【第98期】终于有人把Flink设计理念与基本架构讲明白了

![]()
导读:本文从设计理念的角度将Flink 与主流计算引擎 Hadoop MapReduce和Spark进行对比,并从宏观上介绍Flink的基本架构。
![]()
01
Flink与主流计算引擎对比
1. Hadoop MapReduce
MapReduce 是由谷歌首次在论文“MapReduce: Simplified Data Processing on Large Clusters”(谷歌大数据三驾马车之一)中提出的,是一种处理和生成大数据的编程模型。Hadoop MapReduce借鉴了谷歌这篇论文的思想,将大的任务分拆成较小的任务后进行处理,因此拥有更好的扩展性。如图1所示,Hadoop MapReduce 包括两个阶段—Map和Reduce:Map 阶段将数据映射为键值对(key/value),map 函数在Hadoop 中用Mapper类表示;Reduce阶段使用shuffle后的键值对数据,并使用自身提供的算法对其进行处理,得到输出结果,reduce函数在Hadoop中用Reducer类表示。其中shuffle阶段对MapReduce模式开发人员透明。
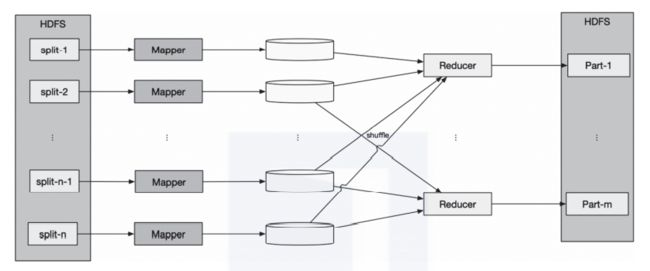
图1 Hadoop MapReduce处理模型
Hadoop MR1 通过JobTracker进程来管理作业的调度和资源,TaskTracker进程负责作业的实际执行,通过Slot来划分资源(CPU、内存等),Hadoop MR1存在资源利用率低的问题。Hadoop MR2 为了解决MR1存在的问题,对作业的调度与资源进行了升级改造,将JobTracker变成YARN,提升了资源的利用率。其中,YARN 的ResourceManager 负责资源的管理,ApplicationMaster负责任务的调度。YARN 支持可插拔,不但支持Hadoop MapReduce,还支持Spark、Flink、Storm等计算框架。Hadoop MR2 解决了Hadoop MR1的一些问题,但是其对HDFS的频繁I/O操作会导致系统无法达到低延迟的要求,因而它只适合离线大数据的处理,不能满足实时计算的要求。
2. Spark
Spark 是由加州大学伯克利分校开源的类Hadoop MapReduce的大数据处理框架。与 Hadoop MapReduce相比,它最大的不同是将计算中间的结果存储于内存中,而不需要存储到HDFS中。
Spark的基本数据模型为RDD(Resilient Distributed Dataset,弹性分布式数据集)。RDD是一个不可改变的分布式集合对象,由许多分区(partition)组成,每个分区包含RDD的一部分数据,且每个分区可以在不同的节点上存储和计算。在Spark 中,所有的计算都是通过RDD的创建和转换来完成的。
Spark Streaming 是在Spark Core的基础上扩展而来的,用于支持实时流式数据的处理。如图2所示,Spark Streaming 对流入的数据进行分批、转换和输出。微批处理无法满足低延迟的要求,只能算是近实时计算。

