[Transformer]MCTrans:Multi-Compound Transformer for Accurate Biomedical Image Segmentation
MCTrans:用于精确生物医学图像分割的复合Transformer
- Abstract
- Section I Introduction
- Section II Related Work
- Section III Mulit-Compound Transformer Network
-
- Part 1 Transformer-Self-Attention(TSA)
- Part 2 Transformer-Cross-Attention(TCA)
- Section IV Experiments
- Section V Conclusion
Abstract
在视觉任务中,Transformer被用于学习不同token之间的局部交互作用,但是之前的一些研究遗漏了对不同像素之间依赖的学习,而跨尺度的语义依赖性、不同标签之间对应的语义关系、特征表述与对应语义嵌入的一致性对精确的医学图像分割十分重要。因此本文提出一种多类别复合Transformer(MCTrans,Multi-Compound Transformer)来解决上述问题,可以在一个框架中学习丰富的语义特征、挖掘丰富的语义结构。
具体来说,MCTrans将多尺度的卷积特征表示为tokens序列,执行同尺度和跨尺度的注意力计算,而不像之前计算的都是单尺度的注意力。除此之外,还在建模语义关系是引入一个可训练的代理嵌入器(proxy embedding),通过自注意力和夸注意力来丰富特征。
MCTrans可以方便的插入到UNet类似结构的网络中,并且在一些医学图像分割的SOTA框架中带来明显的性能提升。比如在Pannuke, CVC-Clinic, CVC-Colon, Etis, Kavirs, ISIC2018数据集上性能比UNet分别提升了3.64%、3.71%、4.34%、2.8%、1.88%。
Section I Introduction
医学图像分割旨在通过分割出感兴趣区域进行计算机辅助诊断,如病变检测、结构定位等。目前CNN是主流的框架,但是鉴于CNN的局部特性,传统的基于CNN的分割模型,如FCN无法有效的建模长程依赖关系。为了解决这一问题提了各种方法,如空间金字塔通过采用不同发小的卷积核来聚合不同尺度的上下文信息;UNet这种编码-解码网络通过skip-connection有效的融合了粗粒度深层次的特征和细粒度浅层特征。
虽然上述方法在进行密集预测取得了成功但他们依旧无法有效的建模非局部的上下文信息。
近期应用于CV领域的Transformer因为可以有效的学习不同token之间的交互关系,引起了学界的研究热情。比如TransUNet首次将self-attention机制融合进UNet来计算全局的上下文特征,但这并不是医学图像分割的最优框架,它存在以下问题:
(1)TransUNet仅计算了同一尺度feature之间的self-attention,忽略了跨尺度特征之间的依赖性、语义一致性;而后者通常在大小规模净长变化的病灶分割中占据关键作用。
(2)除了建立全局的上下文关联,它没有考虑到如何建模不同语义类别之间的关联,如何保证同一语义类别区域下的特征一致性。
这些都对基于CNN的分割网络模型设计至关重要。
因此本文为了解决以上局限性,提出了多类别复合Transformer(MCTrans),它可以提取丰富的上下文特征,并且挖掘语义之间的关联,从而进行精确的医学图像分割。
![[Transformer]MCTrans:Multi-Compound Transformer for Accurate Biomedical Image Segmentation_第1张图片](http://img.e-com-net.com/image/info8/5e7944474dce4fc1a0226a1df4ade1da.jpg)
Fig 1对比了建模上下文的不同方法。a-c都是计算同一尺度下不同像素之间的关联,而MCTrans(d)能够实现跨尺度下不同像素之间关系的建模。
Fig 2展示了MCTrans的示意图,其中Encoder部分还是要借助CNN提取网路特征,随后将提取到的特征映射成token,送入MCTransformer中的self-attention模块提取多尺度的上下文信息;在这一部分还添加了一个proxy embeddings来学习特征之间的交互作用、不同语义类别之间的依赖关系;经过Cross-Attention处理后送入Decoder中,在Decoder中会将token处理成2D特征图,并且逐步合并以生成最后的分割结果。
MCTrans克服了前述问题的限制:
(1)通过Transformer中的SA模块来建立全局像素之间的交互作用,可以获得不同尺度下更为丰富的特征表述;
(2)通过proxy embedding和Transformer中的CA模块学习不同语义类别之间的交互、依赖信息。本文认为这样可以有效的提升同一类别下的特征关联以及不同类别下的特征差别。
