pytorch利用LeNet5和ResNet18训练Cifar10数据集
CIFAR10数据集
该数据集共有60000张彩色图像,这些图像是32*32,分为10个类,每类6000张图。这里面有50000张用于训练,构成了5个训练批,每一批10000张图;另外10000用于测试,单独构成一批。测试批的数据里,取自10类中的每一类,每一类随机取1000张。抽剩下的就随机排列组成了训练批。注意一个训练批中的各类图像并不一定数量相同,总的来看训练批,每一类都有5000张图。需要说明的是,这10类都是各自独立的,不会出现重叠。
LeNet5网络
LeNet5网络是一种用于手写体字符识别的非常高效的卷积神经网络。LeNet-5共有7层,不包含输入,每层都包含可训练参数;每个层有多个Feature Map,每个FeatureMap通过一种卷积滤波器提取输入的一种特征,然后每个FeatureMap有多个神经元。
lenet5.py,代码如下:
import torch
from torch import nn
class Lenet5(nn.Module):
"""
for cifar10 dataset.
"""
def __init__(self):
super(Lenet5, self).__init__()
self.conv_unit = nn.Sequential(
# x: [b, 3, 32, 32] => [b, 32, 5, 5]
nn.Conv2d(3, 16, kernel_size=5, stride=1, padding=0),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=0),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
)
# flatten
# fc unit
self.fc_unit = nn.Sequential(
nn.Linear(32 * 5 * 5, 32),
nn.ReLU(),
nn.Linear(32, 10)
)
# [b, 3, 32, 32]
tmp = torch.randn(2, 3, 32, 32)
out = self.conv_unit(tmp)
# [b, 32, 5, 5]
print('conv out:', out.shape)
def forward(self, x):
"""
param x: [b, 3, 32, 32]
return: logits: [b, 10]
"""
# batchsz = b
batchsz = x.size(0)
# [b, 3, 32, 32] => [b, 32, 5, 5]
x = self.conv_unit(x)
# [b, 32, 5, 5] => [b, 32 * 5 * 5]
x = x.view(batchsz, 32 * 5 * 5)
# [b, 32 * 5 * 5] => [b, 10]
logits = self.fc_unit(x)
return logits
def main():
net = Lenet5()
tmp = torch.randn(2, 3, 32, 32)
out = net(tmp)
print('lenet out:', out.shape)
# 查看模型结构
print(net)
if __name__ == '__main__':
main()
输出结果为:
conv out: torch.Size([2, 32, 5, 5])
lenet out: torch.Size([2, 10])
Lenet5(
(conv_unit): Sequential(
(0): Conv2d(3, 16, kernel_size=(5, 5), stride=(1, 1))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc_unit): Sequential(
(0): Linear(in_features=800, out_features=32, bias=True)
(1): ReLU()
(2): Linear(in_features=32, out_features=10, bias=True)
)
)
ResNet18网络
pytorch画出
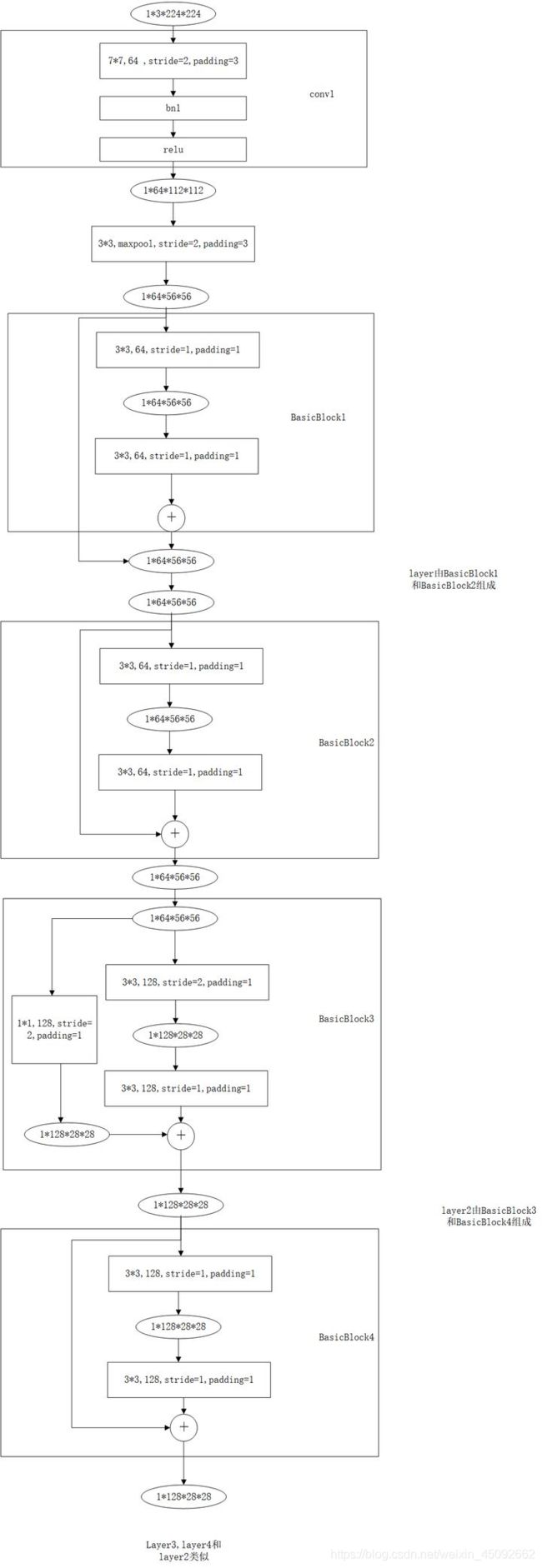
resnet.py代码如下:
import torch
from torch import nn
from torch.nn import functional as F
class ResBlk(nn.Module):
"""
resnet block
"""
def __init__(self, ch_in, ch_out, stride=1):
"""
:param ch_in:
:param ch_out:
"""
super(ResBlk, self).__init__()
# we add stride support for resbok, which is distinct from tutorials.
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
self.extra = nn.Sequential()
if ch_out != ch_in:
