【转】知乎 —— AdaIN 笔记
这个博客写的不要太好,强烈推荐并转载。【https://zhuanlan.zhihu.com/p/158657861】
AdaIN 笔记

Liewschild
计算机视觉练习生,中国科学院大学硕士在读
论文Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization的阅读笔记
ICCV 2017的一篇论文,有点老,不过是一篇很棒的论文,做了非常多的实验,靠谱、实在,对我的研究也有非常大的帮助。
风格迁移主要3个指标,迁移速度,风格类别数、迁移结果的质量(这个凭肉眼观测的属性感觉还是比较主观),作者说,作为成年人,我全都要。之前的研究要么就是比较慢,要么就是可供前的风格数量有限,这篇论文的主要目标是实现实时的、任意风格的风格迁移(style transfer),主要方法就是自适应实例标准化(Adaptive Instance Normalization,AdaIN),将内容图像(content image)特征的均值和方差对齐到风格图像(style image)的均值和方差。此外,这个方法还给用户非常多的控制权,包括内容和风格的折中(trade off),风格插值(混合风格迁移),是否保留颜色,对图像的哪个区域进行风格迁移[1]。
话不多说,先上图感受一下效果,第一行为content image,提供内容,第一列为style image,提供风格,其余为风格迁移得到的结果,效果还是很不错的。

Fig.1 迁移结果,From reference [1]
一、背景知识
论文中的方法主要跟标准化(normalization)有关,这里对各种标准化操作进行一个介绍。
1、Batch Normalization
Ioffe 和 Szegedy[2]引入Batch Normalization(BN),大大简化了前向神经网络的训练。Radford等[3]发现BN在图像生成模型中也非常有效。Batch Normalization就是对一个batch中的数据进行标准化,就是每一个值减去batch的均值,除以batch的标准差,计算公式如下:
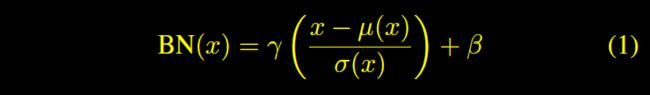
From reference [1]

From reference [1]
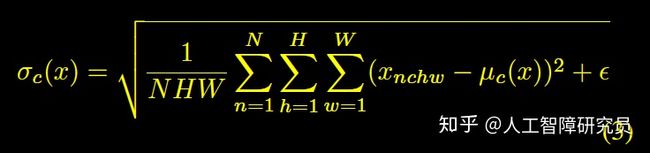
From reference [1]
其中, ![]() 分别表示计算均值和标准差,
分别表示计算均值和标准差,![]() 是仿射变换的两个参数。
是仿射变换的两个参数。
2、Instance Normalization
Ulyanov等[4]发现,将BN替换为Instance Normalization(IN),可以提升风格迁移的性能。IN的操作跟BN类似,就是范围从一个batch变成了一个instance,计算公式如下:

