FourIE:一种最新联合事件抽取SOTA论文解读
Cross-Task Instance Representation Interactions and Label Dependencies for Joint Information Extraction with Graph Convolutional Networks

论文:Cross-Task Instance Representation Interactions and Label Dependencies for Joint Information Extraction with Graph Convolutional Networks (aclanthology.org)
代码:未找到开源代码
会议/期刊:NAACL2021
摘要
现有的信息抽取(IE)工作主要是分别解决四个主要任务(实体提及识别、关系抽取、事件触发词检测和论元抽取),无法从任务之间的相互依赖中获益。本文提出了一种新的深度学习模型,在一个模型中同时解决IE的四个任务(称为FourIE)。与之前联合执行四个IE任务的工作相比,FourIE有两个新颖的贡献来捕获任务之间的相互依赖关系。首先,在表示层,我们引入了四个任务实例之间的交互图,用于用其他任务的相关实例来丰富一个实例的预测表示。其次,在标签级别,我们为四个IE任务中的信息类型提出了一个依赖关系图,该图捕捉了输入句子中表达的类型之间的联系。引入了一种新的正则化机制来加强正确类型依赖图和预测类型依赖图之间的一致性,以提高表示学习。我们表明,所提出的模型在三种不同语言的单语和多语学习环境下都达到了联合IE的最先进性能。
1、简介
信息提取(IE)是自然语言处理(NLP)中一项重要且具有挑战性的任务,旨在从非结构化文本中提取结构化信息。遵循流行的ACE 2005程序中的IE术语,我们在这项工作中重点关注四个主要的IE任务:实体提及抽取(EME)、关系抽取(RE)、事件触发词检测(ETD)和事件论元抽取(EAE)。
给定一个输入句子,绝大多数先前的工作已经在实例级和任务级独立地解决了IE中的四个任务(称为独立的预测模型)。首先,在实例级,每个IE任务通常需要在单个输入语句中对多个实例进行预测/分类。例如,在RE关系抽取中,人们经常需要为句子中提到的每一对实体(称为关系实例)预测关系,而句子中的多个词跨度可以被视为多个实例,其中事件类型预测必须在ETD(触发词实例)中进行。因此,大多数IE之前的工作都是通过将每个实例作为数据集中的一个示例来分别对句子中的实例进行预测。其次,在任务层面,IE的先前工作倾向于以流水线方式执行四个任务,其中一个任务的输出被用作其他任务的输入(例如,EAE之后是EME和ETD) 。
尽管独立预测模型很受欢迎,但其主要问题是它们在任务之间存在错误传播,并且无法利用输入语句中的跨任务和跨实例相互依赖来提高IE任务的性能。例如,这样的系统无法从依赖中受益,而死亡(Die)事件的受害者(Victim)有很高的机会受益,也要在同一句话中成为攻击(Attack)事件的受害者(Victim)(即,类型或标签依赖关系)。为了解决这些问题,一些先前的工作已经探索了联合推理模型,其中IE的多个任务同时对一个句子中的所有任务实例执行,使用基于特征的模型和最近的深度学习模型。然而,这些先前的工作大多考虑了四个IE任务子集的联合模型(例如,EME+RE或ETD+EAE),因此仍然存在错误传播问题(缺少任务),未能充分利用四个任务之间潜在的相互依赖关系。为此,本工作旨在设计一个单一模型,同时解决每个输入句子的四个IE任务(联合四任务IE),以解决之前联合IE工作的上述问题。
最近的研究很少考虑联合四任务IE,使用深度学习为任务产生最先进的(SOTA)性能。然而,目前仍有两个问题阻碍着此类模型的进一步完善。首先,在实例级,联合IE深度学习模型的一个重要组成部分涉及用于在输入语句中执行IE相应预测任务的实例的表示向量(称为预测实例表示)。对于联合四任务IE,我们认为四个任务相关实例的预测表示向量之间存在相互依赖关系,应该对其建模以提高IE的性能。例如,实体提及的预测表示向量中编码的实体类型信息可以约束相关EAE实例的表示向量(例如,涉及同一实体提及和同一句子中的某些事件触发词)应该捕获的论元角色,反之亦然。因此,之前关于联合四任务IE的工作仅使用来自某些深度学习层的共享隐藏向量独立计算任务实例的预测表示向量。虽然这种共享机制在一定程度上有助于捕捉预测表示向量之间的相互作用,但它不能显式地表示不同任务的相关实例之间的连接,并将其编码到表示学习过程中。因此,为了克服这个问题,我们提出了一种新型的联合四任务IE深度学习模型(称为F ourIE),它创建了一个图结构来显式地捕获句子中四个IE任务的相关实例之间的交互。然后,该图将被图卷积网络(GCN)使用,用IE的相关(相邻)实例来强化实例的表示向量。
其次,在任务层面,现有的IE联合四任务模型仅利用解码步骤中的跨任务类型依赖关系来约束对输入句子的预测(通过手动将输入句子的类型依赖关系图转换为全局特征向量,以便在基于beam search的解码中对预测进行评分)(Lin et al, 2020)。因此,来自跨任务类型依赖关系的知识不能用于IE模型的训练过程。这是不幸的,因为我们期望将这些知识更深入地集成到训练过程中,可以提供有用的信息,以增强IE任务的表示学习。为此,我们建议使用来自跨任务类型依赖关系的知识,为每句话获取额外的训练信号,以直接监督我们的联合四任务IE模型。特别是,我们的动机是,在一个句子中为四个IE任务表达的类型可以被组织成类型之间的依赖关系图(句子的全局类型依赖关系)。因此,为了使联合模型表现良好,它对句子的预测所生成的类型依赖图应该与从正确类型中获得的依赖图相似(即,在训练步骤中对预测的全局类型约束)。因此,**我们在联合模型的训练损失中引入了一个新的正则化项来编码这个约束,使用另一个GCN来学习预测图和正确依赖图的表示向量,以促进图的相似度提升。**据我们所知,这是第一个使用全局类型依赖来正则化IE的联合模型的工作。