![[Transformer]MCTrans:Multi-Compound Transformer for Accurate Biomedical Image Segmentation_第2张图片](http://img.e-com-net.com/image/info8/65550eb1198641bfaa694dcb51bc921c.jpg)
本文的主要工作总结如下:
(1)提出的MCTrans可以有效的建立不同尺度之间的依赖关系和特征之间的关联从而进行精确的医学图像分割;
(2)提出了一种新的可训练的proxy embedding,通过SA和CA来建立类别之间的依赖性和增强特征表述;
(3)本文提出的MCTrans可以方便的集合进UNet网络类型,并且在6个具有挑战的数据集上均达到了SOTA。实验结果证明了本文提出的网络结构的有效性。
Section II Related Work
Attention Mechanisms
注意力机制被用于建立像素级别上下文之间的关联。比如AttentionUNet中引入注意力门来highlight目标区域,抑制不相关的区域;而CSNet则进一步引入通道注意力来建模上下文之间的依赖关系;还有的通过non-local operations来建模像素对之间的关系;上述方法主要聚焦于在单一尺度上建立像素之间的语义关联或空间关联;但却忽略了跨尺度范围上更丰富的信息。
因此本文借助Transformer来构建多尺度特征之间的依赖关系,通过不同尺度之间的信息交换获得更精确的特征表示。
Transformer
Transformer最初提出用于解决NLP领域中的机器翻译问题,通过SA可以对所有输入之间进行信息交换。最近Transformer被用于计算机视觉领域,如图像分类、语义分割、目标检测和目标跟踪。在医学图像分割任务中,TransUNet是在UNet encoder提取的最高级feature map后使用Transformer layer来建立全局之间的关联,但是上述方法不是专门为医学图像分割设计的,本文的工作重点在于研究一种更好的基于Transformer的方法,充分利用注意力机制的优点进行医学图像分割。
Section III Mulit-Compound Transformer Network
正如Fig 2所示,本文在UNet的Encoder-Decoder之中引入了Transformer结构,主要包括TSA和TCA模块,TSA主要用于对多个特征之间的上下文信息进行编码,从而产生丰富且一致的像素级别的上下文;后者则是加入了可训练的proxy对语义关系进行建模,并且进一步增强了特征表示。
对于HXW的输入图像,首先通过CNN来提取不同尺度的特征图,而feature map是以patch为单位进行提取的;然后不同尺度的feature map会展开并投影成不同token;本文会将不同尺度的feature map级联之后,一起映射获得token束;
为了弥补空间信息的丢失,增加了positiona embedding部分提供相对位置信息。
随后将嵌入了位置信息的token束作为Transformer的输入,这样会计算不同尺度特征之间的关联;
经过SA计算之后的tokens会进一步送入TCA模块,一同输入的还有proxy embedding的结果,其中M设置为数据集的类别数目。
最后会将token展回不同尺度的feature map,经过decoder得到最终的分割结果。
![[Transformer]MCTrans:Multi-Compound Transformer for Accurate Biomedical Image Segmentation_第3张图片](http://img.e-com-net.com/image/info8/1eaf9ab9266f4c68b8b92b8ec1ebf84b.jpg)
Part 1 Transformer-Self-Attention(TSA)
TSA模块的输入是1D Token,主要是采集不同尺度特征之间的上下文依赖关系。Fig 3(a)展示了TSA的具体结构,可以看到包含MSA层+AddNorm层+FFN层+AddNorm层,并且使用了残差连接,FFN中包含两次线性层和ReLU做非线性激活,因此对于第l层的计算,注意力的计算是:
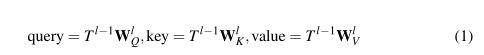
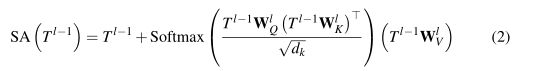
MSA则是SA的扩展,会采用多个attention head计算注意力,并将多个头的结果级联之后作为最终输出。
![]()
![]()
为了简化表述,本文忽略了LN层计算。
需要注意的一点是,序列长度T会很长,因此计算MSA式复杂度是T的平方,这也限制了SA的使用。因此本文使用的是Deformable Self-Attention(DSA)来替代SA的计算,DSA会对要计算的序列进行稀疏,从而减小注意力的计算复杂度。
Part 2 Transformer-Cross-Attention(TCA)
Fig 2(b)展示了TCA的结构,TCA同TSA模块一样,包含AttentionLayer,LN,AddNorm层,但是使用了两个MHSA模块。
