Cascade R-CNN 详细解读
原文链接:Cascade R-CNN 详细解读

写这篇文章是希望对原文进行解析,帮助大家理解文章的精髓,如有错误的地方还希望指正。
从文章的题目上我们就可以看出来这篇文章目标是提高检测质量,希望能获得更精确的检测结果。文章提出的cascade结构的效果是惊艳的,几乎对于任意的R-CNN(Faster rcnn,FPN,R-FCN等)都可以带来2到4个点的AP提升!!!而且实现十分简单,已使用Pytorch在Pascal VOC上复现论文。
此外,本篇文章的实验讲解部分对于理解R-CNN网络有很大的帮助,建议详细阅读。
本篇解析的内容结构
1.简单回顾R-CNN结构
2.解释mismatch问题
3.对文章中的实验分析
4.总结
5.个人想法
1. 简单回顾R-CNN结构

首先,以经典的Faster R-CNN为例。整个网络可以分为两个阶段,training阶段和inference阶段,如上图所示。
a. training阶段,RPN网络提出了2000左右的proposals,这些proposals被送入到Fast R-CNN结构中,在Fast
R-CNN结构中,首先计算每个proposal和gt之间的iou,通过人为的设定一个IoU阈值(通常为0.5),把这些Proposals分为正样本(前景)和负样本(背景),并对这些正负样本采样,使得他们之间的比例尽量满足(1:3,二者总数量通常为128),之后这些proposals(128个)被送入到Roi
Pooling,最后进行类别分类和box回归。
b. inference阶段,RPN网络提出了300左右的proposals,这些proposals被送入到Fast
R-CNN结构中,和training阶段不同的是,inference阶段没有办法对这些proposals采样(inference阶段肯定不知道gt的,也就没法计算iou),所以他们直接进入Roi
Pooling,之后进行类别分类和box回归。
在这里插一句,在R-CNN中用到IoU阈值的有两个地方,分别是Training时Positive与Negative判定,和Inference时计算mAP。论文中强调的IoU阈值指的是Training时Positive和Negative判定处。
2. 解释mismatch问题

一张图说明问题,在上面这张图中,把RPN提出的Proposals的大致分布画了下,横轴表示Proposals和gt之间的iou值,纵轴表示满足当前iou值的Proposals数量。
--------在training阶段,由于我们知道gt,所以可以很自然的把与gt的iou大于threshold(0.5)的Proposals作为正样本,这些正样本参与之后的bbox回归学习。
--------在inference阶段,由于我们不知道gt,所以只能把所有的proposal都当做正样本,让后面的bbox回归器回归坐标。
我们可以明显的看到training阶段和inference阶段,bbox回归器的输入分布是不一样的,training阶段的输入proposals质量更高(被采样过,IoU>threshold),inference阶段的输入proposals质量相对较差(没有被采样过,可能包括很多IoU
3. 对文章中的实验分析
3.1 单纯提高IoU阈值带来的问题
提高检测的精确度,换句话说就是产生更高精度的box,那么我们可以提高产生正样本的IoU阈值,这样后面的detector接收到了更高精度的proposals,自然能产生高精度box。但是这样就会产生两个问题:
1.过拟合问题。提高了IoU阈值,满足这个阈值条件的proposals必然比之前少了,容易导致过拟合。
2.更严重的mismatch问题。前面我们说到,R-CNN结构本身就有这个问题,IoU阈值再提的更高,这个问题就更加严重。
上面的两个问题都会导致性能的下降,论文作者做了下面的的实验,证明问题确实存在。

上图中表示RPN的输出proposal在各个IoU范围内的数量。可以看到,IoU在0.6,0.7以上的proposals数量很少,直接提高IoU阈值,确实有可能出现上述两个问题。
接着,论文作者继续用实验说话,做了3组实验,分别表示IoU阈值取0.5,0.6,0.7时,proposals的分布与检测精度。
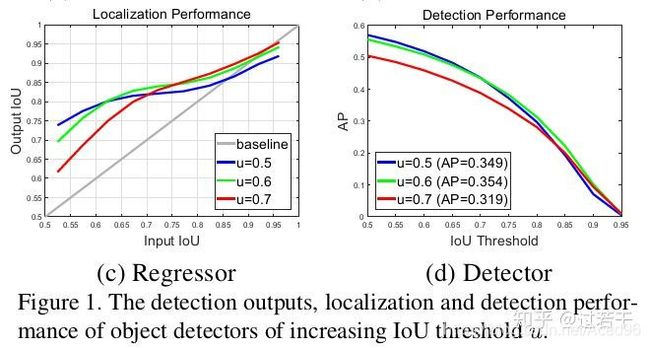
(c )图中横轴表示RPN的输出proposal的IoU,纵轴表示proposal经过box reg的新的IoU。可以得出以下结论:
1.只有proposal自身的阈值和训练器训练用的阈值较为接近的时候,训练器的性能才最好。(这个我暂时没有找到理论支持,只能从实验上看出来)
2.如果两个阈值相距比较远,就是我们之前说的mismatch问题了。
3.单一阈值训练出的检测器效果非常有限,单一阈值不能对所有的Proposals都有很好的优化作用。
(d)图中横轴表示inference阶段,判定box为tp的IoU阈值,纵轴为mAP。可以看到IoU阈值从0.5提到0.7时,AP下降很多。
3.2 Cascade结构与相似的结构对比
既然单一一个阈值训练出的检测器效果有限,作者就提出了muti-stage的结构,每个stage都有一个不同的IoU阈值。如下图(d):