最后,我们的大量实验证明了所提出的模型在三种不同语言(如英语、中文和西班牙语)的基准数据集上的有效性,从而在不同的设置下获得了最先进的性能。
2、问题描述和背景
问题描述:本文的联合IE的四任务问题以一句话作为输入,目的是用统一的模型联合求解四个任务EAE、ETD、RE和EAE。因此,EME的目标是根据一组预定义的(语义)实体类型(例如,Person)检测和分类实体提及(名称(names)、名词(nominals)、代词(pronouns))。类似地,ETD试图识别和分类事件触发词(动词(verbs)或规范化(normalization)),这些事件触发词清楚地在一些预定义的事件类型集(例如,攻击(Attack))中唤起事件。注意,事件触发词可能涉及多个单词。对于RE,它关注的是预测句子中提及的两个实体之间的语义关系。在这里,感兴趣的关系集也是预定义的,它包括一个特殊类型None,表示无关系。最后,在EAE中,给定一个事件触发词,系统需要预测每个实体在相应事件中所扮演的角色(也是在一个具有特殊类型None的预定义集合中)。因此,实体提及在本文中也称为事件论元候选。图1给出了一个句子示例,其中说明了每个IE任务的预期输出。

图卷积网络(GCN):由于GCNs在我们的模型中被广泛使用,为了便于讨论,我们在本节中介绍了GCNs的计算过程。给定一个图 G = ( V , E ) G = (V, E) G=(V,E),其中 V = { v 1 , . . . , v u } V = \{v_1,..., v_u \} V={v1,...,vu}是节点集(有 u u u个节点), E E E是边集。在GCN中, G G G中的边通常通过邻接矩阵 A ∈ R u × u A \in \R^{u×u} A∈Ru×u来捕获。同样,每个节点 v i ∈ V v_i \in V vi∈V都与一个初始隐藏向量 v i 0 v_i^0 vi0相关联。因此,GCN模型涉及多层抽象,其中第 l l l层节点 v i ∈ V v_i \in V vi∈V的隐藏向量 v i l v_i^l vil计算为( l ≥ 1 l≥1 l≥1):
v i l = ReLU ( ∑ j = 1 u A i j W l v j j − 1 + b l ∑ j = 1 u A i j ) v_i^l=\text{ReLU} (\frac{\sum_{j=1}^u A_{ij}W^lv_j^{j-1}+b^l}{\sum_{j=1}^u A_{ij}}) vil=ReLU(∑j=1uAij∑j=1uAijWlvjj−1+bl)
其中 W l , b l W^l , b^l Wl,bl第 l l l层上可训练的参数和偏置。假设有 N N N个GCN层, V V V中最后一层节点的隐藏向量 v 1 N , . . . , v u N v_1^N,...,v_u^N v1N,...,vuN将为节点捕获更丰富、更抽象的信息,作为GCN模型的输出。这个过程表示为: v 1 N , . . . , v u N = G C N ( A ; V 1 0 , . . . , v u 0 ; N ) v_1^N,..., v_u^N = GCN(A;V_1^0,...,v_u^0;N) v1N,...,vuN=GCN(A;V10,...,vu0;N)。
3、模型
给定一个句子 w = [ w 1 , w 2 , . . . , w n ] w=[w_1,w_2,...,w_n] w=[w1,w2,...,wn]有 n n n个字,我们的联合四任务IE模型在句子 w w w上涉及三个主要部分:(i)跨度检测(Span Detection),(ii)实例交互(Instance Interaction),(iii)基于类型依赖的正则化(Type Dependency-base Regularization)。
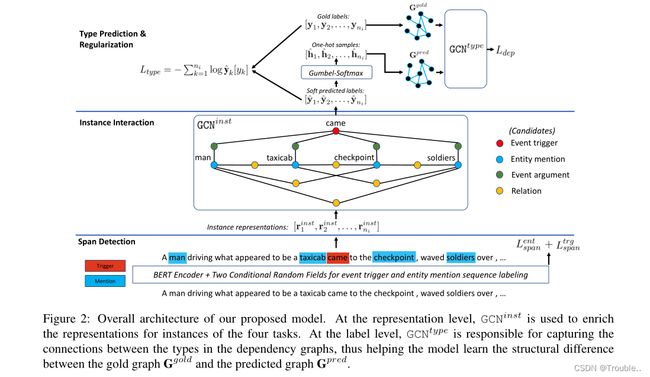
3.1 跨度检测
这一部分的目的是识别 w w w中实体提及和事件触发词片段,这些将用于不同实例之间的交互图中的节点形式的四个任务。这样,我们制定片段检测问题作为序列标注问题,每个单词 w i w_i wi在 w w w用两种BIO标记来捕获的跨度信息实体提及和事件触发词的 w w w。注意,我们没有预测实体类型和事件类型在这个步骤中,导致单词标签只有三个可能的值(即B, I和O)。
实际上,在Lin等人之后,我们首先将 w w w输入预训练的BERT编码器,以获得向量 X = [ x 1 , x 2 , … , x n ] X = [x_1, x_2,…, x_n] X=[x1,x2,…,xn]表示 w w w。这里,每个向量 x i x_i xi作为词 w i ∈ w w_i \in w wi∈w的表示向量,该词 w i ∈ w w_i \in w wi∈w是由BERT返回的 w i w_i wi的片段隐藏向量求平均得到的。之后, X X X被送入两个条件随机场(CRF)层,以确定 w w w的事件提及和事件触发词的最佳BIO标签序列。因此,使用Viterbi算法对输入句子进行解码,负对数似然损失作为模型的跨度检测组件的训练目标。为方便起见,设 L s p a n e n t L_{span}^{ent} Lspanent和 L s p a n t r g L_{span}^{trg} Lspantrg分别为实体提及和事件触发词的正确标签序列的负对数概率。这些项将在以后包含在模型的整体损失函数中。
3.2 实例交互
