encoder decoder模型_Pytorch学习记录-Transformer(数据预处理和模型结构)

Pytorch学习记录-torchtext和Pytorch的实例6
0. PyTorch Seq2Seq项目介绍
在完成基本的torchtext之后,找到了这个教程,《基于Pytorch和torchtext来理解和实现seq2seq模型》。 这个项目主要包括了6个子项目
- ~~使用神经网络训练Seq2Seq~~
- ~~使用RNN encoder-decoder训练短语表示用于统计机器翻译~~
- ~~使用共同学习完成NMT的堆砌和翻译~~
- ~~打包填充序列、掩码和推理~~
- ~~卷积Seq2Seq~~
- Transformer
6. Transformer
OK,来到最后一章,Transformer,又回到这个模型啦,绕不开的,依旧没有讲解,只能看看代码。 来源不用说了,《Attention is all you need》。Transformer在之前复习了多次,这次也一样,不知道教程会如何实现,反正之前学得挺痛苦的。
6.1 准备数据
这里使用了一个新的数据集TranslationDataset,机器翻译数据集是 TranslationDataset 类的子类。
import torchimport torch.nn as nnimport torch.optim as optimimport torch.nn.functional as Fimport torchtext#机器翻译数据集是 TranslationDataset 类的子类。from torchtext.datasets import TranslationDataset, Multi30kfrom torchtext.data import Field, BucketIteratorimport spacyimport randomimport mathimport osimport timeSEED=1234random.seed(SEED)torch.manual_seed(SEED)torch.backends.cudnn.deterministic=Truespacy_de = spacy.load('de')spacy_en = spacy.load('en')def tokenize_de(text): return [tok.text for tok in spacy_de.tokenizer(text)]def tokenize_en(text): return [tok.text for tok in spacy_en.tokenizer(text)]SRC=Field(tokenize=tokenize_de, init_token='', eos_token='', lower=True, batch_first=True)TRG=Field(tokenize=tokenize_en, init_token='', eos_token='', lower=True, batch_first=True)train_data,valid_data,test_data=Multi30k.splits( exts=('.de','.en'), fields=(SRC, TRG))SRC.build_vocab(train_data,min_freq=2)TRG.build_vocab(train_data,min_freq=2)device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')print(device)BATCH_SIZE=128train_iterator, valid_iterator, test_iterator=BucketIterator.splits( (train_data,valid_data,test_data), batch_size=BATCH_SIZE, device=device)cuda6.2 构建模型
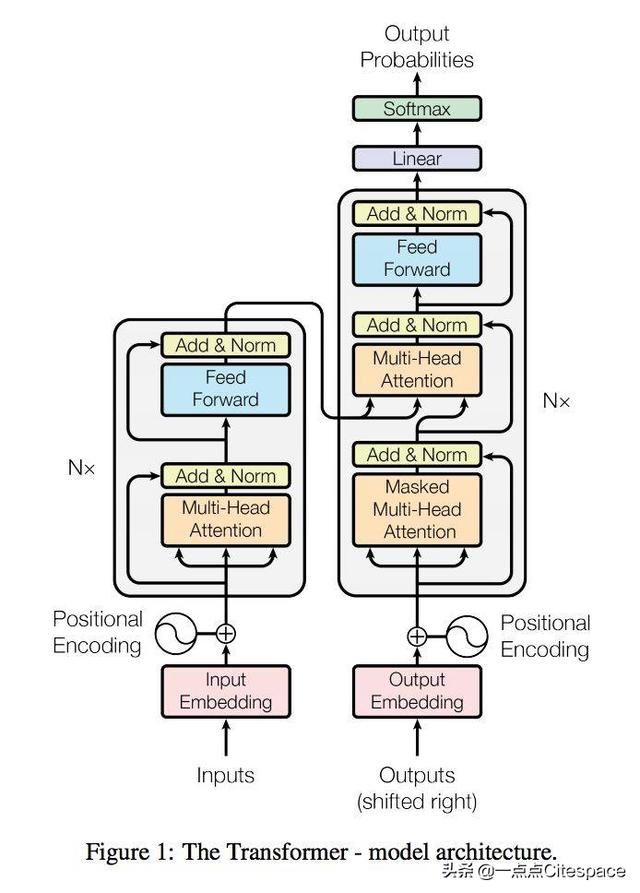
6.2.1 encoder和decoder
Transformer模型使用经典的encoer-decoder架构,由encoder和decoder两部分组成。 可以看到两侧的N_x表示encoer和decoder各有多少层。