图2 Spark Streaming 处理模型
Structured Streaming 是基于Streaming SQL 引擎的可扩展和容错的流式计算引擎。如图3所示,Structured Streaming将流式的数据整体看成一张无界表,将每一条流入的数据看成无界的输入表,对输入进行处理会生成结果表。生成结果表可以通过触发器来触发,目前支持的触发器都是定时触发的,整个处理类似Spark Streaming的微批处理;从Spark 2.3开始引入持续处理。持续处理是一种新的、处于实验状态的流式处理模型,它在Structured Streaming的基础上支持持续触发来实现低延迟。
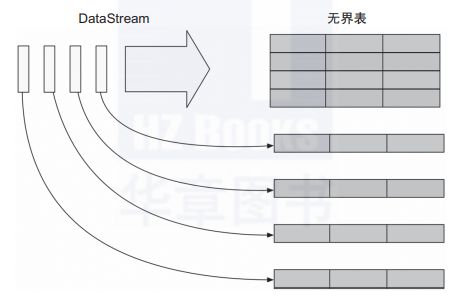
图3 Structured Streaming处理模型
3. Flink
Flink是对有界数据和无界数据进行有状态计算的分布式引擎,它是纯流式处理模式。流入Flink的数据会经过预定的DAG(Directed Acyclic Graph,有向无环图)节点,Flink会对这些数据进行有状态计算,整个计算过程类似于管道。每个计算节点会有本地存储,用来存储计算状态,而计算节点中的状态会在一定时间内持久化到分布式存储,来保证流的容错,如图4所示。这种纯流式模式保证了Flink的低延迟,使其在诸多的实时计算引擎竞争中具有优势。
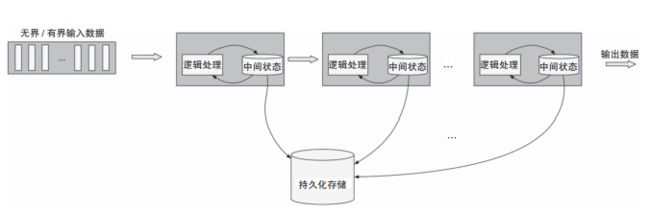
图4 Flink 流式处理模型
02
Flink基本架构
下面从分层角度和运行时角度来介绍Flink 基本架构。其中,对于运行时Flink 架构,会以1.5版本为分界线对前后版本的架构变更进行介绍。
1. 分层架构
Flink是分层架构的分布式计算引擎,每层的实现依赖下层提供的服务,同时提供抽象的接口和服务供上层使用。整体分层架构如图5所示。
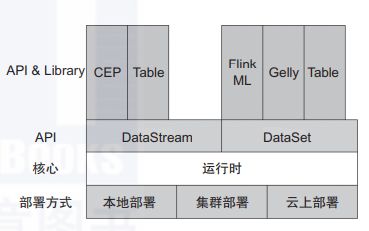
图5 Flink 分层架构
部署:Flink 支持本地运行,支持Standalone 集群以及YARN、Mesos、Kubernetes管理的集群,还支持在云上运行。
核心:Flink的运行时是整个引擎的核心,是分布式数据流的实现部分,实现了运行时组件之间的通信及组件的高可用等。
API:DataStream 提供流式计算的API,DataSet 提供批处理的API,Table 和SQL AP提供对Flink 流式计算和批处理的SQL的支持。
Library:在Library层,Flink 提供了复杂事件处理(CEP)、图计算(Gelly)及机器学习库。
2. 运行时架构
Flink 运行时架构经历过一次不小的演变。在Flink 1.5 版本之前,运行时架构如图6所示。
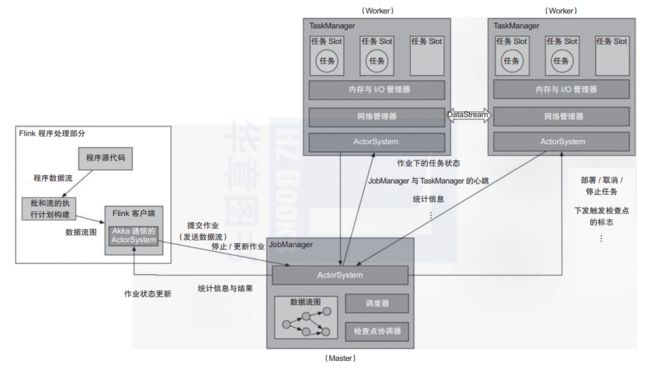
图6 Flink 1.5 以前版本的运行时架构
Client 负责编译提交的作业,生成DAG,并向JobManager提交作业,往JobManager发送操作作业的命令。
JobManager 作为Flink引擎的Master角色,主要有两个功能:作业调度和检查点协调。
TaskManager为Flink 引擎的Worker角色,是作业实际执行的地方。TaskManager通过Slot对其资源进行逻辑分割,以确定TaskManager运行的任务数量。
从Flink 1.5开始,Flink 运行时有两种模式,分别是Session 模式和Per-Job模式。
Session模式:在Flink 1.5之前都是Session模式,1.5及之后的版本与之前不同的是引入了Dispatcher。Dispatcher负责接收作业提交和持久化,生成多个JobManager和维护Session的一些状态,如图7所示。
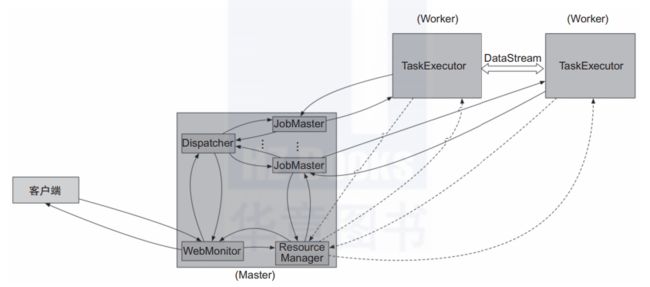
图7 Session模式
Per-Job模式:该模式启动后只会运行一个作业,且集群的生命周期与作业的生命周期息息相关, 而Session 模式可以有多个作业运行、多个作业共享TaskManager资源, 如图8所示。
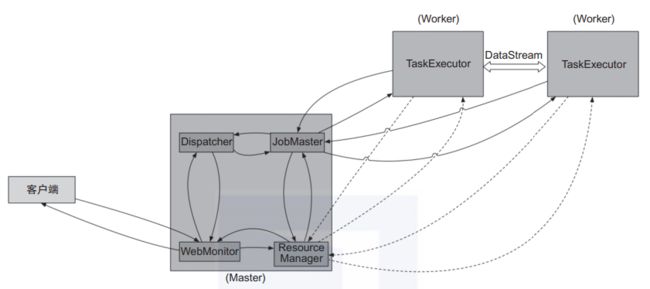
图8 Per-Job模式
关于作者:罗江宇,赵士杰,李涵淼,闵文俊,四位作者都是非常资深的Flink专家,部分作者是Flink源代码的维护者和改造者。