根据前一个部分中 w w w的标记序列,我们可以获得 w w w中实体提及和事件触发词的两个单独的span集(在训练阶段使用正确跨度以避免噪声)。在接下来的计算中,我们首先为这两个集合中的每个 s p a n ( i , j ) ( 1 ≤ i ≤ j ≤ n ) span(i, j)(1≤i≤j≤n) span(i,j)(1≤i≤j≤n)计算一个表示向量,通过对这个span中单词的基于BERT的表示向量求平均(即, x i , . . . , x j ) x_i,...,x_j) xi,...,xj)。为了方便起见,让 R e n t = { e 1 , e 2 , . . . , e n e n t } ( n e n t = ∣ R e n t ∣ ) R^{ent} = \{ e_1, e_2,..., e_{n_{ent}} \} (n_{ent} = |R^{ent}|) Rent={e1,e2,...,enent}(nent=∣Rent∣)和 R t r g = { t 1 , t 2 , . . . , t n t r g } ( n t r g = ∣ R t r g ∣ ) R^{trg} = \{ t_1, t_2,..., t_{n_{trg}} \} (n_{trg} = |R^{trg}|) Rtrg={t1,t2,...,tntrg}(ntrg=∣Rtrg∣)是 w w w中实体提及和事件触发器的span表示向量集。该组件的目标是利用这些跨度表示向量来形成实例表示,并通过实例交互来丰富它们,从而在IE中执行必要的预测。
实例表示。我们的模型中的预测实例相当于我们为四个IE任务之一预测类型所需的特定对象。因此,EME和ETD的预测实例,称为实体和触发词实例,分别直接对应于 R e n t R^{ent} Rent和 R t r g R^{trg} Rtrg中的实体提及和事件触发词(因为在这一步中,我们需要预测 e i ∈ R e n t e_i \in R^{ent} ei∈Rent的实体类型和 t i ∈ R t r g t_i \in R^{trg} ti∈Rtrg的事件类型)。因此,我们也使用 R e n t R^{ent} Rent和 R t r g R^{trg} Rtrg作为下面EME和ETD的实体/事件实例的初始表示向量集。接下来,对于RE,预测实例(称为关系实例)涉及 R e n t R^{ent} Rent中提到的实体对。为了得到关系实例的初始表示向量,我们将两个对应实体提及的表示向量串联起来,得到关系实例的表示向量集合 r e l i j rel_{ij} relij: R r e l = { r e l i j = [ e i , e j ] ∣ e i , e j ∈ R e n t , i < j } ( ∣ R r e l ∣ = n e n t ( n e n t − 1 ) / 2 ) R^{rel} = \{rel_{ij}= [e_i, e_j] | e_i, e_j \in R^{ent}, i < j\} (|R^{rel}| = n_{ent}(n_{ent}−1)/2) Rrel={relij=[ei,ej]∣ei,ej∈Rent,i<j}(∣Rrel∣=nent(nent−1)/2)。最后,对于EAE,我们通过将 R t r g R^{trg} Rtrg中的每个事件触发词与 R e n t R^{ent} Rent中提到的每个实体配对来形成预测实例(称为论元实例)(对于实体提到的关于事件触发词/提到的论元角色预测)。通过连接配对实体提及和事件触发词的表示向量,我们为相应的论元实例生成初始表示向量 a r g i j arg_{ij} argij R^{arg} = { arg_{ij} = [t_i, e_j] | t_i \in R^{trg}, e_j \in R^{ent} } (|R^{arg}| = n_{trg}n_{ent})$。在这项工作中,我们还可以互换地使用预测实例及其表示向量。
实例交互:到目前为止,实例的初始表示向量没有显式地考虑相关实例之间的有益交互。为了解决这个问题,我们显式地在四个IE任务的预测实例之间创建了一个交互图,以便将相关实例彼此连接起来。这个图将被GCN模型使用,以在之后用交互信息丰富实例表示。其中实例交互图 G i n s t = { N i n s t , E i n s t } G^{inst} = \{ N^{inst}, E^{inst} \} Ginst={Ninst,Einst}中的节点集 N i n s t N^{inst} Ninst包含了这四个IE任务的所有预测实例,即 N i n s t = R e n t ∪ R t r g ∪ R r e l ∪ R a r g N^{inst} = R^{ent}∪R^{trg}∪R^{rel}∪R^{arg} Ninst=Rent∪Rtrg∪Rrel∪Rarg。然后,边集 E i n s t E^{inst} Einst通过连接涉及相同实体提及或事件触发词的实例节点来捕获实例交互(即,如果两个实例涉及相同的实体提及或事件触发词,则它们是相关的)。因此, e i n s t e^{inst} einst中的边如下所示:
(i)一个实体实例节点 e i e_i ei连接到形式为 r e l i j = [ e i , e j ] rel_{ij} = [e_i, e_j] relij=[ei,ej]和 r e l k i = [ e k , e i ] rel_{ki} = [e_k, e_i] relki=[ek,ei]的所有关系实例节点(共享实体提到 e i e_i ei)。
(ii)实体实例节点 e j e_j ej连接到形式为 a r g i j = [ t i , e j ] arg_{ij} = [t_i, e_j] argij=[ti,ej]的所有论元实例节点(共享实体提到 e j e_j ej)。
(iii)触发词节点 t i t_i ti连接到形式为 a r g i j = [ t i , e j ] arg_{ij} = [t_i, e_j] argij=[ti,ej]的所有论元实例节点(即共享事件触发词 t i t_i ti)。
