迁移学习——Stable Learning via Sample Reweighting
《Stable Learning via Sample Reweighting》学习
arXiv
文章目录
- 摘要
- 一、介绍
- 二、问题和方法
-
- 2.1用于回归的稳定线性模型
- 2.2用于分类的稳定线性模型
- 三、实验
-
- 3.1基线
- 3.2模拟研究
-
- 3.2.1实验性设置
- 3.2.2结果
- 3.3现实回归实验
-
- 3.3.1数据集和实验性设置
- 3.3.2结果
- 3.4现实分类实验
-
- 3.4.1数据集和实验性设置
- 3.4.2结果
- 总结与讨论
- Reference
摘要
研究了具有模型错误描述偏差的线性预测模型的学习问题。在这种情况下,输入变量之间的共线性可能会增大参数估计的误差,当训练分布和检验分布不匹配时,会导致预测结果不稳定。
本文从理论上分析了这一基本问题,并提出了一种减少输入变量间共线性的样本加权方法。
我们的方法可以看作是对数据的预处理,以改善设计矩阵的条件,然后它可以结合任何标准的学习方法进行参数估计和变量选择。
一、介绍
当测试数据的分布与训练数据的分布不一致时,大多数机器学习方法的性能就会下降。这是因为传统的学习方法依赖于一个基本的假设,即在训练时提取的数据与测试数据来自相同的底层分布。
然而,在许多实际情况下,这一假设可能会被违背,因为我们对未来将产生的测试数据没有事先的知识。因此,大量假设测试数据分布可用的学习方法(例如迁移学习(Pan, Yang))在这种情况下并不适用。
在本文中,我们考虑了直接解决这个基本问题的稳定学习问题。稳定学习的目标是学习一个在任意数据点 x x x上表现一致良好的预测模型。我们实际上需要两个假设:
- 在目标 y y y和预测器 x p x_p xp之间存在一个稳定的结构,该结构在整个分布中保持不变。
- 外部偏差带来的虚假关联在不同的环境中是不稳定的。
在实践中很常见的是,由于我们收集数据的时间跨度、区域和策略不同,通常会存在这样的虚假关联。
如果只利用稳定结构进行预测,即使未知检验分布与训练分布有显著差异,也能保证良好的预测性能。
稳定学习的主要挑战是在实际应用中,我们不能期望为底层应用问题选择一个完全正确的模型。
我们在本文中表明,如果在训练时使用了不正确的模型(这在实践中是不可避免的),变量之间的共线性(即两个或多个输入变量之间的线性依赖)的存在会使一个小的错误描述误差膨胀到任意大,从而导致不同分布测试数据的预测性能不稳定。
因此,如何减少共线性在稳定学习问题中是至关重要的
在线性模型中,由于变量的贡献是可互换的,因此评估变量的个体重要性带来了挑战。
处理共线性的主要方法是执行变量选择。基于互信息的方法如(Kononenko 1994;Raileanu和Stoffel, 2004;丁鹏2005;Peng, Long, and Ding 2005)可以看作是数据的预处理。他们基本上是通过最大化所选变量与响应之间的相关性,同时最小化所选变量之间的相关性,来为响应变量选择一个具有代表性和鉴别性的变量子集。
另一种方法是基于正则化技术,由于它们同时在参数估计和变量选择方面取得了良好的性能而受到关注。通过对变量结构的不同假设区分,(Zou and Hastie 2005;Lorbert等人2010;Grave, Obozinski,和Bach 2011)设计惩罚条款,通过约束相关变量要么全部选择,要么根本不选择为“集群”,和方法(Chen et al. 2013;高田,铃木,藤泽2018;Zhou, Jin, and Hoi 2010)只选择单个集群中的一个变量。
这些方法的性能高度依赖于对变量结构的正确假设。
当相关簇中存在非活动变量或多个活动变量时,这些方法要么丢失信息,要么包含非活动变量,导致分布变化导致行为不稳定。
我们首先从理论上分析了错误描述偏差带来的最坏估计误差,并论证了它与共线性的直接联系。
为了缓解变量间的共线性,我们提出了一种新的样本重加权方案。从理论上证明了在理想情况下,存在一组能使设计矩阵接近正交的样本权值。
因此,我们提出了一个样本重加权去相关算子(SRDO)来减少实际中的共线性。具体地说,我们构造一个不相关的设计矩阵 X ~ \mathbf{\tilde{X}} X~从原始 X \mathbf X X作为“oracle”,并通过估计底层的不相关分布 D ~ \mathbf{\tilde{D}} D~和原始分布 D \mathbf D D的密度比学习样本权重 w ( x ) w(x) w(x)。
该方法可以看作是一种通用的数据预处理方法,改善了底层设计矩阵的条件,以达到预测的目的。学习到的样本权重可以很容易地集成到标准的线性回归方法中,如普通最小二乘回归、Lasso和逻辑回归,以提高它们在不同分布测试数据上的稳定性。
