使用PyTorch进行深度学习-TensorBoard 可视化模型、数据和训练
在之前的内容中, 已经展示了如何加载数据, 通过我们定义nn.Module的子类模型 , 在训练数据上训练该模型,并在测试数据上对其进行测试。 还打印出一些模型在训练过程中的统计数据以了解训练是否在进行中。 但是,PyTorch 与 TensorBoard可以做得更好,它是一种用于可视化神经网络训练运行结果的工具。 本次使用Fashion MNIST(使用 torchvision.datasets 导入 PyTorch )数据集演示了它的一些功能。
- 读入数据并进行适当的转换(与之前的教程几乎相同)。
- 设置TensorBoard。
- 写入TensorBoard。
- 使用TensorBoard观察模型架构。
- 使用TensorBoard在上一节创建中一个可视化的交互式版本,用代码更少
在第 5 点,我们将看到: 检查我们的训练数据的几种方法、如何在训练时跟踪模型的性能、训练后如何评估我们的模型的性能。我们将从与CIFAR-10教程中类似的样板代码开始:
# 导入包
import matplotlib.pyplot as plt
import numpy as np
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 数据的转换
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
# 加载数据集
trainset = torchvision.datasets.FashionMNIST('./data',
download=True,
train=True,
transform=transform)
testset = torchvision.datasets.FashionMNIST('./data',
download=True,
train=False,
transform=transform)
# 数据加载器
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
# 类别名称
classes = ('T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle Boot')
# 创建一个函数来显示图像
# (用于下面的“plot_classes_preds”函数)
def matplotlib_imshow(img, one_channel=False):
if one_channel:
img = img.mean(dim=0)
img = img / 2 + 0.5 # 逆标准化
npimg = img.numpy()
if one_channel:#如果只有一个通道,直接输出
plt.imshow(npimg, cmap="Greys")
else: #如果是多通道,换维后输出
plt.imshow(np.transpose(npimg, (1, 2, 0)))我们从中定义一个类似的模型体系结构,只做一些修改,以说明图像现在是一个通道而不是三个通道,输入图像大小是28x28而不是32x32:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 4 * 4)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()定义与之前相同的优化器optimizer和损失函数criterion:
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)1. TensorBoard 设置
现在我们将设置 TensorBoard,从 torch.utils 中导入 tensorboard 并定义一个 SummaryWriter,这是我们将信息写入 TensorBoard 的关键对象。
from torch.utils.tensorboard import SummaryWriter
# 默认的'log_dir'是“runs”-在这里会更具体
writer = SummaryWriter('runs/fashion_mnist_experiment_1')用法:writer = SummaryWriter(log_dir='logs',flush_secs=60)
其中log_dir是tensorboard文件的存放路径,flush_secs:表示写入tensorboard文件的时间间隔。仅此行就创建了一个 runs/fashion_mnist_experiment_1 文件夹。
2、写入 TensorBoard
现在,让我们使用make_grid在TensorBoard上写一个图像。
#获取一些随机的训练图像
dataiter = iter(trainloader)
images, labels = dataiter.next()
# 创建图像网格
img_grid = torchvision.utils.make_grid(images)
# 展示图片
matplotlib_imshow(img_grid, one_channel=True)
# 写入tensorboard
writer.add_image('four_fashion_mnist_images', img_grid)关于SummaryWriter函数的详细介绍