GCN。为了用来自相关(邻近)节点的信息增强 N i n s t N^{inst} Ninst中实例的表示向量,我们将 G i n s t G^{inst} Ginst送入GCN模型(称为 G C N i n s t GCN^{inst} GCNinst)。为了方便起见,我们重命名 N i n s t N^{inst} Ninst中所有实例节点的初始表示向量: N i n s t = { r 1 , … , r n i } ( n i = ∣ N i n s t ∣ ) N^{inst} = \{r_1,…, r_{n_i} \} (n_i = |N^{inst}|) Ninst={r1,…,rni}(ni=∣Ninst∣)。同样,设 A i n s t ∈ { 0 , 1 } n i × n i A^{inst} \in \{0,1\}^{n_i×n_i} Ainst∈{0,1}ni×ni为交互图 G i n s t G^{inst} Ginst的邻接矩阵,其中,如果实例节点 r i r_i ri和 r j r_j rj在 G i n s t G^{inst} Ginst中连通,或者 i = j i = j i=j(对于自连接),则 A i j i n s t = 1 A^{inst}_{ij} = 1 Aijinst=1。然后通过 G C N i n s t GCN^{inst} GCNinst模型计算 N i n s t N^{inst} Ninst中实例的交互增强表示向量: r 1 i n s t , … , r n i i n s t = G C N i n s t ( A i n s t ; r 1 , . . . , r n i ; N i ) r^{inst}_1,…, r^{inst}_{n_i} = GCN^{inst}(A^{inst};r_1,...,r_{n_i};N_i) r1inst,…,rniinst=GCNinst(Ainst;r1,...,rni;Ni),其中 N i N_i Ni是 G C N i n s t GCN^{inst} GCNinst模型的层数。
类型嵌入和预测。最后,对增强的实例表示向量 r 1 i n s t , . . . , r n i i n s t r^{inst}_1,..., r^{inst}_{n_i} r1inst,...,rniinst将用于执行四个IE任务的预测。特别地,设 t k ∈ { e n t , t r g , r e l , a r g } t_k \in \{ent, trg, rel, arg\} tk∈{ent,trg,rel,arg}为 N i n s t N^{inst} Ninst中预测实例 r k r_k rk对应的任务索引, y k y_k yk为任务 t k t_k tk的ground-truth类型。同时,设 T = T e n t ∪ T t r g ∪ T r e l ∪ T a r g T = T^{ent}∪T^{trg}∪T^{rel}∪T^{arg} T=Tent∪Ttrg∪Trel∪Targ为问题( y k ∈ T t k y_k \in T^{t_k} yk∈Ttk)中可能的实体类型(在EME的 T e n t T^{ent} Tent中)、事件类型(在ETD的 T t r g T^{trg} Ttrg中)、关系(在RE的 T r e l T^{rel} Trel中)和论元角色(在EAE的 T a r g T^{arg} Targ中)的并集。注意 T r e l T^{rel} Trel和 T a r g T^{arg} Targ包含特殊类型None。为了准备接下来步骤中的类型预测和类型依赖建模,我们将 T T T中的每个类型与一个嵌入向量(与 e i e_i ei和 t i t_i ti大小相同)相关联,该嵌入向量在我们的训练过程中随机初始化并更新。为了方便起见,让 T = [ t ‾ 1 , . . . , t ‾ n t ] T =[\overline t_1,...,\overline t_{n_t}] T=[t1,...,tnt],其中 t ‾ i \overline t_i ti可互换用于类型及其在 T T T中的嵌入向量( n t n_t nt是类型的总数)。因此,为了在 N i n s t N^{inst} Ninst中对实例 r k r_k rk进行预测,我们计算 r k i n s t r^{inst}_k rkinst与 T t k ∩ T T^{t_k}∩T Ttk∩T中的每个类型嵌入向量之间的点积,以估计 r k r_k rk在 T t k T^{t_k} Ttk中具有类型的可能性。之后,这些分数通过softmax函数进行归一化,得到 T t k T^{t_k} Ttk中 r k r_k rk的可能类型上的概率分布 y ^ k = s o f t m a x x ( r k i n s t t ‾ T ∣ t ‾ ∈ T t k ∩ T ) \hat y_k=softmaxx(r_k^{inst} \overline t^T| \overline t \in T^{t_k} ∩ T) y^k=softmaxx(rkinsttT∣t∈Ttk∩T)。在解码阶段,通过argmax函数(贪心解码)获得 r k r_k rk的预测类型 y k y_k yk: y k = a r g m a x y ^ k y_k = argmax \ \hat y_k yk=argmax y^k。使用所有预测实例的负对数似然来训练模型: L t y p e = − ∑ k = 1 n i l o g y ^ k [ y k ] L_{type} =−\sum_{k=1}^{n_i}\ log\ \hat y_k [y_k] Ltype=−∑k=1ni log y^k[yk]。
3.3 基于类型依赖的正则化