本文的主要贡献如下:
- 研究了具有模型错误描述的线性模型在测试分布变化情况下的稳定学习问题。这个问题对于需要模型健壮性和稳定性的实际应用是至关重要的。
- 从理论上证明了预测稳定性与变量间共线性的直接联系,并提出了一种新的样本重加权去相关算子(SRDO)来降低设计矩阵的共线性。
- SRDO是一种通用的数据预处理方法,可以很容易地集成到各种经典的参数估计、变量选择和预测方法中,在合成数据集和真实数据集上的大量实验表明,它在变化分布下的预测稳定性和精度方面都具有优越的性能。
二、问题和方法
符号: 本文用 n n n表示样本容量, p p p表示观测变量的维数。对于任意矩阵 A ∈ R n × p A\in\mathbb R^{n×p} A∈Rn×p,设 A i , \mathbf A_{i,} Ai,和 A , j \mathbf A_{,j} A,j分别表示 A \mathbf A A的第i行和第j列。对于任意向量 v = ( v 1 , v 2 , ⋅ ⋅ ⋅ , v m ) ⊤ \mathbf v = (v_1, v_2,···,v_m)^\top v=(v1,v2,⋅⋅⋅,vm)⊤,设 ∥ v ∥ 1 = ∑ i = 1 m ∣ v i ∣ a n d ∥ v ∥ 2 2 = ∑ i = 1 m v i 2 \|\mathbf v\|_1=\sum^m_{i=1}|v_i|and\|\mathbf v\|^2_2=\sum^m_{i=1}v_i^2 ∥v∥1=∑i=1m∣vi∣and∥v∥22=∑i=1mvi2。
我们首先定义稳定学习问题如下
问题1。(稳定的学习)
给定目标 y y y和 p p p输入变量 x = [ x 1 , … , x p ] ∈ R p x = [x_1,…, x_p]\in\mathbb R^p x=[x1,…,xp]∈Rp,我们的任务是学习一个可以在任意数据点上实现一致小误差的预测模型。
本文在回归和分类线性模型的范围内研究了上述问题。
2.1用于回归的稳定线性模型
我们考虑了具有模型错误描述的线性回归问题。具体来说,我们可以假设目标 y y y的生成如下:
y = x ⊤ β ˉ 1 : p + β ˉ 0 + b ( x ) + ϵ (1) y=x^{\top} \bar{\beta}_{1: p}+\bar{\beta}_{0}+b(x)+\epsilon\tag{1} y=x⊤βˉ1:p+βˉ0+b(x)+ϵ(1)
其中 x ∈ R p x\in\mathbb R^p x∈Rp为输入向量, b ( x ) b(x) b(x)为依赖于 x x x的偏置项,使 ∣ b ( x ) ∣ ≤ δ |b(x)|\le\delta ∣b(x)∣≤δ,且 ϵ \epsilon ϵ是方差为 σ 2 \sigma^2 σ2的零均值噪声。
在稳定学习中,我们假设生成模型的线性部分是稳定的,对未知的分布漂移不变量,而错误描述偏差 b ( x ) b(x) b(x)可能是不稳定的。在这种意义上,我们希望尽可能准确地估计 β ˉ \bar{\beta} βˉ。
加上偏置项 b ( x ) b(x) b(x)对于所有 x x x都是一致小的性质,我们可以对所有 x x x做出可靠的预测。
特别是,分布的变化对于预测目的并不重要。
给定训练数据 { ( x 1 , y 1 ) , … , ( x n , y n ) } \{(x_1, y_1),…, (x_n, y_n)\} {(x1,y1),…,(xn,yn)},其中设计矩阵 X \mathbf X X来自分布 D D D,我们假设 ∥ x i ∥ 2 ≤ 1 \|x_i\|_2\le 1 ∥xi∥2≤1。最小二乘回归的标准方法解决了以下问题:
β ^ = arg min β ∑ i = 1 n ( x i ⊤ β 1 : p + β 0 − y i ) 2 (2) \hat{\beta}=\argmin_{\beta}\sum^n_{i=1}(x^{\top}_i \beta_{1: p}+\beta_{0}-y_i)^2\tag{2} β^=βargmini=1∑n(xi⊤β1:p+β0−yi)2(2)
设 γ 2 \gamma^2 γ2为中心协方差矩阵 n − 1 ∑ i ( x i − x ˉ ) ( x i − x ˉ ) ⊤ n^{-1}\sum_i(x_i-\bar x)(x_i-\bar x)^\top n−1∑i(xi−xˉ)(xi−xˉ)⊤的最小特征值,其中 x ˉ = n − 1 ∑ i x i \bar x=n^{-1}\sum_ix_i xˉ=n−1∑ixi。