pytorch_数据展示_SummaryWriter的两个函数_Marshal~的博客-CSDN博客_summarywriter函数
接下来的操作在pycharm的终端进行。在终端出输入:tensorboard --logdir=runs 就可以获得网址,点击后出现:
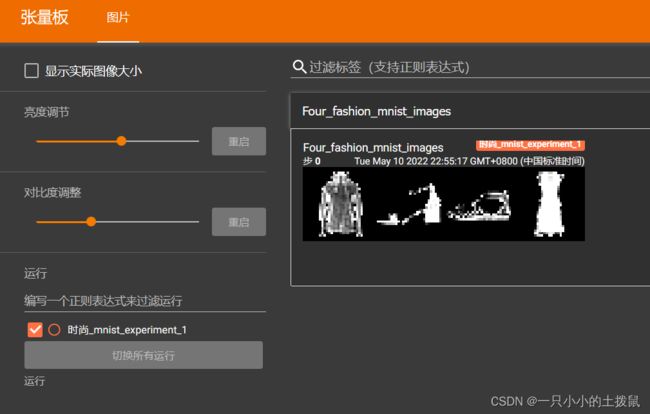
现在知道如何使用 TensorBoard了,这个例子可以在 Jupyter Notebook 中完成 - TensorBoard 真正擅长的地方在于创建交互式可视化,接下来介绍其中之一。
3. 使用 TensorBoard 检查模型
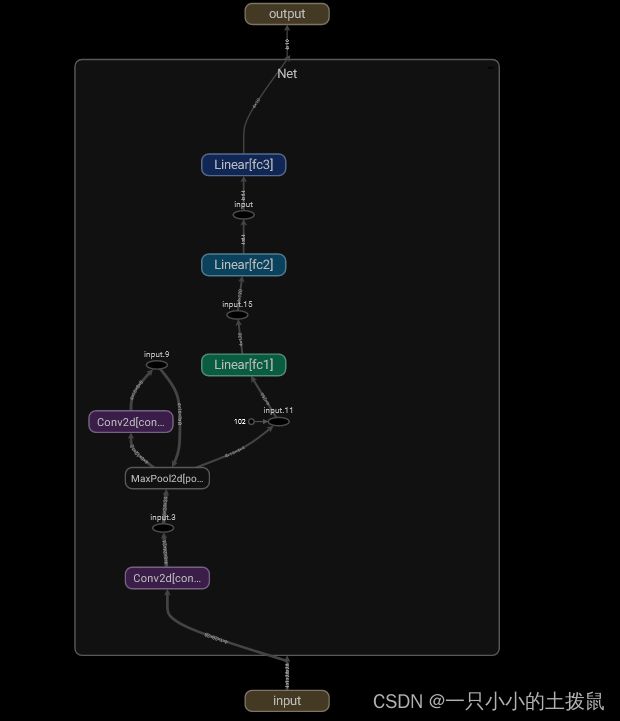
TensorBoard的优势之一是能够可视化复杂的模型结构。让我们可视化一下建立的模型。
writer.add_graph(net, images)
writer.close()现在,在刷新TensorBoard时,会看到一个“Graphs”选项卡,如下所示:

双击“Net”查看它的扩展,查看组成模型的各个操作的详细视图。TensorBoard有一个非常方便的功能,用于可视化高维数据,例如低维空间中的图像数据。
4、将“投影”添加到TensorBoard
我们可以通过 add_embedding 方法可视化高维数据的低维表示。
import tensorflow as tf
import tensorboard as tb
tf.io.gfile = tb.compat.tensorflow_stub.io.gfile
# 功能函数
def select_n_random(data, labels, n=100):
'''
从数据集中选择n个随机数据点及其相应的标签
'''
assert len(data) == len(labels)
perm = torch.randperm(len(data))
return data[perm][:n], labels[perm][:n]
# 选择随机图像及其目标索引
images, labels = select_n_random(trainset.data, trainset.targets)
# 获取每个图像的类标签
class_labels = [classes[lab] for lab in labels]
# 日志嵌入
features = images.view(-1, 28 * 28)
writer.add_embedding(features,
metadata=class_labels,
label_img=images.unsqueeze(1))
writer.close()现在在TensorBoard的“投影仪”选项卡中,可以看到这100幅图像——每幅都是784维的——投影到三维空间中。此外,这是交互式的:可以单击并拖动以旋转三维投影。最后,让可视化更容易看到的几个技巧:选择左上角的“颜色:标签”,以及启用“夜间模式”,这将使图像更容易看到,因为它们的背景是白色的:
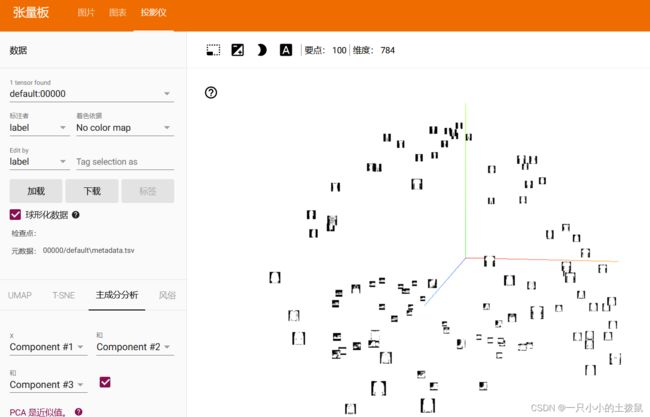
现在,我们已经彻底检查了数据,从训练开始,展示TensorBoard如何使跟踪模型训练和评估。
5. 使用 TensorBoard 进行跟踪模型训练
在上一个示例中,我们只是每2000次迭代打印一次模型的损失。现在,我们将把损失记录到TensorBoard上,并通过plot_classes_preds函数查看模型所做的预测。
def plot_classes_preds(net, images, labels):
'''
使用经过训练的网络和图像生成matplotlib图形以及一批中的标签,显示了网络的最高预测
用它的概率,加上实际的标签,给这个基于预测是否正确的信息。使用“图像到问题”功能。
'''
preds, probs = images_to_probs(net, images)
# 绘制批次中的图像,以及预测和真实标签
fig = plt.figure(figsize=(12, 48))
for idx in np.arange(4):
ax = fig.add_subplot(1, 4, idx + 1, xticks=[], yticks=[])
matplotlib_imshow(images[idx], one_channel=True)
ax.set_title("{0}, {1:.1f}%\n(label: {2})".format(
classes[preds[idx]],
probs[idx] * 100.0,
classes[labels[idx]]),
color=("green" if preds[idx] == labels[idx].item() else "red"))
return fig最后,让我们使用之前教程中相同的模型训练代码来训练模型,但是每 1000 批将结果写入 TensorBoard,而不是打印到控制台; 这是使用 add_scalar 函数完成的。此外,当我们训练时,我们将生成一张图像,显示模型的预测与该批次中包含的四张图像的实际结果。
running_loss = 0.0
for epoch in range(1): # loop over the dataset multiple times
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 1000 == 999: # every 1000 mini-batches...