在本节中,我们的目标是获得任务之间的类型依赖关系,并在训练过程中使用它们来监督模型(以改进IE的表示向量)。正如介绍中所述,我们的动机是为每个输入句子生成不同IE任务类型之间的全局依赖关系图,这些输入句子的表示在训练期间用于正则化模型。特别是,从正确类型 y = y 1 , y 2 , . . . , y n i y = y_1, y_2,..., y_{n_i} y=y1,y2,...,yni和预测类型 y ^ = y ^ 1 , y ^ 2 , . . . , y ^ n i \hat y = \hat y_1,\hat y_2,...,\hat y_{n_i} y^=y^1,y^2,...,y^ni对于 N i n s t N^{inst} Ninst中的实例节点,我们构建了两个依赖关系图 G g o l d G^{gold} Ggold和 G p r e d G^{pred} Gpred来捕获任务的全局类型依赖关系(分别称为正确依赖关系图和预测依赖关系图)。之后,为了监督训练过程,我们试图约束模型,使预测的依赖关系图 G p r e d G^{pred} Gpred类似于正确图 G g o l d G^{gold} Ggold(即使用依赖关系图作为桥梁,将 G g o l d G^{gold} Ggold中的全局类型依赖关系知识注入模型)。
依赖图的构建。 G g o l d G^{gold} Ggold和 G p r e d G^{pred} Gpred都以 T T T中所有四个IE任务的类型为节点。为了对类型依赖进行编码, G g o l d G^{gold} Ggold中的连接/边是基于正确类型 y = y 1 , y 2 , . . . , y n i y = y_1, y_2,...,y_{n_i} y=y1,y2,...,yni计算的。
(i)对于每个具有正确类型 y k ≠ N o n e y_k \ne None yk=None的关系实例节点 r k = [ e i , e j ] ∈ N i n s t r_k = [e_i, e_j] \in N^{inst} rk=[ei,ej]∈Ninst,关系类型节点 y k y_k yk连接到对应实体提到 e i e_i ei和 e j e_j ej的正确实体类型节点(称为entity_relation type edges)。
(ii)对于每个具有角色类型 y k ≠ N o n e y_k \ne None yk=None的论元实例节点 r k = [ t i , e j ] r_k = [t_i, e_j] rk=[ti,ej],角色类型节点 y k y_k yk连接到 t i t_i ti的正确事件类型节点(称为event_argument类型边)和 e j e_j ej的正确实体类型节点(称为entity_argument类型边)。
同样的过程可以应用于构建基于预测类型 y ^ = y ^ 1 , y ^ 2 , . . . , y ^ n i \hat y = \hat y_1,\hat y_2,...,\hat y_{n_i} y^=y^1,y^2,...,y^ni的预测依赖关系图 G p r e d G^{pred} Gpred。另外,为方便起见,设 A g o l d A^{gold} Agold和 A p r e d A^{pred} Apred(大小 n t × n t n_t × n_t nt×nt)分别为 G g o l d G^{gold} Ggold和 G p r e d G^{pred} Gpred(包括自循环)的二进制邻接矩阵。
正则化:在下一步中,我们通过将依赖关系图 G g o l d G^{gold} Ggold和 G p r e d G^{pred} Gpred的表示向量输入GCN模型(称为 G C N t y p e GCN^{type} GCNtype)来获得它们。这个GCN模型有 N t N_t Nt层,并使用初始类型嵌入 T = [ t ^ 1 , . . . , t ^ n t ] T =[\hat t_1,...,\hat t_{n_t}] T=[t^1,...,t^nt]作为输入。特别地,这两个图的 G C N t y p e GCN^{type} GCNtype输出包含 t ^ 1 g o l d , . . . , t ^ n t g o l d = G C N t y p e ( A g o l d ; t ^ 1 , . . . , t ^ n t ; N t ) \hat t^{gold}_1,...,\hat t^{gold}_{n_t} = GCN^{type}(A^{gold};\hat t_1,...,\hat t_{n_t};N_t) t^1gold,...,t^ntgold=GCNtype(Agold;t^1,...,t^nt;Nt)和 t ^ 1 p r e d , . . . , t ^ n t p r e d = G C N t y p e ( A p r e d ; t ^ 1 , . . . , t ^ n t ; N t ) \hat t^{pred}_1,...,\hat t^{pred}_{n_t} = GCN^{type}(A^{pred};\hat t_1,...,\hat t_{n_t};N_t) t^1pred,...,t^ntpred=GCNtype(Apred;t^1,...,t^nt;Nt),为在 G g o l d G^{gold} Ggold和 G p r e d G^{pred} Gpred中呈现的类型依赖项编码底层信息。最后,为了提高 G g o l d G^{gold} Ggold和 G p r e d G^{pred} Gpred中类型依赖的相似性,我们将它们的 G C N t y p e GCN^{type} GCNtype诱导表示向量之间的均方差引入到总体损失函数中以实现最小化: L d e p = ∑ i = 1 n t ∥ t ^ i g o l d − t ^ i p r e d ∥ 2 2 L_{dep}=\sum_{i=1}^{n_t} \parallel \hat t_i^{gold}-\hat t_i^{pred} \parallel_2^2 Ldep=∑i=1nt∥t^igold−t^ipred∥22。
我们最终的训练损失是:$L = L^{ent}{span} + L^{trg}{span} + L_{type} + λL_{dep} $(λ是一个权衡参数)。
