pytorch 实现语义分割FCN网络(训练代码+预测代码)
一,FCN网络
FCN大致上就是下图这个结构:
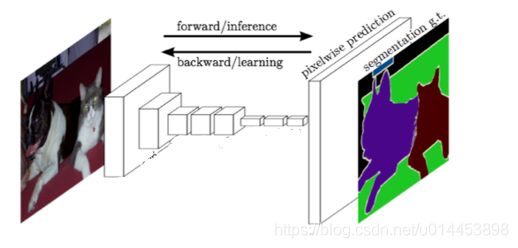

原图通过“编码器网络”把图片越缩越小,然后再通过“解码器网络”把图片再进行逐步放大。得到就结果就是一个个不同颜色的颜色块(称之为掩码),每一种颜色代表不同的类别。
FCN中一个很重要的部分---反卷积
图片通过卷积层降低分辨率,提取特征,而反卷积则是把图片重新放大的一个结构。
在语义分割中,必须对反卷积的反卷积核进行参数初始化(这点很重要)。一般使用的方法是双线性插值法。
pytorch 中反卷积函数的说明:
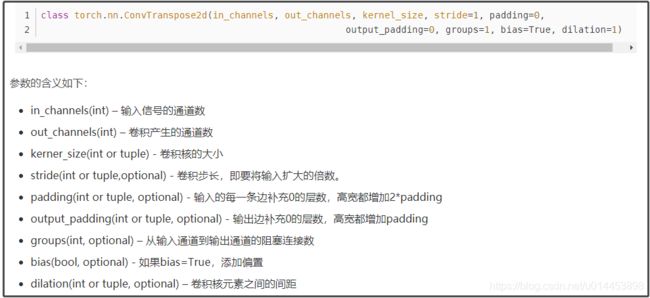
给出反卷积操作输入尺寸和输出尺寸的关系公式:


二,代码所用到的数据集:(cityspaces)
cityspaces数据集有很多个,我的是用下面的:(gtFine是label,下面的是原图)

类别数是20。
三,训练代码:
3.1 数据读取代码:
import os
import random
from PIL import Image
import torch
from torch.utils.data import Dataset
# Labels: -1 license plate, 0 unlabeled, 1 ego vehicle, 2 rectification border, 3 out of roi, 4 static, 5 dynamic, 6 ground, 7 road, 8 sidewalk, 9 parking, 10 rail track, 11 building, 12 wall, 13 fence, 14 guard rail, 15 bridge, 16 tunnel, 17 pole, 18 polegroup, 19 traffic light, 20 traffic sign, 21 vegetation, 22 terrain, 23 sky, 24 person, 25 rider, 26 car, 27 truck, 28 bus, 29 caravan, 30 trailer, 31 train, 32 motorcycle, 33 bicycle
num_classes = 20
full_to_train = {-1: 19, 0: 19, 1: 19, 2: 19, 3: 19, 4: 19, 5: 19, 6: 19, 7: 0, 8: 1, 9: 19, 10: 19, 11: 2, 12: 3, 13: 4, 14: 19, 15: 19, 16: 19, 17: 5, 18: 19, 19: 6, 20: 7, 21: 8, 22: 9, 23: 10, 24: 11, 25: 12, 26: 13, 27: 14, 28: 15, 29: 19, 30: 19, 31: 16, 32: 17, 33: 18}
train_to_full = {0: 7, 1: 8, 2: 11, 3: 12, 4: 13, 5: 17, 6: 19, 7: 20, 8: 21, 9: 22, 10: 23, 11: 24, 12: 25, 13: 26, 14: 27, 15: 28, 16: 31, 17: 32, 18: 33, 19: 0}
full_to_colour = {0: (0, 0, 0), 7: (128, 64, 128), 8: (244, 35, 232), 11: (70, 70, 70), 12: (102, 102, 156), 13: (190, 153, 153), 17: (153, 153, 153), 19: (250, 170, 30), 20: (220, 220, 0), 21: (107, 142, 35), 22: (152, 251, 152), 23: (70, 130, 180), 24: (220, 20, 60), 25: (255, 0, 0), 26: (0, 0, 142), 27: (0, 0, 70), 28: (0, 60,100), 31: (0, 80, 100), 32: (0, 0, 230), 33: (119, 11, 32)}
class CityscapesDataset(Dataset):
def __init__(self, split='train', crop=None, flip=False):
super().__init__()
self.crop = crop
self.flip = flip
self.inputs = []
self.targets = []
for root, _, filenames in os.walk(os.path.join('/home/home_data/zjw/cityspaces', 'leftImg8bit', split)):
for filename in filenames:
if os.path.splitext(filename)[1] == '.png':
filename_base = '_'.join(filename.split('_')[:-1])
target_root = os.path.join('/home/home_data/zjw/cityspaces', 'gtFine', split, os.path.basename(root))