此外对于第j层,proxy embedding还会对前一层的K,Q,V进行线性投影,结果输入到TCA模块的第一个SA模块中,通过对每一对类别进行连接和交互从而建立不同类别的语义之间的联系;随后proxy embedding的结果作为query输入,本层encoder的token作为key和value输入第二个MSA模块。
通过MSA,使得本层的token特征可以与学习到的全局语义信息进行交互,从而提升类内特征一致性和类间可区分性。
本文还引入额外的福主损失函数Laux来进行proxy embedding的训练;也就是说TCA最后一层的输出会经过线性映射并进行类别预测Pred,借助Pred和GT计算损失来进行proxy的训练,督促proxy学习同一语义类别之间的特征、不同种类之间的差别。
最后token会复原会2D形成不同尺度的feature map,然后以自下而上的方法逐步合并获得最终的分割图。
Section IV Experiments
Datasets
本文在6个分割数据集上对MCTrans进行了评估,分别是:
Pannuke dataset:细胞分割数据集,包含6类共7904张病理图像
CVC-Clinic等4个数据集:结肠镜、腹腔图像
ISIC2018:皮肤损伤分割数据集
评估指标:Dice Similarity Coefficient
对比网络是常规的CNN网络,基于VGG或ResNet作为特征提取器;
损失函数:BCE和dice loss
使用了数据增强-图像翻转
训练卡:1块V100
A
![[Transformer]MCTrans:Multi-Compound Transformer for Accurate Biomedical Image Segmentation_第4张图片](http://img.e-com-net.com/image/info8/f67d6df05fca4a07b200be35f708c0e3.jpg)
**
blation Studies**
本文还通过消融实验验证MCTrans各部分的重要性,使用VGG作为网络助管,Table 1展示了不同网络结构在Pannuke数据集上的分割结果,可以看到通过添加TSA,性能比UNet提升到了67.93%;为了进一步证明构建多尺度像素之间关联的重要性,本文还在UNet顶层的feature map使用了non-local和Transformer的Encoder部分用来限制只使用同一尺度下的信息交互,发现精度远远低于本文的方法。
本文进一步评估了TCA模块的作用,发现添加TCA学习到的语义先验知识可以帮助构建上下文的语义依赖关系,将基线模型和MCTrans模型精度分别提升至67.16%和68.40%.这表明学习语义之间的关联对增强特征表述的有效性。
本文还研究了移除辅助损失函数的影响,精度会掉到67.87%。
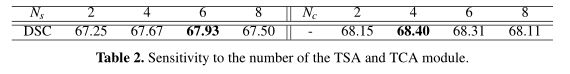
Sensitivity to the Setting
本文还探究网络设定对精度的影响,比如TSA,TCA模块的数量,结果参见Table 2。
可以看到TSA数目逐渐增多精度会先升高后下降;固定TSA数目后进一步插入TCA模块并增加TCA模块的数量,依旧是先增加后减小。这间接表明当在较小数据集上训练时模块的数量、容量并不是越大越好。
![[Transformer]MCTrans:Multi-Compound Transformer for Accurate Biomedical Image Segmentation_第5张图片](http://img.e-com-net.com/image/info8/bf221102e0ea422a8ef87f5028f77147.jpg)
![[Transformer]MCTrans:Multi-Compound Transformer for Accurate Biomedical Image Segmentation_第6张图片](http://img.e-com-net.com/image/info8/68a90f177a1d41c6b2ff7555091c11f9.jpg)
Comparisons with SOTA
Table 3展示了MCTrans与目前SOTA模型的对比结果,如UNet,UNet++,CENet,AttentionUNet等。MCTrans中选用VGG作为特征提取器,可以看到借助跨层的像素级别之间的依赖关系,MCTrans性能获得了提升;第二组则是以ResNet34作为特征提取器可以看到性能获得了进一步的提升。
Fig 4则是细胞分割的一些可视化结果,可以看到MCTrans获得了最佳的分割结果。Table4则展示的是皮肤损伤数据集的对比结果。MCTrans仍然遥遥领先,体现出了MCTrans的通用性。
Table 3也对比了不同网络之间的参数量、计算量,可以看到与UNet基线模型相比。MCTrans在几乎相同的参数量、轻微的计算增加前提下性能提高了3.64%;而像UNet++计算量、参数量更多性能却逊于MCTrans。
Section V Conclusion
本文提出了一种有效的基于Transformer的医学图像分割网络-MCTrans。通过注意力机制有效的提取了丰富的上下文信息,挖掘语义信息之间的关联,有效解决了多尺度特征的依赖性、不同类别的语义关联等问题。本文的MCTrans在多种分割任务上均达到了SOTA,充分证明了其有效性。