近似 A p r e d A^{pred} Apred。到目前为止,我们在模型中区分了两种类型的参数,即用于计算实例表示的参数,例如BERT和 G i n s t G^{inst} Ginst中的参数(称为 θ i n s t θ^{inst} θinst),以及用于类型依赖正则化的参数,即用于类型嵌入 t ^ 1 \hat t_1 t^1的参数 t ^ 1 , . . . , t ^ n t \hat t_1,...,\hat t_{n_t} t^1,...,t^nt和 G t y p e G^{type} Gtype(称为 θ d e p θ^{dep} θdep)。因此,目前的实现只允许来自 L d e p L_{dep} Ldep的训练信号反向传播到参数 θ d e p θ^{dep} θdep,不允许 L d e p L^{dep} Ldep影响实例表示相关参数 θ i n s t θ^{inst} θinst。为了用类型依赖信息丰富实例表示向量,我们期望 L d e p L_{dep} Ldep通过对 θ i n s t θ^{inst} θinst的贡献更深入地集成到模型中。为了实现这一目标,我们注意到 L d e p L_{dep} Ldep和 θ i n s t θ^{inst} θinst之间反向传播的阻塞是由于它们在模型中通过邻接矩阵 A p r e d A^{pred} Apred的唯一连接, A p r e d A^{pred} Apred的值要么是1,要么是0。因此, A p r e d A^{pred} Apred中的值不直接依赖于 θ i n s t θ^{inst} θinst中的任何参数,使得反向传播不可能流动。为此,我们建议用一个新的矩阵 A ^ p r e d \hat A^{pred} A^pred来近似 A p r e d A^{pred} Apred,它直接将 θ i n s t θ^{inst} θinst包含在它的值中。特别地,设 I i n s t I^{inst} Iinst为 A p r e d A^{pred} Apred中非零单元格的索引集: I i n s t = { ( i , j ) ∣ A i j p r e d = 1 } I^{inst} = \{(i, j)|A^{pred}_{ij} = 1\} Iinst={(i,j)∣Aijpred=1}。由于 I i n s t I^{inst} Iinst中的元素是由索引 i 1 , . . . , i n i i_1,...,i_{n_i} i1,...,ini决定的,因此预测类型为 y ^ 1 , y ^ 2 , . . . , y ^ n i \hat y_1, \hat y_2,...,\hat y_{n_i} y^1,y^2,...,y^ni(分别),我们也试图计算基于这些索引的近似矩阵 A p r e d A^{pred} Apred的值。据此,我们首先定义矩阵 B = { b i j } i , j = 1... n t B = \{b_{ij}\}i,j=1...n_t B={bij}i,j=1...nt将第 i i i行和第 j j j列的元素 b i j b_{ij} bij设为 b i j = i ∗ n t + j b_{ij} = i * n_t + j bij=i∗nt+j。然后得到近似矩阵 A ^ p r e d \hat A^{pred} A^pred:
A ^ p r e d = ∑ ( i , j ) ∈ I i n s t e x p ( − β ( B − i n t − j ) 2 ) \hat A^{pred}=\sum_{(i,j) \in I^{inst}} exp(-\beta(B-in_t-j)^2) A^pred=(i,j)∈Iinst∑exp(−β(B−int−j)2)
这里, β > 0 β > 0 β>0是一个大常数。对于每个元素 ( i , j ) ∈ I i n s t (i, j) \in I^{inst} (i,j)∈Iinst,矩阵 ( B − i n t − j ) 2 (B-in_t-j)^2 (B−int−j)2中的所有元素都是严格正的,除了 ( i , j ) (i, j) (i,j)处的元素为零。因此,当 β β β值较大时,矩阵 e x p ( − β ( B − i n t − j ) 2 ) exp(-\beta(B-in_t-j)^2) exp(−β(B−int−j)2)在单元格 ( i , j ) (i, j) (i,j)的值为1,而在其他单元格的值几乎为零。因此,在 I i n s t I^{inst} Iinst的位置上 A ^ p r e d \hat A^{pred} A^pred的值趋近于1,而在其他位置上 A ^ p r e d \hat A^{pred} A^pred的值趋近于0,从而近似于我们的期望矩阵 A p r e d A^{pred} Apred,并且仍然直接依赖于指标 i 1 , . . . , i n t i_1,...,i_{n_t} i1,...,int。
处理索引的离散性。即使有了近似的 A p r e d A^{pred} Apred,反向传播仍然不能从 L d e p L_{dep} Ldep流向 θ i n s t θ^{inst} θinst,因为离散和不可微的指标变量 i 1 , . . . , i n i i_1,...,i_{n_i} i1,...,ini的阻碍。为了解决这个问题,我们建议应用Gumbel-Softmax分布,通过提供一种方法来近似从连续的分类分布中采样的one-hot向量,从而实现离散随机变量模型的优化。
