文本相似度分类方案研究
原文链接
文本相似度的三种模型结构
-
- (1) cross-encoder类:对一组句对进行编码,编码过程中可以进行句内及句间的信息交互。
- (2) bi-encoder类:分别对source文本和target文本进行编码,再通过网络结构进行表示间的交互和计算,得到最终分类结果
- (3) Cross Attention
- 引申
- trick内容
这里面的核心是大佬提出来的三种方案
(1) cross-encoder类:对一组句对进行编码,编码过程中可以进行句内及句间的信息交互。
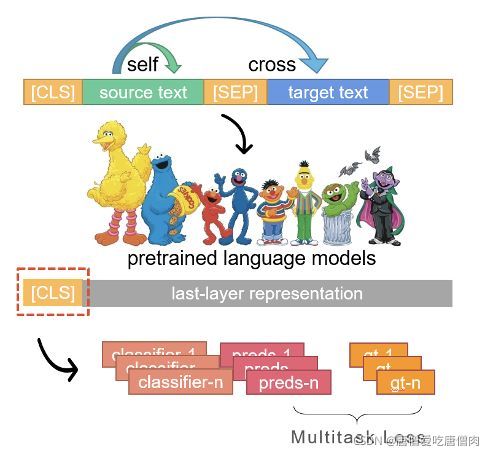 这种就是常规的[sep]+句子1+[sep]+句子2+[sep]
这种就是常规的[sep]+句子1+[sep]+句子2+[sep]
关键需要注意的是segment_id也需要相应的变换
对应的模型的代码如下:
class BertClassifierSingleModel(nn.Module):
def __init__(self, bert_dir, from_pretrained=True, task_num=2, hidden_size = 768, mid_size=512, freeze = False):
super(BertClassifierSingleModel, self).__init__()
self.hidden_size = hidden_size
# could extended to multiple tasks setting, e.g. 6 classifiers for 6 subtasks
self.task_num = task_num
if from_pretrained:
print("Initialize BERT from pretrained weights")
self.bert = BertModel.from_pretrained(bert_dir)
else:
print("Initialize BERT from config.json, weight NOT loaded")
self.bert_config = BertConfig.from_json_file(bert_dir+'config.json')
self.bert = BertModel(self.bert_config)
self.dropout = nn.Dropout(0.5)
self.all_classifier = nn.ModuleList([
nn.Sequential(
nn.Linear(hidden_size, mid_size),
nn.BatchNorm1d(mid_size),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(mid_size, 2)
)
for _ in range(self.task_num)
])
def forward(self, input_ids, input_types):
# get shared BERT model output
mask = torch.ne(input_ids, 0)
bert_output = self.bert(input_ids, token_type_ids=input_types, attention_mask=mask)
cls_embed = bert_output[1]
output = self.dropout(cls_embed)
# get probs for two tasks A and B
all_probs = [classifier(output) for classifier in self.all_classifier]
return all_probs
此外这里还有一种textcnn的结构变种
class BertClassifierTextCNNSingleModel(nn.Module):
def __init__(self, bert_dir, from_pretrained=True, task_num=2, hidden_size = 768, mid_size=512, freeze = False):
super(BertClassifierTextCNNSingleModel, self).__init__()
self.hidden_size = hidden_size
self.task_num = task_num
if from_pretrained:
print("Initialize BERT from pretrained weights")
self.bert = BertModel.from_pretrained(bert_dir)
else:
print("Initialize BERT from config.json, weight NOT loaded")
self.bert_config = BertConfig.from_json_file(bert_dir+'config.json')
self.bert = BertModel(self.bert_config)
self.dropout = nn.Dropout(0.5)
# for TextCNN
filter_num = 128
filter_sizes = [2,3,4]
self.convs = nn.ModuleList(
[nn.Conv2d(1, filter_num, (size, hidden_size)) for size in filter_sizes])
self.all_classifier = nn.ModuleList([
nn.Sequential(
nn.Linear(len(filter_sizes) * filter_num, mid_size),
nn.BatchNorm1d(mid_size),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(mid_size, 2)
)
for _ in range(self.task_num)
])
def forward(self, input_ids, input_types):
# get shared BERT model output
mask = torch.ne(input_ids, 0)
bert_output = self.bert(input_ids, token_type_ids=input_types, attention_mask=mask)
bert_hidden = bert_output[0]
output = self.dropout(bert_hidden)
tcnn_input = output.unsqueeze(1)
tcnn_output = [nn.functional.relu(conv(tcnn_input)).squeeze(3) for conv in self.convs]
# max pooling in TextCNN
# TODO: support avg pooling
tcnn_output = [nn.functional.max_pool1d(item, item.size(2)).squeeze(2) for item in tcnn_output]
tcnn_output = torch.cat(tcnn_output, 1)