本文所考虑的方法是由以下理论结果所驱动的,该结果表明,即使在样本容量无穷大的情况下,模型的错误描述偏差也会产生影响。
命题1。考虑样本容量为无穷大时的最小二乘解:
β ^ = arg min β E ( x , y ) ( x ⊤ β 1 : p + β 0 − y ) 2 (3) \hat{\beta}=\argmin_{\beta}\mathbf E_{(x,y)}(x^{\top} \beta_{1: p}+\beta_{0}-y)^2\tag{3} β^=βargminE(x,y)(x⊤β1:p+β0−y)2(3)
由最坏情况扰动误差 ∣ b ( x ) ∣ ≤ δ |b(x)|\le\delta ∣b(x)∣≤δ引起的估计偏差可以与 ∥ β ^ − β ˉ ∥ 2 ≤ 2 ( δ / γ ) + δ \|\hat{\beta}-\bar{\beta}\|_2\le2(\delta/\gamma)+\delta ∥β^−βˉ∥2≤2(δ/γ)+δ一样严重,其中 γ 2 \gamma^2 γ2是 E ( x − E x ) ( x − E x ) ⊤ \mathbf E(x−\mathbf Ex)(x−\mathbf Ex)^\top E(x−Ex)(x−Ex)⊤的最小特征值。
证明。让 △ β = β − β ˉ , △ β ^ = β ^ − β ˉ \triangle\beta = \beta −\bar\beta,\triangle\hat{\beta} =\hat{\beta}−\bar{\beta} △β=β−βˉ,△β^=β^−βˉ。我们有
△ β ^ = arg min △ β E x ( x ⊤ △ β 1 : p + △ β 0 − b ( x ) ) 2 (4) \triangle\hat{\beta}=\argmin_{\triangle\beta}\mathbf E_{x}(x^{\top} \triangle\beta_{1: p}+\triangle\beta_{0}-b(x))^2\tag{4} △β^=△βargminEx(x⊤△β1:p+△β0−b(x))2(4)
最优解为: △ β ^ 0 = E x b ( x ) − E x x ⊤ △ β ^ 1 : p \triangle\hat{\beta}_0=\mathbf E_{x}b(x)-\mathbf E_{x}x^\top\triangle\hat{\beta}_{1: p} △β^0=Exb(x)−Exx⊤△β^1:p。通过消除 β 0 \beta_0 β0,和让 x ~ = x − E x \tilde x=x-\mathbf Ex x~=x−Ex,和 b ~ ( x ) = b ( x ) − E x b ( x ) \tilde b(x)=b(x)-\mathbf E_xb(x) b~(x)=b(x)−Exb(x),我们有
△ β ^ 1 : p = arg min △ β 1 : p ( x ~ ⊤ △ β 1 : p − b ~ ( x ) ) 2 (5) \triangle\hat{\beta}_{1: p}=\argmin_{\triangle\beta_{1: p}}(\tilde x^\top\triangle\beta_{1: p}-\tilde b(x))^2\tag{5} △β^1:p=△β1:pargmin(x~⊤△β1:p−b~(x))2(5)
由此可见,
△ β ^ 1 : p = ( E x ~ x ~ ⊤ ) − 1 E b ~ ( x ) x ~ (6) \triangle\hat{\beta}_{1: p}=(\mathbf E\tilde x\tilde x^\top)^{-1}\mathbf E\tilde b(x)\tilde x\tag{6} △β^1:p=(Ex~x~⊤)−1Eb~(x)x~(6)
即 ∥ △ β ^ 1 : p ∥ 2 ≤ δ / γ \|\triangle\hat{\beta}_{1: p}\|_2\le\delta/\gamma ∥△β^1:p∥2≤δ/γ。 ∣ △ β ^ 0 ∣ ≤ δ + δ / γ |\triangle\hat{\beta}_{0}|\le\delta+\delta/\gamma ∣△β^0∣≤δ+δ/γ。这样我们就得到了期望的界。
由命题1可知,当 γ \gamma γ趋于零时,最坏情况下的估计误差趋于无穷大。这意味着当变量高度共线时,即使训练数据量非常大(或无穷大),普通的最小二乘法也会产生较差的解。
因此稳定学习的问题是找到稳定的 β ^ \hat{\beta} β^,以便在无限样本的情况下,对于最坏的 ∣ b ( x ) ∣ ≤ δ |b(x)|\le\delta ∣b(x)∣≤δ,估计误差是 ∥ β ^ − β ˉ ∥ 2 = O ( δ ) \|\hat{\beta}-\bar{\beta}\|_2=O(\delta) ∥β^−βˉ∥2=O(δ)和独立于 γ \gamma γ。
