UNet入门总结
作者:AI浩 来源:投稿
编辑:学姐
Unet已经是非常老的分割模型了,是2015年《U-Net: Convolutional Networks for Biomedical Image Segmentation》提出的模型。
论文连接:https://arxiv.org/abs/1505.04597
在Unet之前,则是更老的FCN网络,FCN是Fully Convolutional Netowkrs的缩写,确立分割网络的基础框架 ,不过FCN网络的准确度较低,没有Unet好用。
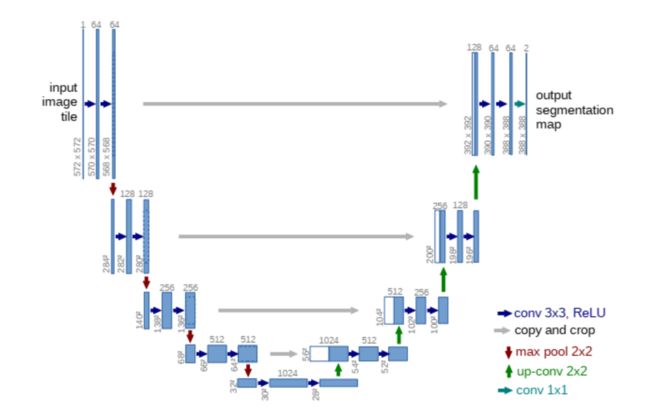
Unet网络非常的简单,前半部分就是特征提取,后半部分是上采样。在一些文献中把这种结构叫做编码器-解码器结构,由于网络的整体结构是一个大些的英文字母U,所以叫做U-net。
网络结构如下图:
-
Encoder:左半部分,由两个3x3的卷积层(RELU)再加上一个2x2的maxpooling层组成一个下采样的模块(后面代码可以看出);
-
Decoder:有半部分,由一个上采样的卷积层(去卷积层)+特征拼接concat+两个3x3的卷积层(ReLU)反复构成(代码中可以看出来);这种通过通道数的拼接,可以得到更多的特征,同时也会消耗更多的显存。
UNet的结构设计,使其能够结合底层特征和高层特征的信息。
底层(深层)特征:
经过多次下采样后的低分辨率信息。能够提供分割目标在整个图像中上下文语义信息,可理解为反应目标和它的环境之间关系的特征。这个特征有助于物体的类别判断(所以分类问题通常只需要低分辨率/深层信息,不涉及多尺度融合)
高层(浅层)特征:
经过concatenate操作从encoder直接传递到同高度decoder上的高分辨率信息。能够为分割提供更加精细的特征,如梯度等。
关于size对不上的原因:
从图上可以看到左侧和右侧的尺寸是对不上的,所以如果要对上,就要经历了裁切,所有灰色箭头的解释是copy and crop,不过复现的模型都没有采用这样的思路,都是将左侧和右侧的尺寸设置成一样的,而且每次卷积都加入了padding,这样经过卷积后尺寸不会改变。
不足之处:
-
该网络运行效率很慢。对于每个邻域,网络都要运行一次,且对于邻域重叠部分,网络会进行重复运算。
-
网络需要在精确的定位和获取上下文信息之间进行权衡。越大的patch需要越多的最大[池化层],其会降低定位的精确度,而小的邻域使得网络获取较少的上下文信息。
UNet 代码(pytorch)
import torch.nn as nn
import torch
from torch import autograd
#把常用的2个卷积操作简单封装下
class DoubleConv(nn.Module):
def __init__(self, in_ch, out_ch):
super(DoubleConv, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_ch, out_ch, 3, padding=1),
nn.BatchNorm2d(out_ch), #添加了BN层
nn.ReLU(inplace=True),
nn.Conv2d(out_ch, out_ch, 3, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True)
)
def forward(self, input):
return self.conv(input)
class Unet(nn.Module):
def __init__(self, in_ch, out_ch):
super(Unet, self).__init__()
self.conv1 = DoubleConv(in_ch, 64)
self.pool1 = nn.MaxPool2d(2)
self.conv2 = DoubleConv(64, 128)
self.pool2 = nn.MaxPool2d(2)
self.conv3 = DoubleConv(128, 256)
self.pool3 = nn.MaxPool2d(2)
self.conv4 = DoubleConv(256, 512)
self.pool4 = nn.MaxPool2d(2)
self.conv5 = DoubleConv(512, 1024)
# 逆卷积,也可以使用上采样(保证k=stride,stride即上采样倍数)
self.up6 = nn.ConvTranspose2d(1024, 512, 2, stride=2)
self.conv6 = DoubleConv(1024, 512)
self.up7 = nn.ConvTranspose2d(512, 256, 2, stride=2)
self.conv7 = DoubleConv(512, 256)
self.up8 = nn.ConvTranspose2d(256, 128, 2, stride=2)
self.conv8 = DoubleConv(256, 128)
self.up9 = nn.ConvTranspose2d(128, 64, 2, stride=2)
self.conv9 = DoubleConv(128, 64)
self.conv10 = nn.Conv2d(64, out_ch, 1)
def forward(self, x):
c1 = self.conv1(x)
p1 = self.pool1(c1)
c2 = self.conv2(p1)
p2 = self.pool2(c2)
c3 = self.conv3(p2)
p3 = self.pool3(c3)
c4 = self.conv4(p3)
p4 = self.pool4(c4)
c5 = self.conv5(p4)
up_6 = self.up6(c5)
merge6 = torch.cat([up_6, c4], dim=1)
c6 = self.conv6(merge6)
up_7 = self.up7(c6)
merge7 = torch.cat([up_7, c3], dim=1)
c7 = self.conv7(merge7)
up_8 = self.up8(c7)
merge8 = torch.cat([up_8, c2], dim=1)
c8 = self.conv8(merge8)
up_9 = self.up9(c8)
merge9 = torch.cat([up_9, c1], dim=1)
c9 = self.conv9(merge9)