特别地,我们首先将每个索引 i k i_k ik重写为: i k = h k c k T i_k = h_kc^T_k ik=hkckT,其中 c k c_k ck是一个向量,其每个维数都包含联合类型集 T T T中 T t k T^{t_k} Ttk中某个类型的索引, h k h_k hk是一个二进制onehot向量,其维数对应于 T t k T^{t_k} Ttk中的类型。 h k h_k hk只在预测类型 y k ∈ T t k y_k \in T^{t_k} yk∈Ttk(以 i k i_k ik 在 T T T为索引)对应的位置打开。在当前实现中, y ^ k \hat y_k y^k(因此反向索引,一个one-hot的向量 h k h_k hk)获得通过argmax功能: y ^ k = a r g m a x y ^ k \hat y_k = argmax \ \hat y_k y^k=argmax y^k,导致不连续性。因此,Gumbel-Softmax分布方法有助于放松argmax,方法是用样例 h ^ k = h ^ k , 1 , . . . , h ^ k , ∣ T t k ∣ \hat h_k=\hat h_{k,1},...,\hat h_{k,|T^{t_k}|} h^k=h^k,1,...,h^k,∣Ttk∣从Gumbel-Softmax分布:
h ^ k , j = e x ( ( l o g ( π k , j ) + g j ) / t ) ∑ j ′ = 1 T t k e x ( ( l o g ( π k , j ′ ) + g j ′ ) / t ) \hat h_{k,j}=\frac{ex((log(\pi_{k,j})+g_j)/t)}{\sum_{j'=1}^{T^{t_k}}ex((log(\pi_{k,j'})+g_{j'})/t)} h^k,j=∑j′=1Ttkex((log(πk,j′)+gj′)/t)ex((log(πk,j)+gj)/t)
其中 π k , j = y ^ k , j = s o f t m a x j ( r k i n s t t ‾ T ∣ t ‾ ∈ T t k ∩ T ) , g 1 , . . . , g ∣ T t k ∣ \pi_{k,j}=\hat y_{k,j}=softmax_j(r_k^{inst} \overline t^T | \overline t \in T^{t_k} \cap T),g_1,...,g_{|T^{t_k}|} πk,j=y^k,j=softmaxj(rkinsttT∣t∈Ttk∩T),g1,...,g∣Ttk∣为从Gumbel(0,1)分布中提取的样本: g j = − l o g ( − l o g ( u j ) ) ( u j ∼ U n i f o r m ( 0 , 1 ) ) g_j =−log(−log(u_j)) (uj∼Uniform(0,1)) gj=−log(−log(uj))(uj∼Uniform(0,1)), t t t为温度参数。当 t → 0 t→0 t→0时,样本 h k h_k hk将变得接近我们期望的one-hot向量 h k h_k hk。最后,在 i k i_k ik的计算中,我们将 h k h_k hk替换为近似值 h ^ k \hat h_k h^k: i k = h ^ k c k T i_k = \hat h_kc^T_k ik=h^kckT,它直接依赖于 r k i n s t r^{inst}_k rkinst,并应用于 A ^ p r e d \hat A^{pred} A^pred。这使得梯度从 L d e p L_{dep} Ldep流向参数 θ i n s t θ^{inst} θinst,并完成了我们模型的描述。
4、实验
数据集:ACE2005、ERE-EN、ERE-ES
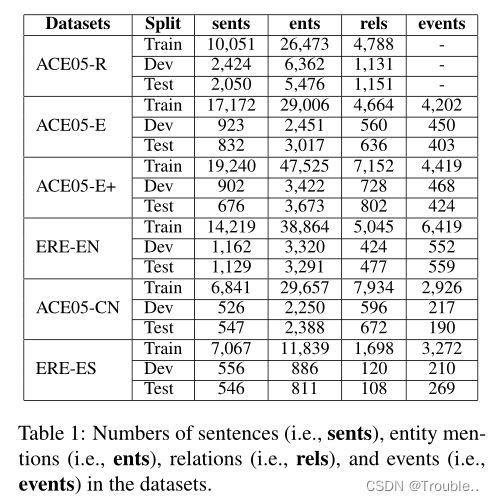
超参数和评估标准。我们使用开发数据对模型的超参数进行微调。建议的数值见附录。为了实现与Lin等人的公平比较,我们对英语数据集采用bert-large-cased模型,对中文和西班牙语数据集采用bert-multilanguage-cased模型。最后,我们遵循与之前工作中相同的实体提及、事件触发词、关系和论元的评估脚本和正确性标准。报告的结果是使用不同随机种子的5个模型运行的平均性能。
效果比较。对比模型:DyGIE++、OneIE。表2展示了各个模型在英文数据集上的效果。注意,在表中,前缀“Ent”、“Trg”、“Rel”和“Arg”分别代表实体提及、事件触发词、关系和论元的提取任务,后缀“-I”和“-C”分别对应识别性能(仅涉及偏移量正确性)和识别+分类性能(同时评估偏移量和类型)。
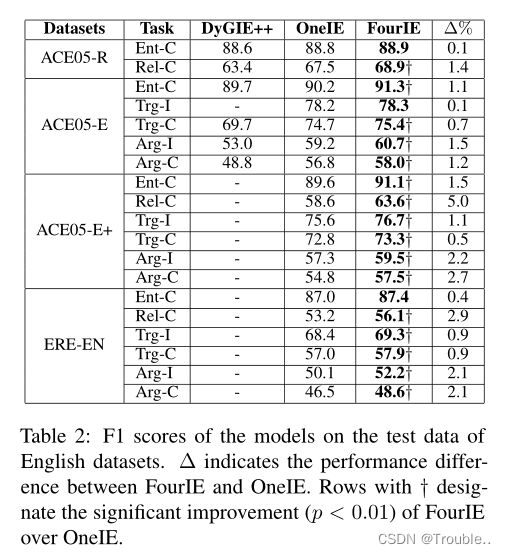
从表中可以看出,在不同的数据集和任务中,FourIE始终优于两个基线模型(DyGIE++和OneIE)。在几乎所有的情况下,性能的改善都是显著的,并清楚地证明了所提出的模型的有效性。
最后,表3展示了FourIE和OneIE在中文和法语数据集(ACE05-CN,ERE-ES)上的效果。除了单语言设置(即在同一语言上训练和评估)之外,我们还在多语言训练设置上评估模型,其中ACE05-CN和ERE-ES(分别)与其对应的英语数据集ACE05-E+和EAE-EN(分别)结合起来训练模型(用于四个IE任务),然后在相应语言的测试集(即ACE05-CN和ERE-ES)上评估性能。从表中可以清楚地看出,在几乎所有针对语言、数据集和任务的不同设置组合中,FourIE的表现也明显优于OneIE。这进一步说明了FourIE对不同语言的可移植性。