# ...log the running loss
writer.add_scalar('training loss',
running_loss / 1000,
epoch * len(trainloader) + i)
# ...log a Matplotlib Figure showing the model's predictions on a
# random mini-batch
writer.add_figure('predictions vs. actuals',
plot_classes_preds(net, inputs, labels),
global_step=epoch * len(trainloader) + i)
running_loss = 0.0
print('Finished Training')现在可以查看标量选项卡以查看在 15,000 次训练迭代中绘制的运行损失:
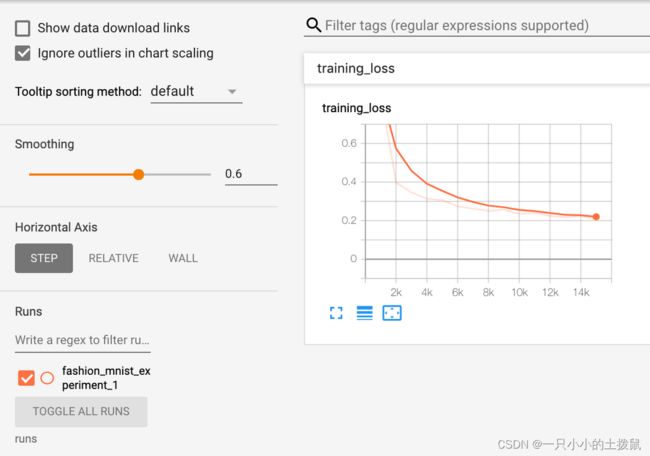
此外,我们可以查看模型在整个学习过程中对任意批次的预测。查看“图像”选项卡,并在“预测与实际值”可视化下向下滚动以查看此内容;这向我们展示了,例如,经过3000次训练迭代后,该模型已经能够区分视觉上不同的类别,如衬衫、运动鞋和外套,尽管它并不像在以后的训练中那样自信:

在之前的教程中,我们查看了模型经过训练后的每类准确率; 在这里,我们将使用 TensorBoard 为每个类绘制精确召回曲线(这里有很好的解释)。
6.使用TensorBoard评估经过训练的模型
# 1. gets the probability predictions in a test_size x num_classes Tensor
# 2. gets the preds in a test_size Tensor
# takes ~10 seconds to run
class_probs = []
class_label = []
with torch.no_grad():
for data in testloader:
images, labels = data
output = net(images)
class_probs_batch = [F.softmax(el, dim=0) for el in output]
class_probs.append(class_probs_batch)
class_label.append(labels)
test_probs = torch.cat([torch.stack(batch) for batch in class_probs])
test_label = torch.cat(class_label)
# helper function
def add_pr_curve_tensorboard(class_index, test_probs, test_label, global_step=0):
'''
Takes in a "class_index" from 0 to 9 and plots the corresponding
precision-recall curve
'''
tensorboard_truth = test_label == class_index
tensorboard_probs = test_probs[:, class_index]
writer.add_pr_curve(classes[class_index],
tensorboard_truth,
tensorboard_probs,
global_step=global_step)
writer.close()
# plot all the pr curves
for i in range(len(classes)):
add_pr_curve_tensorboard(i, test_probs, test_label)现在将看到一个“PR 曲线”选项卡,其中包含每个类别的精确召回曲线。 继续闲逛; 您会看到,在某些类别中,模型具有几乎 100% 的“曲线下面积”,而在其他类别中,该面积较低:

这是对TensorBoard和PyTorch的整合的介绍。当然,你可以做TensorBoard在你的Jupyter笔记本上所做的一切,但是有了TensorBoard,你会得到默认情况下互动的视觉效果。