基于课程学习(Curriculum Learning)的自然语言理解

©PaperWeekly 原创 · 作者|张琨
学校|中国科学技术大学博士生
研究方向|自然语言处理

论文标题:
Curriculum Learning for Natural Language Understanding
论文作者:
Benfeng Xu, Licheng Zhang , Zhendong Mao, Quan Wang, Hongtao Xie and Yongdong Zhang
论文链接:
https://www.aclweb.org/anthology/2020.acl-main.542/

动机
伴随着 Bert 等预训练模型在自然语言处理领域的全面铺开,在预训练模型上进行 fine-tune 已经成为当前自然语言处理各种研究的一个标配。在微调阶段,目标数据会被一股脑的抛给模型,用于训练一个在具体任务上的模型。
但数据集中的数据之间是存在难易程度的,有些例子很容易被区分,有些例子就很难被区分,例如下图展示的 SST-2 情感分类任务上的一个数据样例,简单的例子可以直接利用一些词进行分类,例如 easy,comfortable 等,但一些比较困难的例子就需要模型能够对句子中的具体片段内容进行语义理解和分析了。
如果把这些样例不加区分直接扔给模型,那么就可能出现模型在简单例子上用力过猛,在复杂例子上不够用力,从而导致模型难以训练,同时难以取得更好的效果。而人在学习过程中基本上是从易到难的,先学简单的,在学复杂的,这称之为课程学习(Curriculum Learning)。
因此,本文的一个 motivation 就是将课程学习的思路应用到自然语言理解的相关任务中。


方法
通过从易到难的形式实现对模型更好的训练不是一个新的 idea,从 CV 到 NLP 都有一些研究,主流的研究方案是两阶段的,第一阶段,对问题进行分类,构建从易到难的数据集,第二阶段,利用第一阶段得到的数据进行第二阶段的训练。
本文的优势在于,本文并不是针对某一种特定的任务进行优化的,而是提出了一种更 general 的方案,然后在阅读理解,句子分类,句子对相似度分析三个任务上进行了验证。接下来,我们就来看一下本文是如何完成这两个阶段的。
2.1 第一阶段:难度评估
传统的方法使用上下文的长度,非常见词的频率,学习目标的尺度等方案对数据进行困难评估,但作者认为,既然是针对任务的,那么这些难度评估也是需要是跟对应的任务以及对应的评价目标相关的,因此,作者将整个训练数据通过如下步骤进行困难评估,相关的图例如下图所示:

将整个训练数据分为 N 份,称之为 meta-set,然后利用每一份数据训练一个 teacher 模型。N 份数据之间不重叠。
在所有的 teacher 模型训练好之后,假设从第 k 个 meta-set 中选出一个例子,然后利用剩余的 N-1 个模型对这个例子进行预测,预测的结果就是每个模型对这个例子的困难度评估(通过这种形式,难度评估就和模型以及评价标准联系起来了)。
最后将得到的 N-1 个结果相加,就得到了这个例子的难度。
作者称这个过程为交叉评估。
2.2 课程安排
在得到每个训练例子的难度之后,作者对数据集进行划分,然后根据划分之后的例子对模型进行多阶段的学习,具体而言,首先根据难度对样例进行排序,然后分为 N 份,这样就得到了 N 份从易到难的训练集,该过程可以表示为如下形式:
![]()
然后对于每阶段的训练,作者分别从每一个难度类(buckets)里调出 1/N 个例子,然后组成短拳对应的训练集,对模型进行训练,从而让保证模型对各种数据都能看到,该过程可以表示为如下形式:
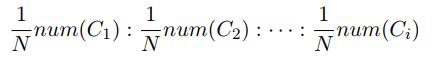
作者称这种方法为退火方法(Annealing method)。

Experiments
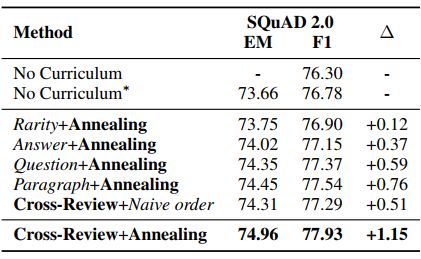
为了验证模型的有效性,作者在多个数据集和多个任务上进行了验证,主要针对的 BERT 模型,以下是在 GLUE 上的表现:

除此之外,作者还对比了其他一些课程学习的放下的效果,具体结果如下:
还有对数据集进行划分时,不同 N 对整个模型效果的影响:

除此之外,作者还对不同难度划分下的子集中数据的具体情况进行分析,相关结果如下图所示:
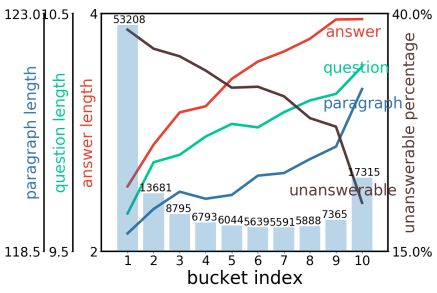
这些实验都充分证明了本文提出的方法的有效性。

总结
本文通过课程学习的形式,将数据集从易到难进行分类,在此基础上对模型进行训练,从而进一步提高了预训练模型在 fine-tune 阶段的效果,思路非常有意思。而且关于数据难度的定义和评估是这种课程学习方法的难点所在,如何提出更好的学习方法是进一步提升模型效果的关键所在。而且也不需要复杂的结构,是一个非常有意思的研究方向。
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

