常规卷积与因果卷积的区别详解
文章目录
- 0、前言
- 1、一般卷积
- 2、因果卷积
- 3、因果卷积的PyTorch实现
0、前言
今天学习因果卷积(WaveNet与TCN中的),看源代码的时候遇到了一些问题,比如为什么要Chomp1d?按我的理解吧,如果padding数目为 ( k − 1 ) × d / 2 (k-1)\times d/2 (k−1)×d/2( k k k表示卷积核尺寸kernel_size, d d d表示膨胀因子dilation_factor),那么按照公式

卷积层输入和输出的长度就是不变的啊!为啥还要chomp呢?
对了,顺便把源码也贴一下(链接至GitHub)
class Chomp1d(nn.Module):
def __init__(self, chomp_size):
super(Chomp1d, self).__init__()
self.chomp_size = chomp_size
def forward(self, x):
return x[:, :, :-self.chomp_size].contiguous()
class TemporalBlock(nn.Module):
def __init__(self, n_inputs, n_outputs, kernel_size, stride, dilation, padding, dropout=0.2):
super(TemporalBlock, self).__init__()
self.conv1 = weight_norm(nn.Conv1d(n_inputs, n_outputs, kernel_size,
stride=stride, padding=padding, dilation=dilation))
self.chomp1 = Chomp1d(padding)
self.relu1 = nn.ReLU()
self.dropout1 = nn.Dropout(dropout)
self.conv2 = weight_norm(nn.Conv1d(n_outputs, n_outputs, kernel_size,
stride=stride, padding=padding, dilation=dilation))
self.chomp2 = Chomp1d(padding)
self.relu2 = nn.ReLU()
self.dropout2 = nn.Dropout(dropout)
self.net = nn.Sequential(self.conv1, self.chomp1, self.relu1, self.dropout1,
self.conv2, self.chomp2, self.relu2, self.dropout2)
self.downsample = nn.Conv1d(n_inputs, n_outputs, 1) if n_inputs != n_outputs else None
self.relu = nn.ReLU()
self.init_weights()
def init_weights(self):
self.conv1.weight.data.normal_(0, 0.01)
self.conv2.weight.data.normal_(0, 0.01)
if self.downsample is not None:
self.downsample.weight.data.normal_(0, 0.01)
def forward(self, x):
out = self.net(x)
res = x if self.downsample is None else self.downsample(x)
return self.relu(out + res)
class TemporalConvNet(nn.Module):
def __init__(self, num_inputs, num_channels, kernel_size=2, dropout=0.2):
super(TemporalConvNet, self).__init__()
layers = []
num_levels = len(num_channels)
for i in range(num_levels):
dilation_size = 2 ** i
in_channels = num_inputs if i == 0 else num_channels[i-1]
out_channels = num_channels[i]
layers += [TemporalBlock(in_channels, out_channels, kernel_size, stride=1, dilation=dilation_size,
padding=(kernel_size-1) * dilation_size, dropout=dropout)]
self.network = nn.Sequential(*layers)
def forward(self, x):
return self.network(x)
研究了一天,顺带还学习了一下tensorflow里面的Conv1d(那个里面的padding是可以设置为'causal')的。总算弄明白了,在这里跟大家分享一下,主要是三张图(用OneNote画的草图,有点丑,大家见谅)。
1、一般卷积

这是一般卷积,蓝色是input layer,绿色是hidden layer。为了维持输入输出长度不变,设置padding为1。
2、因果卷积
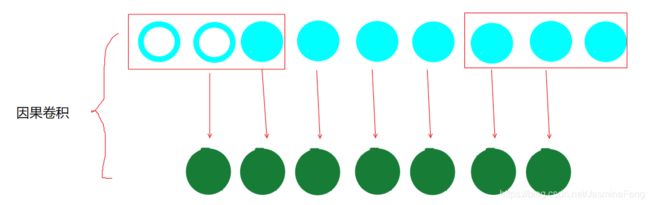
此为因果卷积,与上一张图的相同点是输入输出长度仍然一致,但是因果卷积是看不到未来情况的,所以大家可以看到,最后一个时间步后就没有padding了,但是这样输入输出长度就不一致了啊,所以为了解决这个矛盾,我们看到最右边的padding移到最左边了。因此,因果卷积中,padding的数目不变,只是padding的位置变了。
3、因果卷积的PyTorch实现
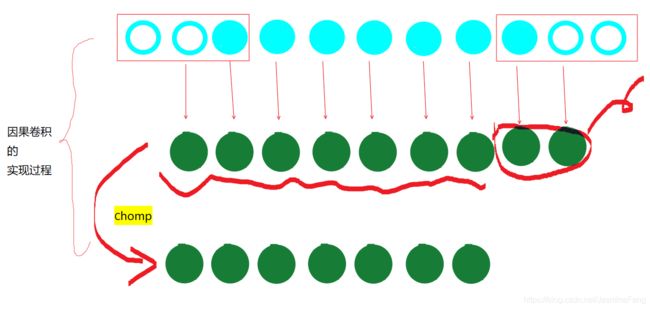
我本人对PyTorch比较熟悉,在torch.nn.Conv1d里,是不好直接设置causal convolution模式的。所以才有了源码中的chomp,那么究竟为什么要用chomp呢?我们一探究竟。
PyTorch的padding是在两端填充值,为了在左端填上两个padding,不得不在右边也填上两个。但如此输出长度也会多出2,所以才要把最后两个舍弃。(可以看到源码TemporalBlock类的self.chomp1 = Chomp1d(padding)这边是把padding的值放进去的,也就证明了多出来的或者说要丢弃的刚好就是最右边两个padding)。