self.inputs.append(os.path.join(root, filename_base + '_leftImg8bit.png'))
self.targets.append(os.path.join(target_root, filename_base + '_gtFine_labelIds.png'))
def __len__(self):
return len(self.inputs)
def __getitem__(self, i):
# Load images and perform augmentations with PIL
input, target = Image.open(self.inputs[i]), Image.open(self.targets[i])
# Random uniform crop
if self.crop is not None:
w, h = input.size
x1, y1 = random.randint(0, w - self.crop), random.randint(0, h - self.crop)
input, target = input.crop((x1, y1, x1 + self.crop, y1 + self.crop)), target.crop((x1, y1, x1 + self.crop, y1 + self.crop))
# Random horizontal flip
if self.flip:
if random.random() < 0.5:
input, target = input.transpose(Image.FLIP_LEFT_RIGHT), target.transpose(Image.FLIP_LEFT_RIGHT)
# Convert to tensors
w, h = input.size
input = torch.ByteTensor(torch.ByteStorage.from_buffer(input.tobytes())).view(h, w, 3).permute(2, 0, 1).float().div(255)
target = torch.ByteTensor(torch.ByteStorage.from_buffer(target.tobytes())).view(h, w).long()
# Normalise input
input[0].add_(-0.485).div_(0.229)
input[1].add_(-0.456).div_(0.224)
input[2].add_(-0.406).div_(0.225)
# Convert to training labels
remapped_target = target.clone()
for k, v in full_to_train.items():
remapped_target[target == k] = v
# Create one-hot encoding
target = torch.zeros(num_classes, h, w)
for c in range(num_classes): #把taget变成 类别数x高x宽 ==>类别数x一个面
target[c][remapped_target == c] = 1 #每一类占一个面,原图里A类的像素点坐标(i,j),那么在属于A类的(i,j)处设为1
return input, target, remapped_target # Return x, y (one-hot), y (index)
代码的上面部分有三个列表,分别是:
full_to_train,train_to_full,full_to_colour。
关于cityspaces的label其实是很长的:(一共有34个)
# Labels: -1 license plate, 0 unlabeled, 1 ego vehicle, 2 rectification border, 3 out of roi, 4 static, 5 dynamic, 6 ground, 7 road, 8 sidewalk, 9 parking, 10 rail track, 11 building, 12 wall, 13 fence, 14 guard rail, 15 bridge, 16 tunnel, 17 pole, 18 polegroup, 19 traffic light, 20 traffic sign, 21 vegetation, 22 terrain, 23 sky, 24 person, 25 rider, 26 car, 27 truck, 28 bus, 29 caravan, 30 trailer, 31 train, 32 motorcycle, 33 bicycle代表label图片中,会含有少于等于34种数字。而网络只处理20个类别,所以要把34类映射到20类。
从代码看出,label是以_gtFine_labelIds.png结尾的图片:(就是红色框那种)
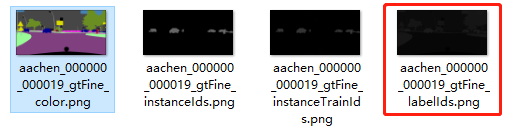
为什么会那么暗呢?label为什么不是第一张而是红色框的呢?