这意味着我们容忍由共线性引起的偏差。
为了解决共线性问题,我们提出了一个无限样本情况下的样本权重调整方案如下:
β ^ = arg min β E ( x ) ∼ D w ( x ) ( x ⊤ β 1 : p + β 0 − y ) 2 , (7) \hat{\beta}=\arg \min _{\beta} \mathbf{E}_{(x) \sim D} w(x)\left(x^{\top} \beta_{1: p}+\beta_{0}-y\right)^{2},\tag{7} β^=argβminE(x)∼Dw(x)(x⊤β1:p+β0−y)2,(7)
其中 w ( x ) w(x) w(x)为待学习的样本权值。
这就等于
β ^ = arg min β E ( x ) ∼ D ~ ( x ⊤ β 1 : p + β 0 − y ) 2 , (8) \hat{\beta}=\arg \min _{\beta} \mathbf{E}_{(x) \sim\tilde D} \left(x^{\top} \beta_{1: p}+\beta_{0}-y\right)^{2},\tag{8} β^=argβminE(x)∼D~(x⊤β1:p+β0−y)2,(8)
其中
p D ~ ( x ) p D ( x ) = w ( x ) (9) \frac{p_{\tilde D}(x)}{p_{D}(x)}=w(x)\tag{9} pD(x)pD~(x)=w(x)(9)
对于 D ~ \tilde D D~是一个有效的分布,我们有 E ( x ) ∼ D [ w ( x ) ] = 1 \mathbf{E}_{(x) \sim D} [w(x)]=1 E(x)∼D[w(x)]=1。
样品重新加权的目标是改善 γ ~ \tilde{\gamma} γ~,其中 γ ~ 2 \tilde{\gamma}^2 γ~2的最小特征值
E ( x ) ∼ D ~ ( x − E x ∼ D ~ x ) ( x − E x ∼ D ~ x ) ⊤ \mathbf{E}_{(x) \sim\tilde D}(x-\mathbf{E}_{x\sim\tilde D}x)(x-\mathbf{E}_{x\sim\tilde D}x)^\top E(x)∼D~(x−Ex∼D~x)(x−Ex∼D~x)⊤
其中 x x x从 D ~ \tilde D D~中提取。
然而,如果 E ( x ) ∼ D w ( x ) 2 \mathbf{E}_{(x) \sim D} w(x)^2 E(x)∼Dw(x)2较大,则随机噪声导致的有限样本误差将受到惩罚 ϵ \epsilon ϵ。事实上,在加权最小二乘模型中,当 n → ∞ n\rightarrow\infin n→∞, 根据Slutsky定理,我们有
n ( β ^ − β ˉ ) ⟶ d N ( 0 , Q ) (10) \sqrt{n}(\hat{\beta}-\bar{\beta})\overset{d}{\longrightarrow}N(\mathbf 0,\mathbf Q)\tag{10} n(β^−βˉ)⟶dN(0,Q)(10)
其中
Q = E [ w ( x i ) x i x i ⊤ ] − 1 E [ w ( x i ) 2 x i x i ⊤ ϵ i 2 ] E [ w ( x i ) x i x i ⊤ ] − 1 \mathbf{Q}=E\left[w\left(x_{i}\right) \mathbf{x}_{i} \mathbf{x}_{i}^{\top}\right]^{-1} E\left[w\left(x_{i}\right)^{2} \mathbf{x}_{i} \mathbf{x}_{i}^{\top} \epsilon_{i}^{2}\right] E\left[w\left(x_{i}\right) \mathbf{x}_{i} \mathbf{x}_{i}^{\top}\right]^{-1} Q=E[w(xi)xixi⊤]−1E[w(xi)2xixi⊤ϵi2]E[w(xi)xixi⊤]−1
那么类似于命题1中的分析,随机噪声 ϵ \epsilon ϵ引起的有限样本估计误差是有界的
O ( n − 1 / 2 E ( x ) ∼ D w ( x ) 2 σ / γ ~ ) (11) O\left(n^{-1/2}\sqrt{\mathbf{E}_{(x) \sim D} w(x)^2}\sigma/\tilde{\gamma}\right)\tag{11} O(n−1/2E(x)∼Dw(x)2σ/γ~)(11)
