强大人脸检测系统MTCNN可攻破?华为提出一种可复制、可靠的攻击方法
2019-10-26 03:52:39
作者 | Edgar Kaziakhmedov、Klim Kireev、Grigorii Melnikov、Mikhail Pautov、Aleksandr Petiushko
译者 | TroyChang
编辑 | Jane
出品 | AI科技大本营(ID:rgznai100)
【导读】深度学习方法在人脸检测任务上取得了显著的成果,但这些进展带来了与深度卷积神经网络模型安全性相关的新问题,并揭露了基于DCNN的应用程序有潜在风险。即使在数字领域仅做微小的改动输入,也可能骗过神经网络。有研究已经表明,一些基于深度学习的人脸检测器不仅在数字领域而且在现实世界中都容易受到对抗性攻击。
在本文中,华为莫斯科实验室的作者们研究了著名的级联CNN人脸检测系统-MTCNN的安全性,并介绍了一种易于复制且可靠的攻击方法。作者建议在普通的黑白打印机上打印不同的人脸属性,并附在医用口罩或直接附加到人脸上。作者的方法能够在现实情况下破坏MTCNN检测器。

论文地址:
https://arxiv.org/abs/1910.06261
引言
已有研究证明,现代深度学习系统几乎是完美的人脸检测器,其性能优于人类在该领域的能力。由于这个事实,当今生活中的应用程序数量急剧增加,他们将在最需要准确性的领域(例如安全性)取代人类。由于这类算法驱动的抉择可能会带来严重后果,因此针对恶意行为的可靠性和健壮性就变得至关重要。其中一项任务就是人脸检测,作为广泛使用的FaceID的预操作,它可以跟踪犯罪分子或控制他们进出。
目前有多种深度学习方法可解决此问题,端到端的解决方案如RetinaNet,级联多个卷积网络的方案如MTCNN。尽管端到端方法在综合基准测试中显示出更好的结果,但是效果相当的级联系统通常会有更明显的速度优势。
不幸的是,有一种称为对抗攻击的技术,在某些情况下它可以欺骗几乎所有基于神经网络的系统。例如,在数字域中发生白盒攻击的情况下,由于攻击者可以访问网络上的拓扑和权重,和数字域,所以攻击者可以逐像素更改输入图像。根据最近的公开论文,现有的解决方案不能完全缓解此问题。尽管从理论的角度来看这些结果很有趣,但是在实践中,人脸检测的任务是假定处理图像是从摄像机这样的真实设备中获取的,这种真实设备是受到保护,攻击者无法直接访问输入。称为物理域攻击。尽管存在此类攻击的示例,但事实证明,它们的再现难度要大得多,因为对抗攻击往往非常脆弱。环境或照明的微小变化通常会破坏它们。为了解决此问题,文献4引入了一种称为“Expectation-over-Transformation(EoT)”的特殊技术。
在本文中,作者介绍了对MTCNN人脸检测系统实施的攻击。尽管该系统是众所周知的并且是公开的,但是没有公开的对于该人脸检测器的攻击方法。可能的原因是该系统的级联特性,让它可以抵抗对抗攻击。由于很难在整个系统上使用传统方法(类似FGSM),因此作者决定攻击其第一部分。还值得一提的是,这种攻击方法使用的是一种公开且众所周知的技术——对抗攻击;MTCNN网络已经在网上开放出来,因此该工作不违反任何法律或法规。
代码链接:
https://github.com/edosedgar/mtcnnattack
方法
MTCNN的每个子网络都有三个输出:人脸分类,边界框回归和人脸关键点。鉴于此,作者提出了四种可能的攻击方法:
-
攻击P-Net的人脸分类层;
-
攻击P-Net的边界框回归层;
-
攻击O-Net的输出层;
-
攻击整个网络。
与其他方法相比,第一种方法对结构的要求最低。因此,P-Net的人脸分类层会被用于攻击。有关提出的攻击管道(pipeline)的详细信息,可以参见图1。在以下小节中,将提供有关攻击管道(pipeline)的详细信息