From reference [1]
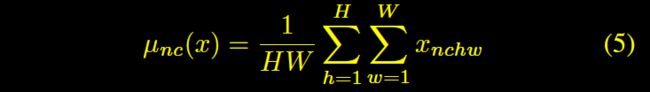
From reference [1]
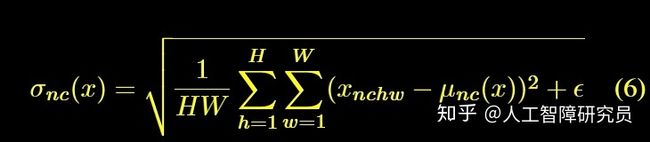
From reference [1]
3、Conditional Instance Normalization
Dumoulin等[5]提出了Conditional Instance Normalization(CIN),计算公式如下:
From reference [1]
乍一看好像没啥变化,其实不然,它在训练中会学习不同的 ![]() 对(pair)。令人惊喜的是,对于同一张content image,同一个迁移网络,使用相同的卷积层参数,使用不同的
对(pair)。令人惊喜的是,对于同一张content image,同一个迁移网络,使用相同的卷积层参数,使用不同的![]() 对,可以得到不同风格的迁移结果。为什么!先卖个关子,咱后头慢慢讲。
对,可以得到不同风格的迁移结果。为什么!先卖个关子,咱后头慢慢讲。
二、为什么Instance Normalization可以这么厉害!!!
(Conditional)Instance Normalization取得了巨大的成功,这到底是为什么呢?是道德的沦丧,还是人性的扭曲......偏了偏了,让我们一起走进实验,探索其中的奥秘。
Ulyanov等[4]将其归因于IN对content image的对比度的不变性。作者觉得,不,它不是这样的。二话不说,撸起袖子就是干,让实验结果说话
Fig.2, 实验结果,From reference [1]
作者分别用原图和对比度标准化后的图像对网络进行训练,结果(Loss收敛的速度,值)如图2中的(a)和(b)所示,可以发现并没有什么不同,IN对contrast normalized的图像依旧比BN更有效,所以对比度它不是答案的关键。
众所周知(我之前就不知道,孤陋寡闻如我),DNN提取的特征的统计特性可以代表图像的风格[6-8]。Gatys等[9]使用二阶统计特性作为优化目标;Li等[10]发现,对其他统计特性,如channel-wise的均值和方差,进行匹配,对风格迁移也是很有效的。基于上述观察,作者提出,instance normalization通过对特征的统计特性(均值和方差)进行标准化,实现了某种形式的风格标准化(style normalization)。特征的均值和方差就代表着图像的风格!为了验证自己的想法,作者又做了一个实验,先将图像迁移到同一个风格(不是目标风格),然后再进行一次风格迁移(到目标风格),结果如图2中的(c)所示,IN和BN的性能差异减小了很多。迁移到同一个风格后,BN的均值和方差和IN的均值和方差就差不多了(差多少取决于迁移的性能),所以BN和IN的性能就差不多了。没错了,是它,是它,就是它!实锤了,特征的均值和方差就代表着图像的风格!这也就解释了为什么CIN使用不同的![]() 对,可以得到不同风格的迁移结果。
对,可以得到不同风格的迁移结果。
三、重点来了:Adaptive Instance Normalization
在BN,IN,CIN中,网络会学习仿射变换参数![]() ,作者提出的AdaIN则无需学习这两个参数,直接用style image的特征的均值和标准差代替这两个参数,公式如下:
,作者提出的AdaIN则无需学习这两个参数,直接用style image的特征的均值和标准差代替这两个参数,公式如下:

From reference [1]
其中, ![]() 分别表示content image的特征的均值和标准差,
分别表示content image的特征的均值和标准差,![]() 分别表示style image的特征的均值和标准差。这个公式可以理解为,先去风格化(减去自身均值再除以自身标准差),再风格化到style image的风格(乘style image的标准差再加均值 )。
分别表示style image的特征的均值和标准差。这个公式可以理解为,先去风格化(减去自身均值再除以自身标准差),再风格化到style image的风格(乘style image的标准差再加均值 )。
网络结构如图3所示
Fig.3 网络框架,From reference [1]
训练时,先用VGG提取content image和style image的特征,然后在AdaIN模块进行式(8)的操作,然后用于VGG对称的Decoder网络将特征还原为图像,然后将还原的图像再输入到VGG提取特征,计算content loss和style loss,计算公式如式(11-13)所示,style loss会对多个层的特征进行计算。VGG的参数在训练过程中是不更新的,训练的目的是为了得到一个好的Decoder。
From reference [1]

From reference [1]

From reference [1]
四、实验结果
1、跟其他方法的比较
图4是迁移的结果,个人觉得效果最好的是Chen and Schmidt那个,但是它速度慢了些,比这篇论文慢50倍左右(见图5)。Loss我觉得这篇论文倒是降得挺低的,训练200多次迭代后就比其他都低了,但效果我感觉其实没别人的好(这件事比较主观),这说明,loss不能充分反映最后的效果会这样

Fig.4 迁移结果,From reference [1]