将此结果与命题1结合,有限样本情况下的总估计误差 ∥ β ^ − β ˉ ∥ 2 \|\hat{\beta}-\bar{\beta}\|_2 ∥β^−βˉ∥2(由偏置 b ( x ) b(x) b(x)和随机噪声 ϵ \epsilon ϵ引起)为:
O ( δ / γ ~ ) + O ( n − 1 / 2 E ( x ) ∼ D w ( x ) 2 σ / γ ~ ) (12) O(\delta/\tilde{\gamma})+O\left(n^{-1/2}\sqrt{\mathbf{E}_{(x) \sim D} w(x)^2}\sigma/\tilde{\gamma}\right)\tag{12} O(δ/γ~)+O(n−1/2E(x)∼Dw(x)2σ/γ~)(12)
当n很大时。右边第一项是偏差,与训练样本大小n无关,第二项是方差的平方根,方差依赖于n。重加权可以减少偏差项,但总体上增加了方差项。因此,在小样本情况下,当n不太大时,有一个权衡。
如果我们可以使 γ ~ \tilde{\gamma} γ~接近1,那么由 b ( x ) b(x) b(x)带来的估计偏差将变成 O ( δ / γ ~ ) = O ( 1 ) O(\delta/\tilde{\gamma})= O(1) O(δ/γ~)=O(1),因为我们可以假设错规格误差 δ \delta δ是一个可测量的和有界的“系统”误差,可以被视为一个特定系统的常数值。因此总偏差为
∥ β ^ − β ˉ ∥ 2 = O ( 1 ) + O ( n − 1 / 2 E ( x ) ∼ D w ( x ) 2 σ ) (13) \|\hat{\beta}-\bar{\beta}\|_2=O(1)+O\left(n^{-1/2}\sqrt{\mathbf{E}_{(x) \sim D} w(x)^2}\sigma\right)\tag{13} ∥β^−βˉ∥2=O(1)+O(n−1/2E(x)∼Dw(x)2σ)(13)
它与共线性无关,并达到我们讨论过的稳定预测。
以下命题表明,在理想化的情况下,当样本容量为 n → ∞ n\rightarrow\infin n→∞时,有可能找到权重 w w w,使设计矩阵接近正交(经过定心)。
命题2
设 p u ( x ) p_u(x) pu(x)是 X = X 1 × ⋅ ⋅ ⋅ × X p ⊂ R p \mathcal X = \mathcal X_1 ×···× \mathcal X_p\subset R^p X=X1×⋅⋅⋅×Xp⊂Rp上的均匀分布,并假定 E ( x ) ∼ p u ( x ) ∥ x ∥ 2 2 < ∞ \mathbf{E}_{(x) \sim p_u(x)}\|x\|^2_2<\infin E(x)∼pu(x)∥x∥22<∞。
假设每个变量 x j ∈ X j x_j\in\mathcal X_j xj∈Xj,向量 x = [ x j ] x= [x_j] x=[xj]在 X \mathcal X X上的密度 p ( x ) p(x) p(x)使 0 < 2 γ 0 ≤ p u ( x ) / p ( x ) ≤ γ 1 / 2 0<2\gamma_0\le p_u(x)/p(x)\le\gamma_1/2 0<2γ0≤pu(x)/p(x)≤γ1/2。对所有 ξ > 0 \xi > 0 ξ>0,和 ζ > 0 \zeta > 0 ζ>0,存在 N N N使所有 n > N n > N n>N,且概率大于 1 − ζ 1 - \zeta 1−ζ,存在 w w w使 ∥ w ∥ 1 = 1 \|w\|_1 = 1 ∥w∥1=1, γ 0 / n ≤ ∥ w ∥ ∞ ≤ γ 1 / n \gamma_0/ n\le\|w\|_{\infin}\le\gamma_1/ n γ0/n≤∥w∥∞≤γ1/n,和
∣ n − 1 ∑ i w i ( x i , j − c j ) ( x i , k − c k ) ∣ ≤ ξ (14) |n^{-1}\sum_iw_i(x_{i,j}-c_j)(x_{i,k}-c_k)|\le\xi\tag{14} ∣n−1i∑wi(xi,j−cj)(xi,k−ck)∣≤ξ(14)
式中 c j = n − 1 ∑ i c i , j c_j = n^{−1}\sum_i c_{i,j} cj=n−1∑ici,j为各变量 j j j的均值, j ≠ k j\ne k j=k。
