词袋模型:DBoW原理介绍以及使用方法
1. 词袋模型介绍
词袋模型在很多方面都有应用,其的原理也很容易理解:
有以下一些句子:
1. my name is jack!
2. I like to eat apples!
3. I am a student!
4. I like to take pictures!
我现在交给你一个任务,从上面四句话中找到一句和下面这句话最相似的一句(这里认为同样的单词越多越相似):
I am a boy!
请原谅我,我并没有侮辱你智商的意思! 你几乎想都没想就说出了和第3句最像。
因为上面这个例子比较简单。但是当我们的句子变成文章那么长时,我相信再让你去找就没有那么容易了。
于是我们就必须探索出一种方法,让计算机去找!
上面出现的五句话中,包含了以下这些单词,一共15个,我们就用这15个单词构造一个字典:
| I | am | a | student | like | to | eat | apples | take | pictures | my | name | is | jack | boy |
|---|
有了以上这个单词表之后,我们可以使用这个单词表来表示上面的四个句子。
对于第1句:my name is jack!
1.[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0]
提示: 用一个15维的向量来表示一个句子,这个向量和上表的单词顺序一致,如果当前句子出现了上表中的某一个单词,那么单词对应的向量位就为1,否则为0!
同理,可以得到另外几个单词的向量表示:
第2句: I like to eat apples!
2.[1, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0]
第3句:I am a student!
3.[1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
现在再来看刚才的查找任务,需要查找的句子为:I am a boy!
其对应的向量为[1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
现在用向量表示这些句子之后,再找最相似的句子就容易多了,只需要按找元素位来比较,比方说:
待查找句子的向量与第3句的向量,在第1,2,3位上都是1,所以它们的相似结果是3
同理,待查找的句子与第1句,第2句,相似结果分别是0和1
以上就是一个词袋模型的思路,但是有一点儿你需要注意,上面这个例子只是用来给你理解词袋模型的思想,其中处理问题的细节,并不具有参考性,在实际情况中可以会有多种多样的处理方法,多种多样的变体,甚至有时你都很难找到词袋模型的影子。
2.DBoW的原理
DBoW就是一种从词袋思想中走出来的算法。在视觉SLAM中它已经成为了回环检测必不可少的工具。它在SLAM中不但可以用来做回环检测,还能用来加快特征点的匹配。
它和我们上面的例子步骤是一样的,也是先创建字典,然后进行查找。
2.1 创建词汇树
DBoW创建的字典方式是通过树型结构来完成的。如下图:
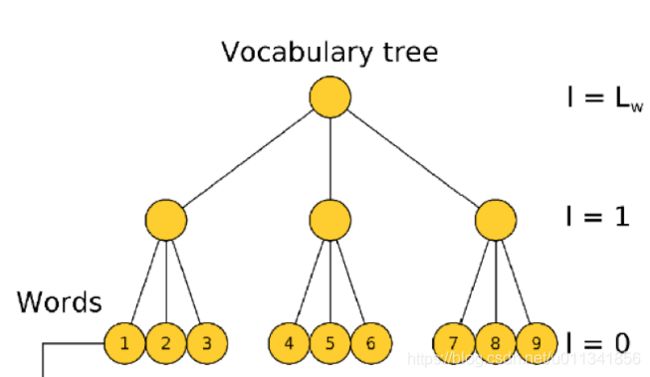
实际上真实使用的词汇树比这个大很多,为了方便只是用一棵小树进行示意!
下面来看一下这棵树是怎么得到的:
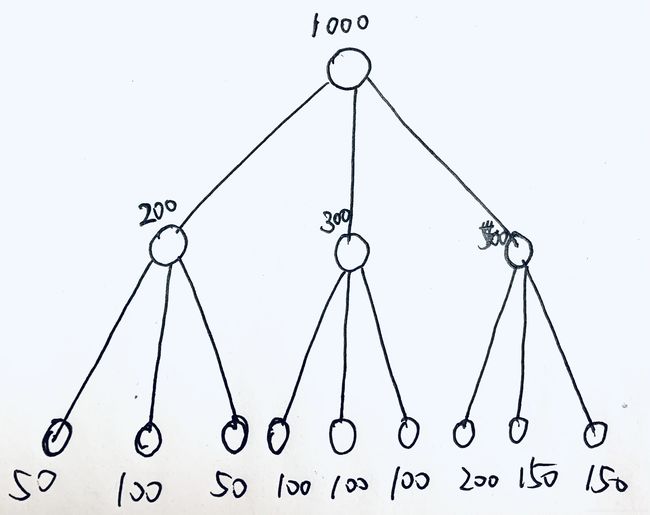
画的好丑啊!