c10 = self.conv10(c9)
out = nn.Sigmoid()(c10)
return out
Unet代码(Keras)
def unet(pretrained_weights=None, input_size=(256, 256, 3)):
inputs = Input(input_size)
conv1 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(inputs)
conv1 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv1)
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
conv2 = Conv2D(128, 3, activation='relu', padding='same', kernel_initializer='he_normal')(pool1)
conv2 = Conv2D(128, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv2)
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
conv3 = Conv2D(256, 3, activation='relu', padding='same', kernel_initializer='he_normal')(pool2)
conv3 = Conv2D(256, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv3)
pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
conv4 = Conv2D(512, 3, activation='relu', padding='same', kernel_initializer='he_normal')(pool3)
conv4 = Conv2D(512, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv4)
drop4 = Dropout(0.5)(conv4)
pool4 = MaxPooling2D(pool_size=(2, 2))(drop4)
conv5 = Conv2D(1024, 3, activation='relu', padding='same', kernel_initializer='he_normal')(pool4)
conv5 = Conv2D(1024, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv5)
drop5 = Dropout(0.5)(conv5)
up6 = Conv2D(512, 2, activation='relu', padding='same', kernel_initializer='he_normal')(
UpSampling2D(size=(2, 2))(drop5))
merge6 = concatenate([drop4, up6], axis=3)
conv6 = Conv2D(512, 3, activation='relu', padding='same', kernel_initializer='he_normal')(merge6)
conv6 = Conv2D(512, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv6)
up7 = Conv2D(256, 2, activation='relu', padding='same', kernel_initializer='he_normal')(
UpSampling2D(size=(2, 2))(conv6))
merge7 = concatenate([conv3, up7], axis=3)
conv7 = Conv2D(256, 3, activation='relu', padding='same', kernel_initializer='he_normal')(merge7)
conv7 = Conv2D(256, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv7)
up8 = Conv2D(128, 2, activation='relu', padding='same', kernel_initializer='he_normal')(
UpSampling2D(size=(2, 2))(conv7))
merge8 = concatenate([conv2, up8], axis=3)
conv8 = Conv2D(128, 3, activation='relu', padding='same', kernel_initializer='he_normal')(merge8)
conv8 = Conv2D(128, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv8)
up9 = Conv2D(64, 2, activation='relu', padding='same', kernel_initializer='he_normal')(
UpSampling2D(size=(2, 2))(conv8))
merge9 = concatenate([conv1, up9], axis=3)
conv9 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(merge9)
conv9 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv9)
conv9 = Conv2D(2, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv9)
conv10 = Conv2D(1, 1, activation='sigmoid')(conv9)
model = Model(inputs=inputs, outputs=conv10)
model.summary()
if (pretrained_weights):
model.load_weights(pretrained_weights)
return model
图像分割论文资料
关注下方《学姐带你玩AI》免费领取
码字不易,欢迎大家点赞评论收藏!