证明。设 w ( x ) = p u ( x ) / p ( x ) w(x) = p_u(x)/p(x) w(x)=pu(x)/p(x)。对于每一对 1 ≤ j ≠ k ≤ p 1\le j\ne k \le p 1≤j=k≤p,我们知道对于 x = [ x 1 , … , x p ] ∈ X x = [x^1,…, x^p]\in\mathcal X x=[x1,…,xp]∈X,
E ( x ) ∼ p ( x ) w ( x ) ( x k − E x k ) ( x j k − E x j ) = 0 (15) \mathbf{E}_{(x) \sim p(x)}w(x)(x^k-\mathbf Ex^k)(x^jk-\mathbf Ex^j)=0\tag{15} E(x)∼p(x)w(x)(xk−Exk)(xjk−Exj)=0(15)
我们也知道
E ( x ) ∼ p ( x ) w ( x ) = 1 \mathbf{E}_{(x) \sim p(x)}w(x)=1 E(x)∼p(x)w(x)=1
因此,根据大数定律,存在概率大于 1 − ζ / p 2 1 - \zeta /p^2 1−ζ/p2的 N N N,当我们绘制 x i = [ x i , 1 , … , x i , p ] x_i = [x_{i,1},…, x_{i,p}] xi=[xi,1,…,xi,p]从 p ( x ) p(x) p(x)其中 i = 1 , … n i = 1,…n i=1,…n,我们可以让 w i = w ( x i ) / ∑ j w ( x j ) w_i = w(x_i)/ \sum_j w(x_j) wi=w(xi)/∑jw(xj)然后
∣ 1 n ∑ i = 1 n w i ( x i , j − c j ) ( x i , k − c k ) ∣ ≤ ξ (16) \left|\frac{1}{n}\sum^n_{i=1}w_i(x_{i,j}-c_j)(x_{i,k}-c_k)\right|\le\xi \tag{16} ∣ ∣n1i=1∑nwi(xi,j−cj)(xi,k−ck)∣ ∣≤ξ(16)
并且
1 n ∑ j w ( x j ) ∈ [ 0.5 , 2 ] \frac{1}{n}\sum_jw(x_j)\in[0.5,2] n1j∑w(xj)∈[0.5,2]
取 ( i , j ) (i, j) (i,j)对上的联合界,我们得到了想要的结果。
假设我们将所有变量标准化,那么样本协方差矩阵就变成了相关矩阵 R R R,命题2表明样本协方差矩阵的非对角元素可以通过 ξ \xi ξ与样本权 w ( x ) w(x) w(x)使矩阵有任意小的界。
设 M = R − I p M = R−I_p M=R−Ip,通过格什戈林圆定理,可以得到 γ 2 ≥ 1 − ∥ M ∥ ∞ = 1 − ( p − 1 ) ξ \gamma^2\ge 1−\|M\|_{\infin}= 1−(p−1)\xi γ2≥1−∥M∥∞=1−(p−1)ξ。因此,通过减少变量之间的两两相关性(也就是, R R R的非对角线元素),我们可以将最小特征值调整为接近1。
受命题2的启发,我们提出了一个样本重加权去相关算子(SRDO)来降低设计矩阵的共线性。首先,我们使用设计矩阵 X \mathbf X X来生成一个列- 不相关的一个 X ~ \tilde{\mathbf X} X~,通过执行随机重采样列-明智,这将变量在 X \mathbf X X中的联合分布分解为 p p p个独立的边缘分布在 X ~ \tilde{\mathbf X} X~。
然后,我们可以通过密度比估计(Sugiyama, Suzuki,和Kanamori 2012)来学习样本权重来转移原始的 X ∼ D \mathbf X \sim D X∼D到 X ~ ∼ D ~ \tilde{\mathbf X} \sim \tilde{D} X~∼D~。
具体地说,我们设置 X ~ \tilde{\mathbf X} X~为正样本 ( Z = 1 ) (Z = 1) (Z=1),而 X \mathbf X X为负样本 ( Z = 0 ) (Z = 0) (Z=0),并适合一个概率分类器。
由贝叶斯定理可知,密度比为:
w ( x ) = p D ~ ( x ) p D ( x ) = p ( x ∣ D ~ ) p ( x ∣ D ) = p ( D ~ ) p ( D ) p ( Z = 1 ∣ x ) p ( Z = 0 ∣ x ) . (17) w(x)=\frac{p_{\tilde{D}}(\boldsymbol{x})}{p_{D}(\boldsymbol{x})}=\frac{p(\boldsymbol{x} \mid \tilde{D})}{p(\boldsymbol{x} \mid D)}=\frac{p(\tilde{D})}{p(D)} \frac{p(Z=1 \mid x)}{p(Z=0 \mid x)} .\tag{17} w(x)=pD(x)pD~(x)=p(x∣D)p(x∣D~)=p(D)p(D~)p(Z=0∣x)p(Z=1∣x).(17)