# [b, ch_in, h, w] => [b, ch_out, h, w]
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out)
)
def forward(self, x):
"""
:param x: [b, ch, h, w]
:return:
"""
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
# short cut.
# extra module: [b, ch_in, h, w] => [b, ch_out, h, w]
# element-wise add:
out = self.extra(x) + out
out = F.relu(out)
return out
class ResNet18(nn.Module):
def __init__(self):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(64)
)
# followed 4 blocks
# [b, 64, h, w] => [b, 128, h ,w]
self.blk1 = ResBlk(64, 128, stride=2)
# [b, 128, h, w] => [b, 256, h, w]
self.blk2 = ResBlk(128, 256, stride=2)
# # [b, 256, h, w] => [b, 512, h, w]
self.blk3 = ResBlk(256, 512, stride=2)
# # [b, 512, h, w] => [b, 1024, h, w]
self.blk4 = ResBlk(512, 512, stride=2)
self.outlayer = nn.Linear(512 * 1 * 1, 10)
def forward(self, x):
"""
:param x:
:return:
"""
x = F.relu(self.conv1(x))
# [b, 64, h, w] => [b, 1024, h, w]
x = self.blk1(x)
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
# print('after conv:', x.shape) #[b, 512, 2, 2]
# [b, 512, h, w] => [b, 512, 1, 1]
x = F.adaptive_avg_pool2d(x, [1, 1])
# print('after pool:', x.shape)
x = x.view(x.size(0), -1)
x = self.outlayer(x)
return x
def main():
blk = ResBlk(64, 128, stride=4)
tmp = torch.randn(2, 64, 32, 32)
out = blk(tmp)
print('block:', out.shape)
x = torch.randn(2, 3, 32, 32)
model = ResNet18()
out = model(x)
print('resnet:', out.shape)
# 查看模型结构
print(blk)
if __name__ == '__main__':
main()
结果:
block: torch.Size([2, 128, 8, 8])
resnet: torch.Size([2, 10])
ResBlk(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(4, 4), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(extra): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(4, 4))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
main.py代码:
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
from torch import nn, optim
from lenet5 import Lenet5
from resnet import ResNet18
def main():
batchsz = 256
cifar_train = datasets.CIFAR10('cifar', True, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
# DataLoader一次加载多张图片
cifar_train = DataLoader(cifar_train, batch_size=batchsz, shuffle=True)
cifar_test = datasets.CIFAR10('cifar', False, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_test = DataLoader(cifar_test, batch_size=batchsz, shuffle=True)