1.上面四张其实都是同一张原图的label,只是看你 用哪一种而已。
2.红色框那种暗的原因是图片的值全是 -1~33的某些值。
这四张的输入原图如下:

说回full_to_train,train_to_full,full_to_colour:
full 就是 读入的label图,train是把full中-1~33 的值转换为 0~19 ,达到34类映射成20类的效果。
而full_to_colour:就是哪一种类别对应的 rgb 值。
3.2 模型代码:
import torch
from torch import nn
from torch.nn import init
from torchvision.models.resnet import BasicBlock, ResNet
# Returns 2D convolutional layer with space-preserving padding
def conv(in_planes, out_planes, kernel_size=3, stride=1, dilation=1, bias=False, transposed=False):
if transposed:
layer = nn.ConvTranspose2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=1, output_padding=1, dilation=dilation, bias=bias)
# Bilinear interpolation init 用双线性插值法初始化反卷积核
w = torch.Tensor(kernel_size, kernel_size)
centre = kernel_size % 2 == 1 and stride - 1 or stride - 0.5
for y in range(kernel_size):
for x in range(kernel_size):
w[y, x] = (1 - abs((x - centre) / stride)) * (1 - abs((y - centre) / stride))
layer.weight.data.copy_(w.div(in_planes).repeat(in_planes, out_planes, 1, 1))
else:
padding = (kernel_size + 2 * (dilation - 1)) // 2
layer = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, bias=bias)
if bias:
init.constant(layer.bias, 0)
return layer
# Returns 2D batch normalisation layer
def bn(planes):
layer = nn.BatchNorm2d(planes)
# Use mean 0, standard deviation 1 init
init.constant(layer.weight, 1)
init.constant(layer.bias, 0)
return layer
class FeatureResNet(ResNet):
def __init__(self):
super().__init__(BasicBlock, [3, 4, 6, 3], 1000) #特征提取用resnet
def forward(self, x):
x1 = self.conv1(x)
x = self.bn1(x1)
x = self.relu(x)
x2 = self.maxpool(x)
x = self.layer1(x2)
x3 = self.layer2(x)
x4 = self.layer3(x3)
x5 = self.layer4(x4)
return x1, x2, x3, x4, x5
class SegResNet(nn.Module):
def __init__(self, num_classes, pretrained_net):
super().__init__()
self.pretrained_net = pretrained_net
self.relu = nn.ReLU(inplace=True)
self.conv5 = conv(512, 256, stride=2, transposed=True)
self.bn5 = bn(256)
self.conv6 = conv(256, 128, stride=2, transposed=True)
self.bn6 = bn(128)
self.conv7 = conv(128, 64, stride=2, transposed=True)
self.bn7 = bn(64)
self.conv8 = conv(64, 64, stride=2, transposed=True)
self.bn8 = bn(64)
self.conv9 = conv(64, 32, stride=2, transposed=True)
self.bn9 = bn(32)
self.conv10 = conv(32, num_classes, kernel_size=7)
init.constant(self.conv10.weight, 0) # Zero init
def forward(self, x):
x1, x2, x3, x4, x5 = self.pretrained_net(x)
x = self.relu(self.bn5(self.conv5(x5)))
x = self.relu(self.bn6(self.conv6(x + x4)))
x = self.relu(self.bn7(self.conv7(x + x3)))
x = self.relu(self.bn8(self.conv8(x + x2)))
x = self.relu(self.bn9(self.conv9(x + x1)))
x = self.conv10(x)
return x
3.3 训练代码:
from argparse import ArgumentParser
import os
import random
from matplotlib import pyplot as plt
import torch
from torch import optim
from torch import nn
from torch.nn import functional as F
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import models
from torchvision.utils import save_image
from data import CityscapesDataset, num_classes, full_to_colour, train_to_full
from model import FeatureResNet, SegResNet
# Setup
parser = ArgumentParser(description='Semantic segmentation')
parser.add_argument('--seed', type=int, default=42, help='Random seed')
parser.add_argument('--workers', type=int, default=8, help='Data loader workers')
parser.add_argument('--epochs', type=int, default=100, help='Training epochs')
parser.add_argument('--crop-size', type=int, default=512, help='Training crop size')
parser.add_argument('--lr', type=float, default=5e-5, help='Learning rate')
parser.add_argument('--momentum', type=float, default=0, help='Momentum')
parser.add_argument('--weight-decay', type=float, default=2e-4, help='Weight decay')