精彩罗江宇
Flink技术专家,先后就职于新浪微博、滴滴和某大型电商公司。先后主导或参与了多家公司的Flink实时计算服务的构建、对超大规模集群的维护以及Flink引擎的改造。拥有丰富的实时计算实战经验,目前专注于Kubernetes调度、Flink SQL及Flink流批一体化方向。
赵士杰
资深大数据技术专家,曾就职于滴滴、阿里巴巴等一线互联网公司。从0到1深度参与了滴滴的大数据建设,拥有非常丰富的大数据平台一线建设经验,对于大数据领域的计算和存储引擎也有深入研究。
李涵淼
大数据研发专家,曾任滴滴大数据开发工程师。从事大数据领域工作多年,参与过多家公司流计算平台的设计与研发,目前专注于流批一体、OLAP技术方向的研究与应用。
闵文俊
蚂蚁集团技术专家、开源大数据社区爱好者、Flink Contributor,在实时计算领域工作多年,深度参与了滴滴、蚂蚁集团的实时计算平台建设。 书评
RECOMMEND
推荐阅读
![]()
01
《Flink技术内幕》

推荐理由
这是一部从源代码角度出发,通过分析Flink的各个功能模块的实现来剖析Flink的架构设计和实现原理的著作。它将能指导读者更好地对Flink进行性能调优、可用性保障、效能优化和二次开发。
四位作者都是非常资深的Flink专家,部分作者是Flink源代码的维护者和改造者,本书总结了他们在阿里巴巴、蚂蚁集团、滴滴等企业的大规模Flink实践经验。
![]()
02
《Flink设计与实现》

推荐理由
这是一本从源代码角度剖析Flink设计思想、架构原理以及各功能模块的底层实现原理的著作。
作者是Flink领域的资深技术专家和架构师,对Flink的源代码进行了深入分析和解读,同时融入了自己丰富的工程实践经验,既能让理解Flink的设计与实现原理,又能为他们解决性能优化等实际应用问题提供源码级别的指导。源码大多艰涩难懂,为了降低读者的学习门槛,本书提供了大量架构设计图、UML图和代码注释。
![]()
03
《Flink原理、实战与性能优化》

推荐理由
这是一部以实战为导向,能指导读者零基础掌握Flink并快速完成进阶的著作,从功能、原理、实战和调优等4个维度循序渐进地讲解了如何利用Flink进行分布式流式应用开发。作者是该领域的资深专家,现就职于第四范式,曾就职于明略数据。
第97期赠书活动中奖名单公布

赠书规则
送书规则:感谢大家对华章图书的信任与支持。在留言区谈谈你想要哪本书及理由。小编会在留言池随机捞2条锦鲤,分别包邮送出1本正版书籍。本推文中的图书可任选一本。
截止日期:2022年4月8日下午16:00
特别注意:
1、请按规则结合自身工作与学习的经历留言。请规避百度式名词解释式言论,走心留言优先。
2、阅读最多、分享最多者优先。参与活跃者优先。同一人每月最多获赠一本书。
特别说明:本活动无任何内幕,最终解释权归华章分社所有。


扫码关注【华章计算机】视频号
每天来听华章哥讲书

更多精彩回顾
书讯 | 4月书讯(下)| 上新了,华章
书讯 | 4月书讯(上)| 上新了,华章
资讯 | AI 是否拥有意识?从意识的定义说起
书单 | 金三银四求职季,十道腾讯算法真题解析!
干货 | 场景拆解六步设计法,手把手教你细化场景
收藏 | 赵宏田:用户画像场景与技术实现
上新 | Web渗透测试实战:基于Metasploit 5.0
书评 | 数据分析即未来