tcnn_output = self.dropout(tcnn_output)
# get probs for two tasks A and B
all_probs = [classifier(tcnn_output) for classifier in self.all_classifier]
return all_probs
注意这里的Dropout率为0.5较大
(2) bi-encoder类:分别对source文本和target文本进行编码,再通过网络结构进行表示间的交互和计算,得到最终分类结果
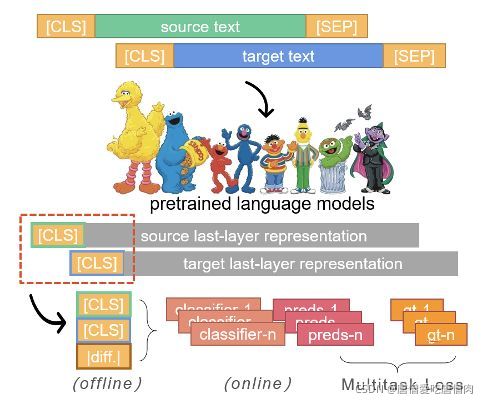
class SBERTSingleModel(nn.Module):
def __init__(self, bert_dir, from_pretrained=True, task_num=2, hidden_size=768, mid_size=512, freeze = False):
super(SBERTSingleModel, self).__init__()
self.hidden_size = hidden_size
self.task_num = task_num
if from_pretrained:
print("Initialize BERT from pretrained weights")
self.bert = BertModel.from_pretrained(bert_dir)
else:
print("Initialize BERT from config.json, weight NOT loaded")
self.bert_config = BertConfig.from_json_file(bert_dir+'config.json')
self.bert = BertModel(self.bert_config)
self.dropout = nn.Dropout(0.5)
self.all_classifier = nn.ModuleList([
nn.Sequential(
nn.Linear(hidden_size*3, mid_size),
nn.BatchNorm1d(mid_size),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(mid_size, 2)
)
for _ in range(self.task_num)
])
def forward(self, source_input_ids, target_input_ids):
# 0 for [PAD], mask out the padded values
source_attention_mask = torch.ne(source_input_ids, 0)
target_attention_mask = torch.ne(target_input_ids, 0)
# get bert output
source_embedding = self.bert(source_input_ids, attention_mask=source_attention_mask)
target_embedding = self.bert(target_input_ids, attention_mask=target_attention_mask)
# simply take out the [CLS] represention
# TODO: try different pooling strategies
source_embedding = source_embedding[1]
target_embedding = target_embedding[1]
# concat the source embedding, target embedding and abs embedding as in the original SBERT paper
abs_embedding = torch.abs(source_embedding-target_embedding)
context_embedding = torch.cat([source_embedding, target_embedding, abs_embedding], -1)
context_embedding = self.dropout(context_embedding)
# get probs for two tasks A and B
all_probs = [classifier(context_embedding) for classifier in self.all_classifier]
return all_probs
这里的注意abs_embedding为两者的绝对值之差,然后将三个向量拼接在一起,这里的绝对值之差能够更好地适应文本相似度内容
(3) Cross Attention
对bi-encoder类的改进,加入跨句子表示的注意力模块,显式促进文本之间的信息交互 与原方案相比得分略微增长(较SBERT提升2%~3%)
SBERT为上面连接的source_embedding,target_embedding以及abs_embedding的内容,及正上方的内容
SBERTCoAttentionModel也是使用了source_embedding,target_embedding以及abs_embedding的内容,区别在于这里是经过Attention网络层之后得到source_coattention_embedding以及target_coattention_embedding,然后再计算abs_embedding = torch.abs(source_coattention_embedding-target_coattention_embedding)
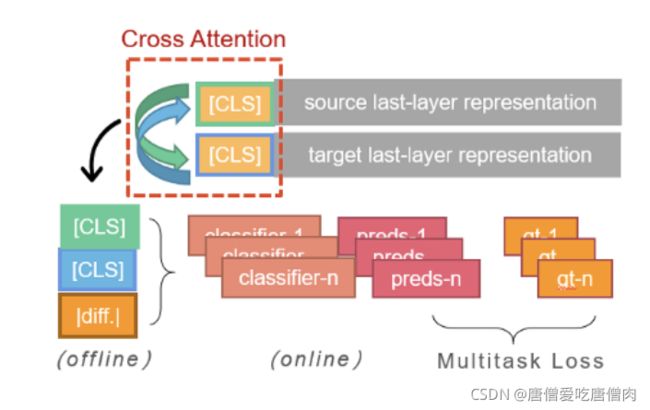 附上模型的结构内容
附上模型的结构内容
class BertCoAttention(nn.Module):
def __init__(self, config):
super(BertCoAttention, self).__init__()
if config.hidden_size % config.num_attention_heads != 0:
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (config.hidden_size, config.num_attention_heads))
self.output_attentions = config.output_attentions
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(self, context_states, query_states, attention_mask=None, head_mask=None, encoder_hidden_states=None,
encoder_attention_mask=None):
mixed_query_layer = self.query(query_states)
extended_attention_mask = attention_mask[:, None, None, :]
