白话机器学习-Attention
一 背景
大抵是去年底吧,收到了几个公众号读者的信息,希望能写几篇介绍下Attention以及Transformer相关的算法的文章,当时的我也是满口答应了,但是确实最后耽误到了现在也没有写。
前一阵打算写这方面的文章,不过发现一个问题,就是如果要介绍Transformer,则必须先介绍Self Attention,亦必须介绍下Attention,以及Encoder-Decoder框架,以及GRU、LSTM、RNN和CNN,所以开始漫长的写作之旅。
截止目前,已经完成几篇文章的输出
- 《白话机器学习-卷积神经网络CNN》
- 《白话机器学习-循环神经网络RNN》
- 《白话机器学习-长短期记忆网络LSTM》
- 《白话机器学习-循环神经网络概述从RNN到LSTM再到GRU》
- 《白话机器学习-Encoder-Decoder框架》
那么接下来,需要把Attention机制、Self Attention以及Transformer一一介绍了。
本文主要介绍Attention机制。
那么为何要引入Attention呢,个人认为主要有几点:
- 更长时间的依赖,尽管LSTM与GRU也可以解决这个问题,但是有一定的缺陷
- LSTM与GRU是顺序串行计算的模式,计算的性能有所限制
- Attention可以实现不同时序数据间的关联,同时由于网络结构可以实现并行矩阵计算。
所以从计算性能和模型性能的综合考量,在工业界,Attention被大量使用,“Attention is all your need!”。
二 Attention简介
Attention机制最早是在NLP领域发展起来的,伴随着Encoder-Decoder框架,大放异彩,极大的提升了翻译模型等的性能,逐步的替代了基于传统算法的翻译模型。
Attention机制通过预测词与每个单词打分,会对不同的单词给予不同的关注权重。然后使用softmax分数进行归一化权重,我们使用编码器隐藏状态的加权和来聚合编码器隐藏状态,以得到上下文向量。
结合Encoder-Decoder框架,我们逐步的讲解Attention机制,实现可以分为4个步骤。虽然本文是结合Encoder-Decoder框架进行讲解,但是并非Attention机制只能用在这里,其实在搜广推领域都已经在大规模的使用,比如搜索场景,通过搜索词与用户历史浏览、点击、购买进行注意力机制建模,都可以取得不错的效果,这里多说两句,搜广推模型的要点我个人觉得有几点:
- 模型够大,记忆与衍生能力更强,通过框架支持稀疏大规模EMB减少碰撞,使得模型学的更加充分;
- 序列用起来,最开始的时候使用LSTM、GRU等,但是搜广推模型比较大,性能问题逐步都切换到Attention;
- 实时反馈,Online Learning跑起来,但是这个需要强大的基建,超大模型训练与在线一体,便捷的回退、上线操作;
额,跑题了,我还是继续介绍Attention吧,喜欢的同学给点掌声!
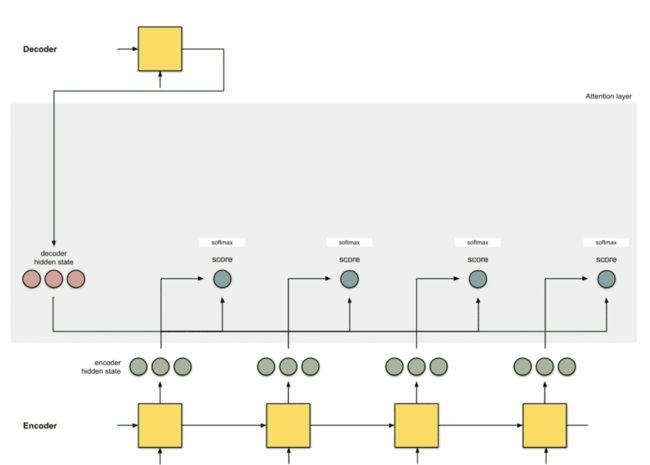
1 准备工作
让我们首先准备所有可用的编码器隐藏状态(绿色)和第一个解码器隐藏状态(红色)。在我们的示例中,我们有4个编码器隐藏状态和当前解码器隐藏状态。(注意:最后一个合并编码器隐藏状态作为输入输入到解码器的第一个时间步。解码器第一个时间步的输出称为第一个解码器隐藏状态,如下图所示。)