在原始论文中,encoder和decoder都包含有6层。 encoder的每一层是由一个Multi head self-attention和一个FeedForward构成,两个部分都会使用残差连接(residual connection)和Layer Normalization。 decoder的每一层比encoder多了一个multi-head context-attention,即是说,每一层包括multi-head context-attention、Multi head self-attention和一个FeedForward,同样三个部分都会使用残差连接(residual connection)和Layer Normalization。 encoder和decoder通过context-attention进行连接。 对比会发现,红框是相同的,蓝框是多出来的那个block。
6.2.2 使用多种attention机制(multi-head context-attention、multi-head self-attention)
在图中,每块就是一个block,可以看到里面所使用的机制。似乎都有一个***-attention attention对于某个时刻的输出y,它在输入x上各个部分的注意力。这个注意力实际上可以理解为权重。
看到了encoder和decoder里面的block,就自然会考虑“什么是Attention”。
前面已经说了,Attention实际上可以理解为权重。attention机制也可以分成很多种。Attention? Attention!一文有一张比较全面的表格

6.2.2.1 multi head self-attention
attention机制有两个隐状态,分别是输入序列隐状态$hi$和输出序列隐状态$st$,前者是输入序列第i个位置产生的隐状态,后者是输出序列在第t个位置产生的隐状态。 所谓multi head self-attention实际上就是输出序列就是输入序列,即是说计算自己的attention得分,就叫做self-attention。
6.2.2.2 multi head context-attention
multi head context-attention是encoder和decoder之间的attention,是两个不同序列之间的attention,与self-attention相区别。
6.2.2.3 如何实现Attention?
Attention的实现有很多种方式,上面的表列出了7种attention,在Transformer中,使用的是scaled dot-product attention。
为什么使用scaled dot-product attention。Google给出的解答就是Q(Query)、V(Value)、K(Key),注意看看这里的描述。通过query和key的相似性程度来确定value的权重分布。
$$Attention(Q,K,V)=softmax(frac{QK^T}{sqrt{dk}})V$$ scaled dot-product attention 和 dot-product attention 唯一的区别就是,scaled dot-product attention 有一个缩放因子, 叫$frac{1}{sqrt{dk}}$。$dk$ 表示 Key 的维度,默认用 64。 使用缩放因子的原因是,对于dk很大的时候,点积得到的结果维度很大,使得结果处于softmax函数梯度很小的区域。而在梯度很小的情况时,对反向传播不利。为了克服这个负面影响,除以一个缩放因子,可以一定程度上减缓这种情况。
我们对比一下公式和论文中的图示。 $$Attention(Q,K,V)=softmax(frac{QK^T}{sqrt{d_k}})V$$

以下为实现scaled dot-product attention的算法和图示对比,我尽量搞得清楚点。

可以发现scale就是比例的意思,所以多了scale就是多了一个$frac{1}{sqrt{d_k}}$。

接下来就是一个softmax,然后与V相乘

在decoder的self-attention中,Q、K、V都来自于同一个地方(相等),它们是上一层decoder的输出。对于第一层decoder,它们就是word embedding和positional encoding相加得到的输入。但是对于decoder,我们不希望它能获得下一个time step(即将来的信息),因此我们需要进行sequence masking。可以看到里面还有一个Mask,这个在下面会详细介绍。
6.2.2.4 如何实现multi-heads attention?
理解了Scaled dot-product attention,Multi-head attention也很简单了。论文提到,他们发现将Q、K、V通过一个线性映射之后,分成h份,对每一份进行scaled dot-product attention效果更好。然后,把各个部分的结果合并起来,再次经过线性映射,得到最终的输出。这就是所谓的multi-head attention。上面的超参数h就是heads数量。论文默认是8。 Multi-head attention允许模型加入不同位置的表示子空间的信息。 我们对比一下公式和论文中的图示。

$${MultiHead}(Q,K,V) = {Concat}({head}_ 1,dots,{head}_ h)W^O$$ 其中 $${head}_ i = {Attention}(QWi^Q,KWi^K,VW_i^V)$$
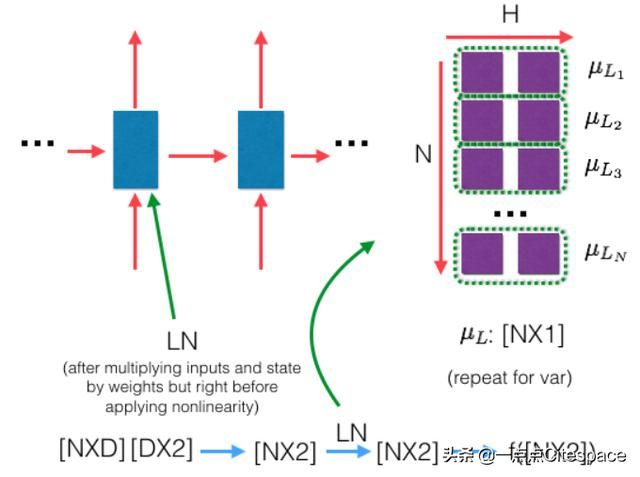
6.2.3 使用Layer-Normalization机制
Normalization的一种,把输入转化成均值为0方差为1的数据。是在每一个样本上计算均值和方差。 层归一对应的是每个block中的Norm