extended_attention_mask = extended_attention_mask.float() # fp16 compatibility
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
attention_mask = extended_attention_mask
# If this is instantiated as a cross-attention module, the keys
# and values come from an encoder; the attention mask needs to be
# such that the encoder's padding tokens are not attended to.
if encoder_hidden_states is not None:
mixed_key_layer = self.key(encoder_hidden_states)
mixed_value_layer = self.value(encoder_hidden_states)
attention_mask = encoder_attention_mask
else:
mixed_key_layer = self.key(context_states)
mixed_value_layer = self.value(context_states)
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.Softmax(dim=-1)(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
# outputs = (context_layer, attention_probs) if self.output_attentions else (context_layer,)
outputs = context_layer
return outputs
class SBERTCoAttentionModel(nn.Module):
def __init__(self, bert_dir, from_pretrained=True, task_num=2, hidden_size=768, mid_size=512, freeze = False):
super(SBERTCoAttentionModel, self).__init__()
self.hidden_size = hidden_size
self.task_num = task_num
if from_pretrained:
print("Initialize BERT from pretrained weights")
self.bert = BertModel.from_pretrained(bert_dir)
else:
print("Initialize BERT from config.json, weight NOT loaded")
self.bert_config = BertConfig.from_json_file(bert_dir+'config.json')
self.bert = BertModel(self.bert_config)
self.dropout = nn.Dropout(0.5)
self.co_attention = BertCoAttention(hidden_size=hidden_size)
self.all_classifier = nn.ModuleList([
nn.Sequential(
nn.Linear(hidden_size * 3, mid_size),
nn.BatchNorm1d(mid_size),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(mid_size, 2)
)
for _ in range(self.task_num)
])
def forward(self, source_input_ids, target_input_ids):
# 0 for [PAD], mask out the padded values
source_attention_mask = torch.ne(source_input_ids, 0)
target_attention_mask = torch.ne(target_input_ids, 0)
# get bert output
source_embedding = self.bert(source_input_ids, attention_mask=source_attention_mask)
target_embedding = self.bert(target_input_ids, attention_mask=target_attention_mask)
source_coattention_outputs = self.co_attention(target_embedding[0], source_embedding[0], source_attention_mask)
target_coattention_outputs = self.co_attention(source_embedding[0], target_embedding[0], target_attention_mask)
source_coattention_embedding = source_coattention_outputs[:, 0, :]
target_coattention_embedding = target_coattention_outputs[:, 0, :]
# simply take out the [CLS] represention获取[CLS]标志的内容
# TODO: try different pooling strategies
# source_embedding = source_embedding[1]
# target_embedding = target_embedding[1]
# concat the source embedding, target embedding and abs embedding as in the original SBERT paper
# we also add a coattention embedding as the forth embedding
abs_embedding = torch.abs(source_coattention_embedding - target_coattention_embedding)
context_embedding = torch.cat([source_coattention_embedding, target_coattention_embedding, abs_embedding], -1)
context_embedding = self.dropout(context_embedding)
# get probs for two tasks A and B
all_probs = [classifier(context_embedding) for classifier in self.all_classifier]
return all_probs
问题的关键在于将句子处理成为句向量之后,句向量1+句向量2+句向量的embedding内容相减(解决句子过长的关键:化为句向量),得到句向量可能平均池化更好,为了让句向量1和句向量2交互的更好,可以加入attention模型学习句向量1和句向量2的内容
引申
以后做分类任务的时候,也可以进行句子1的句向量和句子2的句向量进行训练的操作
trick内容
1.优化器与学习率:尝试Lookahead + Radam 加入权重衰减,线性规划学习率
2.数据增强:互换source文本与target文本的位置,A类负例是B类负例,B类正例是A类正例
3.Multi-Sample Dropout:对encoder的输出进行多次dropout,得到多组样本,以更好地训练classifier
4.Focal Loss:针对类别不平衡问题,降低负样本的权重(0.2%)
5.Task-adaptive Pretraining:在比赛提供的文本语料上继续MLM任务,使语言模型更贴近任务领域的语料分布 效果:新闻领域与预训练文本领域较为接近,提升有限(0.5%)
6.文本对抗训练(由于比赛数据较多,复赛时间和算力有限,未尝试FGM与PGD)(初赛提升0.5%)
7.伪标签:模型在测试集上标注得到伪标签,将伪标签与真实标签一起训练模型(噪声较大,降低模型鲁棒性,最终未采取)
8.标签平滑(提升效果不明显)