可以看到不止作者一个人想到过muti-stage的结构(图b,c),作者讨论了cascade结构和另外两种结构的不同之处,以及为什么cascade结构更优秀。
3.2.1 和Iterative BBox比较
Iterative BBox的H位置都是共享的,而且3个分支的IoU阈值都取0.5。Iterative BBox存在的问题:
1.我们已经知道单一阈值0.5,是无法对所有proposal取得良好效果的。
2.此外,detector会改变样本的分布,这时候再使用同一个共享的H对检测肯定是有影响的。作者做了下面的实验证明样本分布在各个stage的变化。
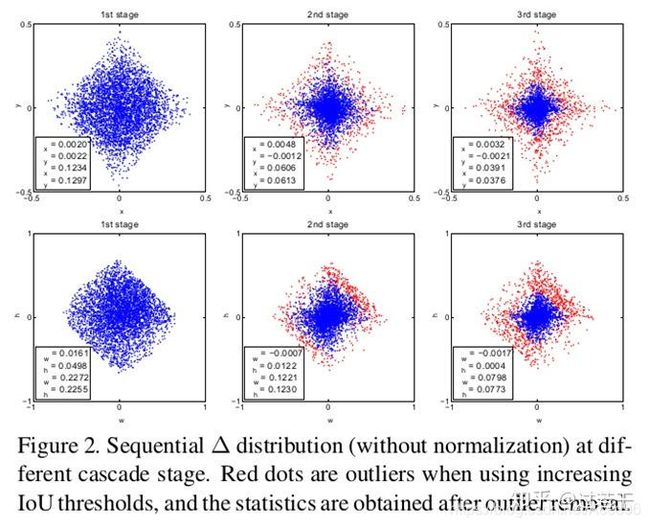
3.可以看到每经过一次回归,样本都更靠近gt一些,质量也就更高一些,样本的分布也在逐渐变化。如果还是用0.5的阈值,在后面两个stage就会有较多离群点,使用共享的H也无法满足detector的输入的变化。
从上面这个图也可以看出,每个阶段cascade都有不同的IoU阈值,可以更好地去除离群点,适应新的proposal分布。
3.2.2 和Integral Loss比较
Integral Loss共用pooling,只有一个stage,但有3个不共享的H,每个H处都对应不同的IoU阈值。Integral Loss存在的问题:
1.我们从下面的proposal分布可以看到,第一个stage的输入IoU的分布很不均匀,高阈值proposals数量很少,导致负责高阈值的detector很容易过拟合。
2.此外在inference时,3个detector的结果要进行ensemble,但是它们的输入的IoU大部分都比较低,这时高阈值的detector也需要处理低IoU的proposals,它就存在较严重的mismatch问题,它的detector效果就很差了。

从上面这个图也可以看出,每个阶段cascade都有足够的样本,不会容易过拟合。
4. 总结
RPN提出的proposals大部分质量不高,导致没办法直接使用高阈值的detector,Cascade R-CNN使用cascade回归作为一种重采样的机制,逐stage提高proposal的IoU值,从而使得前一个stage重新采样过的proposals能够适应下一个有更高阈值的stage。
1.每一个stage的detector都不会过拟合,都有足够满足阈值条件的样本。
2.更深层的detector也就可以优化更大阈值的proposals。
3.每个stage的H不相同,意味着可以适应多级的分布。
4.在inference时,虽然最开始RPN提出的proposals质量依然不高,但在每经过一个stage后质量都会提高,从而和有更高IoU阈值的detector之间不会有很严重的mismatch。
5. 个人想法
我们既然知道了R-CNN的mismatch问题,以后可以往这个方向想想解决方案,重新构建一个pipline等。