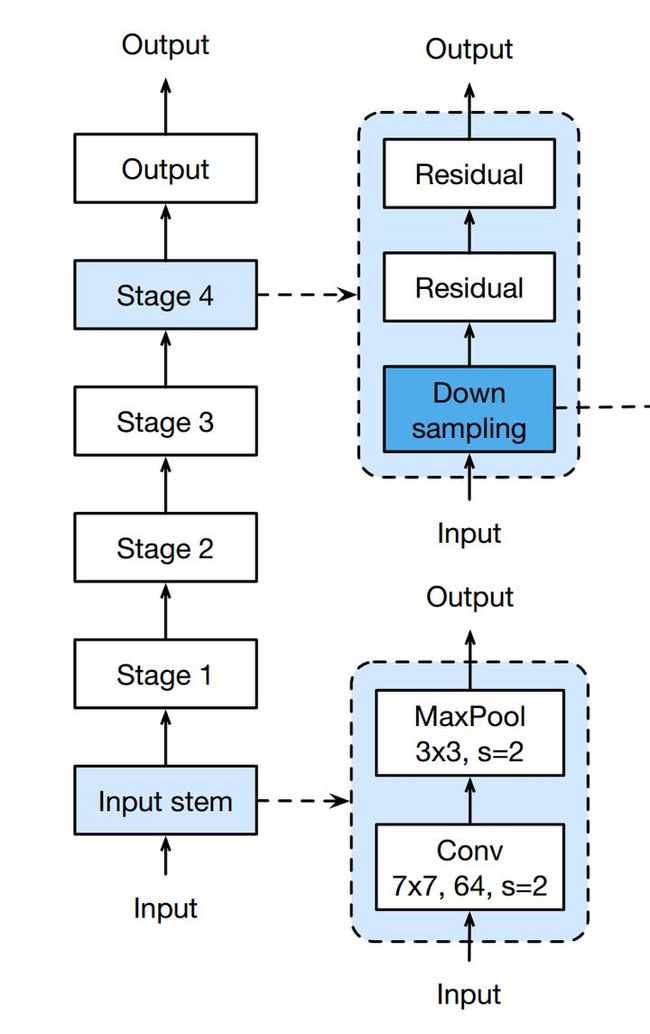
class ResNet(nn.Module):
def forward(self, x):
# 输入
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
# 中间卷积
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# 输出
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
# 生成一个res18网络
def resnet18(pretrained=False, **kwargs):
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet18']))
return model(1)数据进入网络后先经过输入部分(conv1, bn1, relu, maxpool);
(2)然后进入中间卷积部分(layer1, layer2, layer3, layer4,这里的layer对应我们之前所说的stage);
(3)最后数据经过一个平均池化和全连接层(avgpool, fc)输出得到结果;
具体来说,resnet18和其他res系列网络的差异主要在于layer1~layer4,其他的部件都是相似的。
5、网络输入部分
所有的ResNet网络输入部分是一个size=7x7, stride=2的大卷积核,以及一个size=3x3, stride=2的最大池化组成,通过这一步,一个224x224的输入图像就会变56x56大小的特征图,极大减少了存储所需大小。
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)6、网络中间卷积部分
中间卷积部分主要是下图中的蓝框部分,通过3*3卷积的堆叠来实现信息的提取。红框中的[2, 2, 2, 2]和[3, 4, 6, 3]等则代表了bolck的重复堆叠次数。
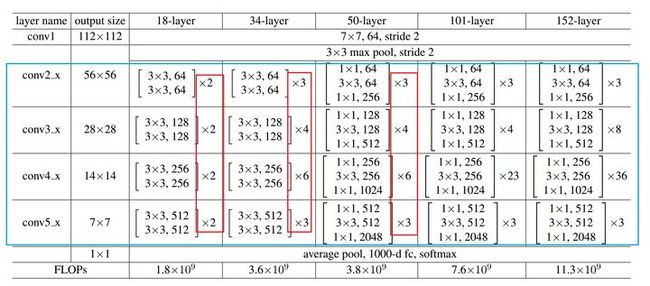
刚刚我们调用的resnet18( )函数中有一句 ResNet(BasicBlock, [2, 2, 2, 2], *kwargs),这里的[2, 2, 2, 2]与图中红框是一致的,如果你将这行代码改为 ResNet(BasicBlock, [3, 4, 6, 3], *kwargs), 那你就会得到一个res34网络。
7、残差块实现
下面我们来具体看一下一个残差块是怎么实现的,如下图所示的basic-block,输入数据分成两条路,一条路经过两个3*3卷积,另一条路直接短接,二者相加经过relu输出,十分简单。
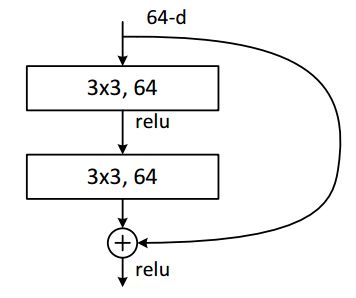
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
8、网络输出部分
网络输出部分很简单,通过全局自适应平滑池化,把所有的特征图拉成1*1,对于res18来说,就是1x512x7x7 的输入数据拉成 1x512x1x1,然后接全连接层输出,输出节点个数与预测类别个数一致。
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)9、网络特点
整个ResNet不使用dropout,全部使用BN。此外:
- 受VGG的启发,卷积层主要是3×3卷积;
- 对于相同的输出特征图大小的层,即同一stage,具有相同数量的3x3滤波器;
- 如果特征地图大小减半,滤波器的数量加倍以保持每层的时间复杂度;
- 每个stage通过步长为2的卷积层执行下采样,而却这个下采样只会在每一个stage的第一个卷积完成,有且仅有一次。
- 网络以平均池化层和softmax的1000路全连接层结束,实际上工程上一般用自适应全局平均池化 (Adaptive Global Average Pooling);
从图中的网络结构来看,在卷积之后全连接层之前有一个全局平均池化 (Global Average Pooling, GAP) 的结构。
10、总结如下
- 相比传统的分类网络,这里接的是池化,而不是全连接层。池化是不需要参数的,相比于全连接层可以砍去大量的参数。对于一个7x7的特征图,直接池化和改用全连接层相比,可以节省将近50倍的参数,作用有二:一是节省计算资源,二是防止模型过拟合,提升泛化能力;
- 这里使用的是全局平均池化,一些论文的**实验结果表明平均池化的效果略好于最大池化,但最大池化的效果也差不到哪里去。**实际使用过程中,可以根据自身需求做一些调整,比如多分类问题更适合使用全局最大池化。