parser.add_argument('--batch-size', type=int, default=16, help='Batch size')
args = parser.parse_args()
random.seed(args.seed)
torch.manual_seed(args.seed)
if not os.path.exists('results'):
os.makedirs('results')
plt.switch_backend('agg') # Allow plotting when running remotely
# Data
train_dataset = CityscapesDataset(split='train', crop=args.crop_size, flip=True)
val_dataset = CityscapesDataset(split='val')
train_loader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, num_workers=args.workers, pin_memory=True)
val_loader = DataLoader(val_dataset, batch_size=1, num_workers=args.workers, pin_memory=True)
# Training/Testing
pretrained_net = FeatureResNet()
pretrained_net.load_state_dict(models.resnet34(pretrained=True).state_dict())
net = SegResNet(num_classes, pretrained_net).cuda()
crit = nn.BCELoss().cuda()
# Construct optimiser
params_dict = dict(net.named_parameters())
params = []
for key, value in params_dict.items():
if 'bn' in key:
# No weight decay on batch norm
params += [{'params': [value], 'weight_decay': 0}]
elif '.bias' in key:
# No weight decay plus double learning rate on biases
params += [{'params': [value], 'lr': 2 * args.lr, 'weight_decay': 0}]
else:
params += [{'params': [value]}]
optimiser = optim.RMSprop(params, lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay)
scores, mean_scores = [], []
def train(e):
net.train()
for i, (input, target, _) in enumerate(train_loader):
optimiser.zero_grad()
input, target = Variable(input.cuda(async=True)), Variable(target.cuda(async=True))
output = F.sigmoid(net(input))
loss = crit(output, target)
print(e, i, loss.item())
loss.backward()
optimiser.step()
# Calculates class intersections over unions
def iou(pred, target):
ious = []
# Ignore IoU for background class
for cls in range(num_classes - 1):
pred_inds = pred == cls
target_inds = target == cls
intersection = (pred_inds[target_inds]).long().sum().data.cpu().item() # Cast to long to prevent overflows
union = pred_inds.long().sum().data.cpu().item() + target_inds.long().sum().data.cpu().item() - intersection
if union == 0:
ious.append(float('nan')) # If there is no ground truth, do not include in evaluation
else:
ious.append(intersection / max(union, 1))
return ious
def test(e):
net.eval()
total_ious = []
for i, (input, _, target) in enumerate(val_loader):
input, target = Variable(input.cuda(async=True), volatile=True), Variable(target.cuda(async=True), volatile=True)
output = F.log_softmax(net(input))
b, _, h, w = output.size()
pred = output.permute(0, 2, 3, 1).contiguous().view(-1, num_classes).max(1)[1].view(b, h, w)
total_ious.append(iou(pred, target))
# Save images
if i % 25 == 0:
pred = pred.data.cpu()
pred_remapped = pred.clone()
# Convert to full labels
for k, v in train_to_full.items():
pred_remapped[pred == k] = v
# Convert to colour image
pred = pred_remapped
pred_colour = torch.zeros(b, 3, h, w)
for k, v in full_to_colour.items():
pred_r = torch.zeros(b, 1, h, w)
#print('pred shape:{}'.format(pred.shape))
#print('k:{}'.format(k))
pred = pred.reshape(1,1,h,-1)
#print('pred shape:{}'.format(pred.shape))
pred_r[(pred == k)] = v[0]
pred_g = torch.zeros(b, 1, h, w)
pred_g[(pred == k)] = v[1]
pred_b = torch.zeros(b, 1, h, w)
pred_b[(pred == k)] = v[2]
pred_colour.add_(torch.cat((pred_r, pred_g, pred_b), 1))
save_image(pred_colour[0].float().div(255), os.path.join('results', str(e) + '_' + str(i) + '.png'))
# Calculate average IoU
total_ious = torch.Tensor(total_ious).transpose(0, 1)
ious = torch.Tensor(num_classes - 1)
for i, class_iou in enumerate(total_ious):
ious[i] = class_iou[class_iou == class_iou].mean() # Calculate mean, ignoring NaNs
print(ious, ious.mean())
scores.append(ious)
# Save weights and scores
torch.save(net, os.path.join('results', str(e) + '_net.pth'))