Fig.5 迁移速度、风格数量,From reference [1]
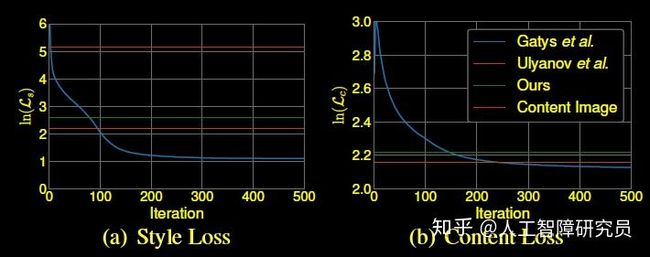
Fig.6 两个Loss,From reference [1]
2、看看其他方法效果怎么样
Enc-AdaIN-Dec: 论文中的方法
Enc-Concat-Dec: 将AdaIN替换为串联操作,即把content image会和style image的特征简单串联起来
Enc-AdaIN-BNDec: 在DEcoder中加入BN
Enc_AdaIN-INDec: 在DEcoder中加入IN
图7(d)中可以看到(a)中鸭子的轮廓,说明网络没能把style image的style和content解耦好,与图8中content loss很大相对应;(e)和(d)效果很差,style loss也很大,(e)效果尤其差。这也在此验证了作者的想法,Normalization会将风格进行标准化(或者说,去风格化),这与我们想生成不同风格图像的目标相左,所以效果自然不好。

Fig.7 不同方法的迁移结果,From reference [1]
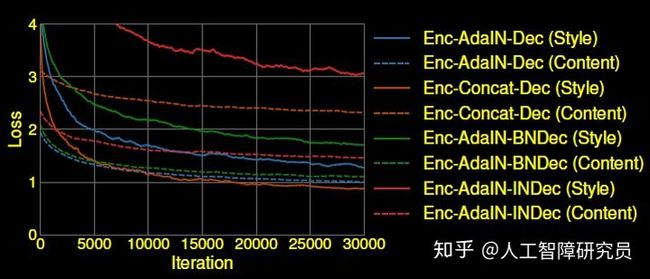
Fig.8 不同方法的Loss,From reference [1]
3、content和style的折中
用户可以通过参数 ![]() 来控制content和style的折中,
来控制content和style的折中, ![]() 越大,风格迁移得越好,但内容的保存得越少,如图9所示
越大,风格迁移得越好,但内容的保存得越少,如图9所示

Fig.9 content与style的折中,From reference [1]
4、多风格的混合
如图10所示,四个顶点是4张style image,中间是迁移结果,混合了4张图像的style,离style image越近,风格也越靠近该图

Fig.10 多风格混合迁移,From reference [1]
5、色彩控制
如图11所示,左半边大图为content image,右上角小图为style image,如果直接迁移,得到的图的颜色跟style image会很像,通过色彩控制选项,可以保存原图的色彩,效果如图11右半边所示

Fig.11 色彩控制,From reference [1]
6、空间控制
将一张图像的不同区域迁移到不同风格,效果如图12所示

Fig.12 空间控制,From reference [1]
Reference
[1] Huang, Xun, and Serge Belongie. "Arbitrary style transfer in real-time with adaptive instance normalization." InProceedings of the IEEE International Conference on Computer Vision, pp. 1501-1510. 2017.
[2] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In JMLR, 2015
[3] A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. In ICLR, 2016.
[4] D. Ulyanov, A. Vedaldi, and V. Lempitsky. Improved texture networks: Maximizing quality and diversity in feed-forward stylization and texture synthesis. In CVPR, 2017.
[5] V. Dumoulin, J. Shlens, and M. Kudlur. A learned representation for artistic style. In ICLR, 2017.
[6] L. A. Gatys, A. S. Ecker, andM. Bethge. Image style transfer using convolutional neural networks. In CVPR, 2016.
[7] C. Li and M. Wand. Combining markov random fields and convolutional neural networks for image synthesis. In CVPR, 2016.
[8] Y. Li, N. Wang, J. Liu, and X. Hou. Demystifying neural style transfer. arXiv preprint arXiv:1701.01036, 2017.
[9] L. A. Gatys, A. S. Ecker, andM. Bethge. Image style transfer using convolutional neural networks. In CVPR, 2016.
[10]Y. Li, N. Wang, J. Liu, and X. Hou. Demystifying neural style transfer. arXiv preprint arXiv:1701.01036, 2017.