层归一(Layer Normalization)与批归一(Batch Normalization)的区别就在于:
- BN在每一层的每一批数据上进行归一化(计算均值和方差)
- LN在每一个样本上计算均值和方差 层归一公式 $$LN(xi)=alphaimesfrac{xi-uL}{sqrt{sigmaL^2+epsilon}}+beta$$ 其中$u_L$是x最后一个维度的均值(看实现的源码是这样解释,但是为什么是最后一个维度呢) 层归一示意图
6.2.4 使用Mask机制
用于对输入序列进行对齐。这里使用的是padding mask和sequence mask。 mask掩码,在Transformer中就是对某些值进行掩盖,使其在参数更新时不产生效果。
Transformer模型涉及两种mask。
- padding mask
- sequence mask,这个在之前decoder中已经见过,使用在multi-heads context-attention中。 其中,padding mask在所有的scaled dot-product attention里面都需要用到,而sequence mask只有在decoder的multi-heads context-attention里面用到。

- 所以,我们之前ScaledDotProductAttention的forward方法里面的参数attn_mask在不同的地方会有不同的含义。这一点我们会在后面说明。
6.2.4.1 padding mask
说白了就是对齐每一句话,每个批次输入序列长度是不一样的。就是说要以最长的那句话为标准,其他句子少一个词就填充一个0。因为这些填充的位置是没有意义的,attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
操作方法就是把这些位置的值加上一个非常大的负数(可以是负无穷),这样的话,经过softmax,这些位置的概率就会接近0。
padding mask是一个张量,每个值都是一个Boolen,值为False的地方就是我们要进行处理的地方。
6.2.4.2 sequence mask
sequence mask是为了使得decoder不能看见未来的信息。也就是对于一个序列,在time_step为t的时刻,我们的解码输出应该只能依赖于t时刻之前的输出,而不能依赖t之后的输出。因此我们需要想一个办法,把t之后的信息给隐藏起来。 这部分具体操作:产生一个上三角矩阵,上三角的值全为1,下三角的值全为0,对角线也是0。把这个矩阵作用在每一个序列上。 没看懂,好像第一次看这部分也是没看懂,等下实现的时候看看吧,不知道这句话的意思。
6.2.5 使用残差residual connection
避免梯度消失。 残差连接对应的是每个block中的add

残差连接示意图如下。

假设网络中某个层对输入x作用(比如使用Relu作用)后的输出是$F(x)$,那么增加residual connection之后,就变成了: $$F(x)+x$$ 这个+x操作就是一个shortcut。 那么残差结构有什么好处呢?显而易见:因为增加了一项x,那么该层网络对x求偏导的时候,多了一个常数项1。在反向传播过程中,梯度连乘,也不会造成梯度消失。
6.2.6 使用Positional-encoding
对序列中的词语出现的位置进行编码。这样模型就可以捕捉顺序信息。 在处理完模型的各个模块后,开始关注数据的输入部分,在这里重点是位置编码。与CNN和RNN不同,Transformer模型对于序列没有编码,这就导致无法获取每个词之间的关系,也就是无法构成有意义的语句。
为了解决这个问题。论文提出了Positional encoding。核心就是对序列中的词语出现的位置进行编码。如果对位置进行编码,那么我们的模型就可以捕捉顺序信息。
论文使用正余弦函数实现位置编码。这样做的好处就是不仅可以获取词的绝对位置信息,还可以获取相对位置信息。 $$PE(pos,2i) = sin(pos/10000^{2i/d{model}})$$ $$PE(pos,2i+1) = cos(pos/10000^{2i/d{model}})$$ 其中,pos是指词语在序列中的位置。可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码。
相对位置信息通过以下公式实现 $$sin(alpha+beta) = sinalpha cosbeta + cosalpha sinbeta$$ $$cos(alpha+beta) = cosalpha cosbeta - sinalpha sinbeta$$ 上面的公式说明,对于词汇之间的位置偏移k,$PE(pos+k)$可以表示成$PE(pos)$和$PE(k)$的组合形式,这就是表达相对位置的能力。
6.2.7 Position-wise Feed-Forward network
除了attention子层之外,encoder和decoder中的每个层都包含一个完全连接的前馈网络(Feed-forward network),该网络分别和相同地应用于每个位置。这包括两个线性变换和一个ReLU激活。 $$FFN(x)=max(0,xW1+b1)W2+b2$$ 虽然线性变换在不同位置上是相同的,但它们在层与层之间使用不同的参数。另一种描述这种情况的方法是两个内核大小为1的卷积。输入和输出的维数是512,而中间层维度为2048。