torch.save(scores, os.path.join('results', 'scores.pth'))
# Plot scores
mean_scores.append(ious.mean())
es = list(range(len(mean_scores)))
plt.plot(es, mean_scores, 'b-')
plt.xlabel('Epoch')
plt.ylabel('Mean IoU')
plt.savefig(os.path.join('results', 'ious.png'))
plt.close()
test(0)
for e in range(1, args.epochs + 1):
train(e)
test(e)
运行后的结果:

其中红色框为 保存下来的模型。每次测试(test)都会保存下结果。
随便讲一下test()里面的一行代码:
pred = output.permute(0, 2, 3, 1).contiguous().view(-1, num_classes).max(1)[1].view(b, h, w)网络里运行的数据是torch tensor格式的,它的维度定义为(batchsize,通道数,高,宽),而输出后一半用numpy格式处理数据,numpy的维度定义是(batchsize,高,宽,通道数)
所以 permute(0,2,3,1)就是把维度转换过来。
接着contiguous()是为view()操作做准备的。
view()是改变矩阵的形状,-1表示行数待定,列数为num_classes(即类别数),(总的类别数除num_class就得到行数了,当然这个代码自己做了)。假设第一个view之后得到的矩阵维度为(A,num_classes):
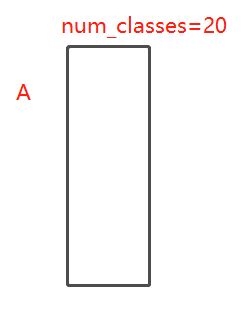
A就是所有像素点的个数了。上面的矩阵就表示每个像素点属于各个类别的概率。然后代码来了个max(1),什么意思?就是选出每一个像素数属于哪个类别嘛,选出概率最大的那个类别作为该像素的类别,如下:

之后再把这个矩阵用view()转成 bxHxW。(b为batchsize,H为高度,W为宽度)
3.4 预测代码:
import torch
from PIL import Image
import random
from torchvision.utils import save_image
from torch.nn import functional as F
full_to_train = {-1: 19, 0: 19, 1: 19, 2: 19, 3: 19, 4: 19, 5: 19, 6: 19, 7: 0, 8: 1, 9: 19, 10: 19, 11: 2, 12: 3, 13: 4, 14: 19, 15: 19, 16: 19, 17: 5, 18: 19, 19: 6, 20: 7, 21: 8, 22: 9, 23: 10, 24: 11, 25: 12, 26: 13, 27: 14, 28: 15, 29: 19, 30: 19, 31: 16, 32: 17, 33: 18}
train_to_full = {0: 7, 1: 8, 2: 11, 3: 12, 4: 13, 5: 17, 6: 19, 7: 20, 8: 21, 9: 22, 10: 23, 11: 24, 12: 25, 13: 26, 14: 27, 15: 28, 16: 31, 17: 32, 18: 33, 19: 0}
full_to_colour = {0: (0, 0, 0), 7: (128, 64, 128), 8: (244, 35, 232), 11: (70, 70, 70), 12: (102, 102, 156), 13: (190, 153, 153), 17: (153, 153, 153), 19: (250, 170, 30), 20: (220, 220, 0), 21: (107, 142, 35), 22: (152, 251, 152), 23: (70, 130, 180), 24: (220, 20, 60), 25: (255, 0, 0), 26: (0, 0, 142), 27: (0, 0, 70), 28: (0, 60,100), 31: (0, 80, 100), 32: (0, 0, 230), 33: (119, 11, 32)}
path = r'/home/home_data/zjw/FCN-semantic-segmentation-master/s2.jpeg'
model = r'/home/home_data/zjw/FCN-semantic-segmentation-master/results/100_net.pth'
crop_size = 512
num_classes = 20
def test():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
net = torch.load(model)
net = net.to(device)
net.eval()
input = Image.open(path)
w,h = input.size
x1,y1 = random.randint(0,w-crop_size),random.randint(0,h-crop_size)
input = input.crop((x1,y1,x1+crop_size,y1+crop_size))
w,h = input.size
input = torch.ByteTensor(torch.ByteStorage.from_buffer(input.tobytes())).view(h,w,3).permute(2,0,1).float().div(255)
input[0].add_(-0.485).div_(0.229)
input[1].add_(-0.456).div_(0.224)
input[2].add_(-0.406).div_(0.225)
input = input.to(device)
input = input.unsqueeze(0)
output = F.log_softmax(net(input))
b,_,h,w = output.size()
pred = output.permute(0,2,3,1).contiguous().view(-1,num_classes).max(1)[1].view(b,h,w)
pred = pred.data.cpu()
pred_remapped = pred.clone()
for k,v in train_to_full.items():
pred_remapped[pred==k] = v
pred = pred_remapped
pred_colour = torch.zeros(b,3,h,w)
for k,v in full_to_colour.items():
pred_r = torch.zeros(b,1,h,w)
pred = pred.reshape(1,1,h,-1)
pred_r[(pred==k)] = v[0]
pred_g = torch.zeros(b,1,h,w)
pred_g[(pred==k)] = v[1]
pred_b = torch.zeros(b,1,h,w)
pred_b[(pred==k)] = v[2]
pred_colour.add_(torch.cat((pred_r,pred_g,pred_b),1))
print(pred_colour[0].float())
print('-----------------')
pred = pred_colour[0].float().div(255)
print(pred)
save_image(pred,r'./test_street2.png')
#save_image(pred_colour,r'./test_street2.png')
test()
上面的代码中,我们看到有一行:
pred = pred_colour[0].float().div(255)有没有疑问为什么要除255?
原因如下:https://blog.csdn.net/sdlyjzh/article/details/8245145
然后我们看看运行效果:
我们先从网上搜一张街景图:

输入到预测代码中 运行:

效果是有效果,但效果哈哈看上去好像也不是特别的好。
代码:https://github.com/Andy-zhujunwen/pytoch-FCN-train-inference-