2 计算初始分数
本步骤的功能主要是计算初始分数(标量)由Score函数(也称为比对分数函数或比对模型)获得。在本例中,Score函数是解码器和编码器隐藏状态之间的点积。 评分函数还是比较多的,后面参考里面会罗列一些。

decoder_hidden = [10, 5, 10]
encoder_hidden score
---------------------
[0, 1, 1] 15 (= 10×0 + 5×1 + 10×1, the dot product)
[5, 0, 1] 60
[1, 1, 0] 15
[0, 5, 1] 35
在上面的例子中,对于编码器隐藏状态[5,0,1],我们获得了60分的高关注度(相对其他的点)。这意味着下一个单词(解码器的下一个输出)将受到这个编码器隐藏状态的非常大影响。
3 通过Softmax计算归一分数
本步骤的功能主要是,通过Softmax函数将上面计算的Score进行归一化操作计算归一化的分数。
encoder_hidden score score^
-----------------------------
[0, 1, 1] 15 0
[5, 0, 1] 60 1
[1, 1, 0] 15 0
[0, 5, 1] 35 0
注意,基于Softmax计算我们发现注意的分布只在[5,0,1]上。实际上,这些数字不是二进制的,而是0到1之间的浮点数。
4 计算对齐向量组
本步骤的功能主要是,通过自身Softmax归一化分数score^与自身向量数乘,得到对齐向量组。

encoder score score^ alignment
---------------------------------
[0, 1, 1] 15 0 [0, 0, 0]
[5, 0, 1] 60 1 [5, 0, 1]
[1, 1, 0] 15 0 [0, 0, 0]
[0, 5, 1] 35 0 [0, 0, 0]
在这里我们可以看到,除了[5,0,1]之外,所有编码器隐藏状态的对齐都由于注意力得分较低而降低到0。这意味着我们可以期望第一个翻译的单词应该与[5,0,1]嵌入较为匹配输入单词。
5 融合对齐向量组,生成对齐向量
本步骤的功能主要是完成对齐向量组的融合与聚合,一般的方式将全部的对齐向量组进行按位累加。

encoder score score^ alignment
---------------------------------
[0, 1, 1] 15 0 [0, 0, 0]
[5, 0, 1] 60 1 [5, 0, 1]
[1, 1, 0] 15 0 [0, 0, 0]
[0, 5, 1] 35 0 [0, 0, 0]
context = [0+5+0+0, 0+0+0+0, 0+1+0+0] = [5, 0, 1]
6 融合自身与对齐向量
本步骤的功能主要是对齐向量与自身如何融合的问题,融合的方式上面提到过,有很多种,比如在concact模式下,具体的计算如粉色远点与相邻的绿色原点连接。

三 Multi Head Attention
这块会后续和Self Attention以及Transformer一起介绍,请大家静候。
所谓多头就是多个几套参数,基于理念就是不同的主体之间的关系是有很多种的,一个Attention不足以进行刻画,需要多个Attention进行刻画,所以就需要多个参数了。整体感觉吧,干咱们这行的得是社会学与心理学的达人,或者有这种资质,要不呢,很多事情吧,可能像不明白。至于说数学,是非常重要的,但是吧,有时候不能太严谨,毕竟机器学习是玄学。
四 参考资料
[1] Neural Machine Translation by Jointly Learning to Align and Translate (Bahdanau et. al, 2015)
[2] Effective Approaches to Attention-based Neural Machine Translation (Luong et. al, 2015)
[3] Attention Is All You Need (Vaswani et. al, 2017)
[4] Self-Attention GAN (Zhang et. al, 2018)
[5] Sequence to Sequence Learning with Neural Networks (Sutskever et. al, 2014)
[6] TensorFlow’s seq2seq Tutorial with Attention (Tutorial on seq2seq+attention)
[7] Lilian Weng’s Blog on Attention (Great start to attention)
[8] Jay Alammar’s Blog on Seq2Seq with Attention (Great illustrations and worked example on seq2seq+attention)
[9] Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation (Wu et. al, 2016)
五 番外篇
介绍:杜宝坤,互联网行业从业者,十五年老兵。精通搜广推架构与算法,并且从0到1带领团队构建了京东的联邦学习解决方案9N-FL,同时主导了联邦学习框架与联邦开门红业务。
个人比较喜欢学习新东西,乐于钻研技术。基于从全链路思考与决策技术规划的考量,研究的领域比较多,从工程架构、大数据到机器学习算法与算法框架、隐私计算均有涉及。欢迎喜欢技术的同学和我交流,邮箱:[email protected]
六 公众号导读
自己撰写博客已经很长一段时间了,由于个人涉猎的技术领域比较多,所以对高并发与高性能、分布式、传统机器学习算法与框架、深度学习算法与框架、密码安全、隐私计算、联邦学习、大数据等都有涉及。主导过多个大项目包括零售的联邦学习,社区做过多次分享,另外自己坚持写原创博客,多篇文章有过万的阅读。公众号秃顶的码农大家可以按照话题进行连续阅读,里面的章节我都做过按照学习路线的排序,话题就是公众号里面下面的标红的这个,大家点击去就可以看本话题下的多篇文章了,比如下图(话题分为:一、隐私计算 二、联邦学习 三、机器学习框架 四、机器学习算法 五、高性能计算 六、广告算法 七、程序人生),知乎号同理关注专利即可。

一切有为法,如梦幻泡影,如露亦如电,应作如是观。