G C N i n s t GCN^{inst} GCNinst和 G C N t y p e GCN^{type} GCNtype的影响。本节评估了我们提出的模型FourIE中两个重要组件的贡献,即与 G C N i n s t GCN^{inst} GCNinst的实例交互图和与 G C N t y p e GCN^{type} GCNtype的类型依赖图。特别地,我们研究了FourIE的以下消融/变化模型:(i)“ FourIE-GCN i n s t \text{FourIE-GCN}^{inst} FourIE-GCNinst”:该模型从FourIE中排除了实例交互图和GCN模型 G C N i n s t GCN^{inst} GCNinst,因此初始实例表示 r k r_k rk直接用于预测实例的类型(取代强化的向量 r k i n s t r^{inst}_k rkinst), (ii)“ FourIE- GCN t y p e \text{FourIE- GCN}^{type} FourIE- GCNtype”:该模型从FourIE中删除了类型依赖图和GCN模型 G C N t y p e GCN^{type} GCNtype(因此也删除了损失项 L d e p L_{dep} Ldep)(iii)“ FourIE-GCN i n s t − GCN t y p e \text{FourIE-GCN}^{inst}-\text{GCN}^{type} FourIE-GCNinst−GCNtype”:该模型从FourIE中删除了实例交互和类型依赖图,(iv)“ FourIE-GCN t y p e − TDDecode \text{FourIE-GCN}^{type}-\text{TDDecode} FourIE-GCNtype−TDDecode”:该模型也排除了 G C N t y p e GCN^{type} GCNtype;然而,它在解码步骤中应用全局类型依赖特征来对beam search的联合预测进行评分(该beam search的实现继承自Lin等人,以便进行公平的比较),以及(v)“ FourIE- A ^ p r e d \text{FourIE-}\hat A^{pred} FourIE-A^pred”:该模型在FourIE中不使用近似矩阵 A p r e d A^{pred} Apred,而是直接使用 L d e p L_{dep} Ldep正则化中的邻接矩阵 A p r e d A^{pred} Apred(因此 L d e p L_{dep} Ldep不影响实例表示相关参数 θ i n s t \theta^{inst} θinst)。表4显示了模型在ACE05E+开发数据集上对四个IE任务的性能。
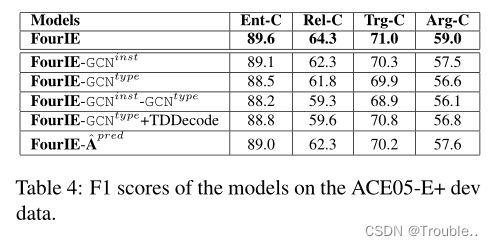
从表中观察到的最重要的一点是, G C N i n s t GCN^{inst} GCNinst和 G C N t y p e GCN^{type} GCNtype都是FourIE实现四个IE任务的最高性能所必需的。重要的是,将FourIE中的 G C N t y p e GCN^{type} GCNtype替换为用于解码的全局类型依赖特征(即“ FourIE -GCN t y p e + TDDecode” \text{FourIE -GCN}^{type}+\text{TDDecode}” FourIE -GCNtype+TDDecode”),如Lin等人或消除 L d e p L_{dep} Ldep的近似 A p r e d A^{pred} Apred会产生较差的性能,特别是在关系和论元抽取方面。这清楚地证明了深度集成来自类型依赖关系的知识对联合四任务IE的 L d e p L_{dep} Ldep影响表示学习参数的好处。
类型依赖边的贡献。我们的类型依赖关系图 G g o l d G^{gold} Ggold和 G p r e d G^{pred} Gpred涉及三种类型的边,即entity_relation、entity_argument和event_argument类型的边。表5给出了在我们的类型依赖图构建中排除这些边缘类别时,FourIE(在ACE05-E+的开发数据上)的性能。

该表清楚地显示了不同类别的类型依赖边对于FourIE的重要性,因为消除任何类别通常都会损害模型的性能。此外,我们看到类型依赖边的贡献级别直观地根据考虑的任务而变化。例如,entity_relation类型边主要用于实体提及、关系和论元抽取。最后,在附录中进行了错误分析,以提供关于类型依赖图 G g o l d G^{gold} Ggold和 G p r e d G^{pred} Gpred对FourIE的好处的见解(即,通过比较FourIE和“ FourIE- GCN t y p e \text{FourIE- GCN}^{type} FourIE- GCNtype”的输出)。
5、相关工作
IE的早期联合方法采用了特征工程来捕获IE任务之间的依赖关系,包括全局约束的整数线性规划(Integer Linear Programming for Global Constraints),马尔可夫逻辑网络(Markov logic Networks),结构化感知器(Structured Perception)和图形模型(Graphical Models)。
近年来,深度学习的应用促进了IE跨任务共享参数机制的联合建模。这些联合模型专注于IE任务的不同子集,包括EME和RE,事件和时间RE,以及ETD和EAE。然而,这些工作都没有像我们一样探索对四个IE任务EME、ETD、RE和EAE的联合推断。与我们最相关的两项工作包括Wadden等人通过动态跨度图利用基于BERT的信息传播,以及Lin等人利用BERT和全局类型依赖特征来约束解码步骤。我们的模型与这些工作的不同之处在于,我们引入了一个新的交互图,用于四个IE任务的实例表示,并引入了一个全局类型依赖图,将知识直接注入到训练过程中。
6、总结
我们提出了一个新的深度学习框架来共同解决四个IE任务(EME, ETD, RE和EAE)。我们的模型试图根据实例交互和类型依赖关系图来捕获四个任务实例及其类型之间的相互依赖关系。利用GCN模型诱导表示向量对任务实例进行类型预测,使训练过程规范化。实验证明了所提模型的有效性,导致在英语、中文和西班牙语的多个数据集上的SOTA性能。在未来,我们计划扩展模型以包括更多的IE任务(例如,共指消解)。