x, label = iter(cifar_train).next()
print('x:', x.shape, 'label:', label.shape)
device = torch.device('cuda')
model = Lenet5().to(device)
# model = ResNet18().to(device)
criteon = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
print(model)
for epoch in range(1000):
# 训练
model.train()
for batchidx, (x, label) in enumerate(cifar_train):
# [b, 3, 32, 32]
# [b]
x, label = x.to(device), label.to(device)
logits = model(x)
# logits: [b, 10]
# label: [b]
# loss: tensor scalar
loss = criteon(logits, label)
# backprop
optimizer.zero_grad() # 先把梯度清零
loss.backward()
optimizer.step()
print(epoch, 'loss:', loss.item())
# 测试
model.eval()
# 测试是不需要计算梯度的,所以放在不需要计算梯度里面,这样节约资源和时间
with torch.no_grad():
# test
total_correct = 0
total_num = 0
for x, label in cifar_test:
# x: [b, 3, 32, 32]
# label: [b]
x, label = x.to(device), label.to(device)
# [b, 10]
logits = model(x)
# [b]
pred = logits.argmax(dim=1)
# [b] vs [b] => scalar tensor
correct = torch.eq(pred, label).float().sum().item()
total_correct += correct
total_num += x.size(0)
# print(correct)
acc = total_correct / total_num
print(epoch, 'test acc:', acc)
if __name__ == '__main__':
main()
实验部分结果:
Files already downloaded and verified
Files already downloaded and verified
x: torch.Size([256, 3, 32, 32]) label: torch.Size([256])
conv out: torch.Size([2, 32, 5, 5])
Lenet5(
(conv_unit): Sequential(
(0): Conv2d(3, 16, kernel_size=(5, 5), stride=(1, 1))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc_unit): Sequential(
(0): Linear(in_features=800, out_features=32, bias=True)
(1): ReLU()
(2): Linear(in_features=32, out_features=10, bias=True)
)
)
0 loss: 1.4234744310379028
0 test acc: 0.5079
1 loss: 0.9590504765510559
1 test acc: 0.5635
2 loss: 1.1572571992874146
2 test acc: 0.578
3 loss: 1.0135480165481567
3 test acc: 0.6045
1、model.train()与model.eval()的用法
在训练开始之前写上model.trian(),在测试时写上model.eval()。
如果模型中有BN层(Batch Normalization)和Dropout,需要在训练时添加model.train(),在测试时添加model.eval()。其中model.train()是保证BN层用每一批数据的均值和方差,而model.eval()是保证BN用全部训练数据的均值和方差;而对于Dropout,model.train()是随机取一部分网络连接来训练更新参数,而model.eval()是利用到了所有网络连接。
2、Dropout
dropout常常用于抑制过拟合,在pytorch中,dropout中的参数p是节点丢失概率,比如torch.nn.Dropout(0.4),这里的0.4是指该层的神经元每次迭代训练时有40%的概率被丢失。而在tensorflow中,keras.layers.Dropout(0.4),这里0.4是被保留的概率,所以每次迭代训练时有60%的概率被丢失。
keras.layers.AlphaDropout(rate=0.4),主流使用AlphaDropout:1、均值和方差不变 2、归一化性质也不变。