我们现在有1000个描述子,我们先将它放在根节点里(最上面那个圆圈)
然后对这1000个点进行聚类(你竟然不知道聚类是啥!?),将其聚类为3类,然后分别将它们分配给根节点下一级的三个节点,根据聚类结果,它们分别获得了200、300和500个描述子。
然后继续对这些点分别进行聚类,对于中间层最左边的200个描述子,再进行聚类,其又被分配到了下一级节点,分别被分配了50、100、50个描述子。以此类推,就得到了整个词汇树。
这个过程就是词汇树的训练过程,当然真实的词汇树分支多,层数更深。
有一点儿还需要注意,其中每一个节点都有一个值用来表示聚类中心。例如根节点有1000个描述子,就会根据这些描述子计算一个聚类中心。类似的最下面那一层,也会根据其中被分配到的描述子计算聚类中心,而这个聚类中心就是单词(words)。因此对于这种分支为3,深度为2的词汇树,一共可以获得9个单词。
当我们保存整个训练好的词汇树时,只要把树的结构和聚类中心都保存下来就行了,其中那些用来训练的描述子都可以扔掉了。
以上过程用更加规范的句子描述:
- step1.在根节点将样本聚为k类
- step2.对第一层的每个节点,把属于该节点的样本再聚为k类
- step3.重复step2,最后得到叶子层,每个叶子对应一个word,最终得到的树就是vocabulary tree
聚类方法是kmeans++
2.2 使用词汇树
训练好了词汇树,下面就是如果使用它了。
例如,我们现在有一个分支为10,层数为5的词汇树,那么其共有单词(word)数量为100000个
例如现在有一张图像,我们对其提取了2000个特征点(关键点+描述子),然后将其每一个描述子通过词汇树找到对应的单词。

步骤为:
- step1:先将描述子放在根节点处;
- step2:然后将描述子与第一层聚类进行比较,找到与自己最相似的那个子节点,然后将其放入当前子节点;
- step3:重复step2,直到该描述子被分配了叶子节点中。
那么叶子节点在训练时得到聚类中心(其实也相当于是描述子),就是当前描述子对应的单词,然后将对每一个描述子都执行这样的操作,那么就会得到每一个描述子对应的单词。
注意:如果从图像中提取的2000个描述子,全部都落入某一个叶子节点中,那么当前图像经过词袋模型转换之后,就只有一个单词。如果2000个描述子经过词袋树之后,落入了不相同的叶子节点中,那么这张图片就有2000个单词。
这就是转换描述子为单词的过程!
你是否明白这个过程了?
在很多视觉SLAM系统中,它对每一个KeyFrame都进行了如上述的描述子转word的过程,所以每一个KeyFrame都有一个词汇向量(BowVector),当我们需要回环检测时,只需要从这些KeyFrame中找到与当前单词数最多的那个KayFrame。
理论上来说,上面的回环检测是行得通的,但是实际上单词数相似的很多,也并不一定就是真正的回环帧,所以在实际的应用中会加入非常严格的判断。这一点可以参考ORB-SLAM2的做法进行学习。
当然词汇树还有别的应用,例如加快特征点匹配过程中的搜索。再拿出那张很丑的图:
我们现在有一个描述子想要与1000个描述子进行匹配搜索,找到最近的一个,最朴素的做法是暴力匹配,做1000次比较,求出汉明距离最近的那个。但是如果稍微利用一下词汇树,情况就会容易很多,1000个描述子,进行一次聚类,可以得到第一层。我只需要去第一层中比较哪个节点的聚类中心离当前描述子最近,然后就去那个节点中进行搜索。比方说,第一层中的最左边那个节点的聚类中心离当前描述子最近,那么就只需要在这200个里面进行搜索匹配。当然还可以进一步缩小搜索空间,在这200个里面还可以根据聚类结果(第二层聚类得到的节点),进行第二层的聚类中心比较,又可以进一步缩小搜索。
简单来说,上面的步骤可以概括为,一个描述子在根节点处,与子节点的聚类中心进行比较,得到了最近的那个,然后在最近的那个节点里,在进行聚类中的比较,又获得了它的子节点,然后一层一层的缩小搜索范围。
当然不能缩到太小,太小之后,可能就会导致结果中没有这个要查找的描述子。这个道理就相当于是你想找一个叫张伟的人,然后限定了在A市找,实际上他在B市,那你在A市永远找不到它,所以此时就需要扩到查找范围。
2.3 每个单词(words)都一样重要吗?
在上面的介绍过程中,实际上忽略了一个问题,那就是每一个单词都一样重要吗?试想一下上面那个查找句子的例子,如果给你一个单词’I’你能确定是哪个句子吗?我想你不行!但是给你一个’apple’你就确定了是第二个句子。所以’I’和’apple’虽然都是单词,但是其重要程度是不一样的。
对于DBoW,它采用了一些方法量化单词的重要性。当我们拿到一棵已经建好的树,当我们进行描述子的单词匹配时,发现大量的描述子都被分配到了某一个叶子节点中,那么当前叶子节点的word权重就比较低。
DBoW算法一共提供了三种权重计算方法,其计算方法如下:
- 1.词频Term Frequency(TF):某个词在文章中出现的次数。为了归一化,词频也可以定义成,某个词在文章中出现的次数 / 文章的总词数。如果一个词比较少见,那么区分度就大。
- 2.逆向文件频率Inverse document frequency(IDF):需要一个语料库,来模拟语言的使用环境。IDF定义为,log(语料库的文档总数 / 包含该词的文档数 +1 )。如果一个词越常见,那么分母就越大,逆文档频率就越小,越接近0。
- 3.TF-IDF:词频(TF)* 逆向文件频率(IDF)。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。某个词对文章的重要性越高,它的TF-IDF值就越大。
所以当我们我们SLAM系统在运行时,不停低有KeyFrame描述子转换为单词,所以单词对应的权重也就在不停地进行更新!
3.总结
上面通过一些例子简单的介绍了DBoW的算法思想,这其中主要是介绍思路,所以并没有针对算法细节做很多介绍。如果你对算法细节有兴趣,可以参考作者的论文和源码!
如果有机会,我会写一下DBoW在ORB-SLAM2中的用法的具体细节!