图1
-
A. Expectation over Transformation
对于对抗性攻击,要在物理域取得成功,重要的一点是要具有强大的鲁棒性。可以通过前面提到的EoT技术完成此任务。在本文的情况中,作者采用了以下方式:在训练对抗性补丁时,它不会使单个图像上的损失函数最小化,而是使用由多个具有不同头部位置的图像组成的批大小图像。由于它最大程度地减少了具有不同色块尺寸和不同亮度的图片的损失,因此在现实世界中应对这些变换时应该有较强的鲁棒性。图2解释了该过程。
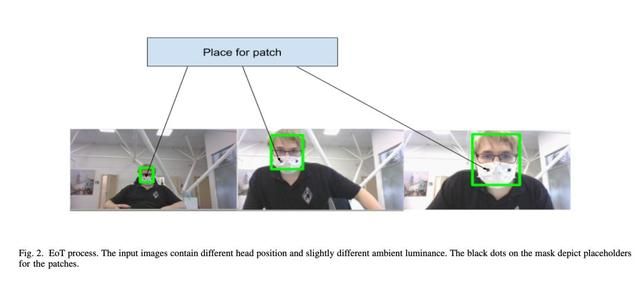
图2
-
B. 仿射变换
为了在不同的表面上使用矩形补丁,作者采用了一个映射图。映射图由八个系数(可以定义)组成。首先,在现实世界中,我们在矩形边缘标记补丁位置。如果补丁有弧形边界,则可以使用矩形网格对其进行近似。然后计算投影变换的系数,并应用补丁。如何执行该方法的示例如图3所示。

图3
-
C. MTCNN分析
一旦应用了补丁,并且扩大了生成的图像,就应该将其调整为各种比例送入P-Net。最初,MTCNN构建的是具有给定比例步长因子的图像金字塔。使用所有尺度的攻击都是不可行的,因为它要求更多的资源。为了减轻这个问题,作者开发了两种可能的方法:
-
我们发现尺度对检测的贡献最大,因此在扩大和缩小中都使用它;
-
我们找到最有助于检测的比例尺度,并使用尺寸稍大(最初未在金字塔中显示)且尺寸略小的比例尺,即我们进行尺寸增强。

图4
为了找到最有利的尺度,我们让图像经过P-Net并手动跟踪为R-Net提供最有意义结果的尺。如图4所示,图片大小为24x24。将人脸传递给R-Net的图像越多,人脸检测成功的可能性就越大。一旦以上述方式选择了三个比例,就能创建金字塔并计算输出的损失函数。
实验
要进行实验,我们需要为MTCNN定义主要的参数。设置金字塔图像最小尺寸的最小尺寸参数(minsize)为21个像素。每个子网络的阈值分别设置为0.6、0.7和0.7,缩放步长因子为0.709。这些参数均是在实践中广泛使用的。
对补丁进行了2000epoch的训练;更多迭代的训练并不能带来任何改善。为了测试生成的模式,我们录制了两种设置方法:带补丁的外科口罩和脸颊上只有两个补丁。视频用于计算各种步长比例因子的误检概率。为了使实验在实际意义上更具价值,人物在视频中的位置有所不同:近摄,中距离和远距离拍摄。结果在图5中给出。值得一提的是,所执行的攻击是具有针对性的,因此无法很好地迁移到训练样本中未包括的其他人。
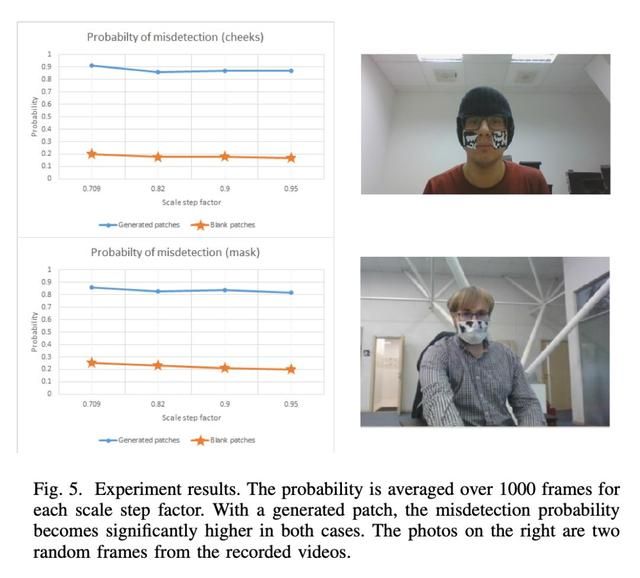
图5
总结
在本文中,作者:
-
找到了在数字域攻击MTCNN人脸检测器的方法;
-
通过EoT技术将该攻击转移到物理域;
-
通过在现实世界中进行实验来验证这些结果。
获得的实验结果表明,最强大的人脸检测网络仍然需要改进。物理域中的攻击带来了严重的安全性问题,因此应找到解决该问题的可能方法。在本文中,作者通过找到一种可重现的攻击方法,迈出了确保人脸检测系统安全的第一步。未来,作者将在MTCNN检测管道中考虑使用不同入侵位置的攻击,并考虑安全性方面的改进。