注意,前面的 p ( D ~ ) p ( D ) \frac{p(\tilde{D})}{p(D)} p(D)p(D~)在所有的样本中是常数,所以我们可以忽略它。为了得到 w ( x ) w(x) w(x)的单位均值,我们可以进一步用 w ( x ) w(x) w(x)除以它的均值 1 n ∑ i = 1 n w ( x i ) \frac{1}{n}\sum^n_{i=1}w(x_i) n1∑i=1nw(xi)。样本重加权去相关算子(SRDO)的算法可以总结如下:

2.2用于分类的稳定线性模型
除了回归,样本重加权的思想也可以应用于分类问题。为了简单起见,我们使用逻辑回归来考虑二元分类。
在二元分类中,我们有 β ⊤ x ∈ R , y ∈ { ± 1 } \beta^\top x∈R, y\in\{\pm1\} β⊤x∈R,y∈{±1}。
整体损失函数为
∑ i = 1 n ln ( 1 + exp ( − β ⊤ x i y i ) ) (18) \sum^n_{i=1}\operatorname{ln}(1+\operatorname{exp}(-\beta^\top x_iy_i))\tag{18} i=1∑nln(1+exp(−β⊤xiyi))(18)
给出一个近似的解决方案 β ~ \tilde{\beta} β~和 p i ~ = p ~ ( x i ) = 1 / ( 1 + exp ( − β ~ ⊤ x i ) ) \tilde{p_i}=\tilde{p}(x_i)=1/\left(1+\operatorname{exp}\left(-\tilde{\beta}^\top x_i\right)\right) pi~=p~(xi)=1/(1+exp(−β~⊤xi)),我们可以在该解处使用泰勒展开,将损失函数近似为加权最小二乘如下:
∑ i = 1 n p i ~ ( 1 − p i ~ ) ( β ⊤ x i − z i ) 2 (19) \sum^n_{i=1}\tilde{p_i}(1-\tilde{p_i})(\beta^\top x_i-z_i)^2\tag{19} i=1∑npi~(1−pi~)(β⊤xi−zi)2(19)
z i z_i zi是由定义的有效响应
z i ≡ g ( β ⊤ x i ) + ( y − β ⊤ x i ) g ′ ( β ⊤ x i ) (20) z_i\equiv g(\beta^\top x_i)+(y-\beta^\top x_i)g'(\beta^\top x_i)\tag{20} zi≡g(β⊤xi)+(y−β⊤xi)g′(β⊤xi)(20)
和 g ( x ) ≡ log x 1 − x g(x)\equiv\operatorname{log}\frac{x}{1-x} g(x)≡log1−xx
我们不想让 X \mathbf X X的协方差矩阵像单位一样接近,而是希望加权协方差矩阵是去相关的。因此,我们仍然可以使用上述方法来估计 w ( x ) w(x) w(x),只需稍加修改,如下:
p ~ ( x ) ( 1 − p ~ ( x ) ) w ( x ) = p ( Z = 1 ∣ x ) p ( Z = 0 ∣ x ) (21) \tilde{p}(x)(1-\tilde{p}(x))w(x)=\frac{p(Z=1 \mid x)}{p(Z=0 \mid x)}\tag{21} p~(x)(1−p~(x))w(x)=p(Z=0∣x)p(Z=1∣x)(21)
在实际应用中,我们可以忽略那些可以通过高置信度近似解精确预测的样本,以减小样本权值 w ( x ) w(x) w(x)的方差。然后我们可以解出加权逻辑回归如下:
∑ i = 1 n w ( x i ) ln ( 1 + exp ( − β ⊤ x i y i ) ) (22) \sum^n_{i=1}w(x_i)\operatorname{ln}(1+\operatorname{exp}(-\beta^\top x_iy_i))\tag{22} i=1∑nw(xi)ln(1+exp(−β⊤xiyi))(22)
三、实验
在本节中,我们通过模拟研究和两个真实世界的数据集进行回归和分类,来评估我们算法的有效性
3.1基线
对于回归任务,我们将我们的方法与OLS、Lasso (Tibshirani 1996)、Elastic Net (Zou和Hastie 2005)、ULasso (Chen et al. 2013)和IILasso (Takada、Suzuki和Fujisawa 2018)进行比较。前三个基线都是一般意义上的经典方法,而ULasso和IILasso是专门为解决共线性而设计的,可以作为Lasso的延伸:
- 不相关的套索(ULasso)
min ∥ Y − X β ∥ 2 2 + λ 1 ∥ β ∥ 1 + λ 2 β T C β \min \|Y-\mathbf{X} \beta\|_{2}^{2}+\lambda_{1}\|\beta\|_{1}+\lambda_{2} \beta^{T} \mathbf{C} \beta min∥Y−Xβ∥22+λ1∥β∥1+λ2βTCβ
其中 C ∈ R p × p \mathbf{C}\in\mathbb R^{p\times p} C∈Rp×p的每一个元素 C j k = r j k 2 C_{jk}=r^2_{jk} Cjk=rjk2和 r j k = 1 n ∣ X , j T X , k ∣ r_{jk}=\frac{1}{n}|\mathbf X^T_{,j}\mathbf X_{,k}| rjk=n1∣X,jTX,k∣ - 独立解释套索(IILasso)
min ∥ Y − X β ∥ 2 2 + λ 1 ∥ β ∥ 1 + λ 2 ∣ β ∣ T R ∣ β ∣ \min \|Y-\mathbf{X} \beta\|_{2}^{2}+\lambda_{1}\|\beta\|_{1}+\lambda_{2} |\beta|^{T} \mathbf{R} |\beta| min∥Y−Xβ∥22+λ1∥β∥1+λ2∣β∣TR∣β∣
其中 R ∈ R p × p \mathbf{R}\in\mathbb R^{p\times p} R∈Rp×p的每一个元素 R j k = ∣ r j k ∣ / ( 1 − ∣ r j k ∣ ) R_{jk}=|r_{jk}|/(1-|r_{jk}|) Rjk=∣rjk∣/(1−∣rjk∣)和 r j k = 1 n ∣ X , j T X , k ∣ r_{jk}=\frac{1}{n}|\mathbf X^T_{,j}\mathbf X_{,k}| rjk=n1∣X,jTX,k∣
对于分类任务,我们在基线中用对数似然损失代替平方损失。上述方法具有多个超参数,通过交叉验证对所有参数进行调优。我们将SRDO应用于回归任务中的普通最小二乘,以及分类任务中的逻辑回归,得到我们的结果。
在我们的实验中,我们考虑了 n > p n > p n>p的情况。而对于相反的情况,人们可能想要使用像Ledoit-Wolf (Ledoit和Wolf 2004)这样的收缩估计器。
3.2模拟研究
3.2.1实验性设置
在模拟研究中,我们通过指定协方差矩阵 Σ \Sigma Σ的结构,由多元正态分布 X ∼ N ( 0 , Σ ) X \sim N(0, \Sigma) X∼N(0,Σ)生成设计矩阵 X \mathbf X X。我们可以模拟 X \mathbf X X的不同关联结构。
具体地说,我们让 Σ = Diag ( Σ ( 1 ) , ⋯ , Σ ( q ) ) \Sigma=\operatorname{Diag}(\Sigma^{(1)},\cdots,\Sigma^{(q)}) Σ=Diag(Σ(1),⋯,Σ(q))是一个分块对角矩阵,其元素 Σ ( l ) ∈ R s × s \Sigma^{(l)}\in\mathbb R^{s×s} Σ(l)∈Rs×s为 Σ j k ( l ) = ρ ( l ) \Sigma^{(l)}_{ jk} = ρ^{(l)} Σjk(l)=ρ(l)对于 j ≠ k j\ne k j=k和 Σ j k ( l ) = 1 \Sigma^{(l)}_{jk} = 1 Σjk(l)=1对于 j = k j = k j=k
所以 p p p个变量中有 q q q组,每组包含 s = p q s = \frac{p}{q} s=qp个相关变量。然后我们用 b ( X ) = X v b(\mathbf X)= \mathbf Xv b(X)=Xv生成偏置项 b ( X ) b(\mathbf X) b(X),其中 v v v是中心协方差矩阵 n − 1 ∑ i ( x i − x ˉ ) ( x i − x ˉ ) ⊤ n^{−1}\sum_i (x_i−\bar x)(x_i−\bar x)^\top n−1∑i(xi−xˉ)(xi−xˉ)⊤对应其最小特征值 γ 2 \gamma^2 γ2的特征向量。最后,我们生成响应变量 Y Y Y如下:
Y = X β ˉ + b ( X ) + N ( 0 , 1 ) (23) Y=X\bar{\beta}+b(\mathbf X)+\mathcal N(0,1)\tag{23} Y=Xβˉ+b(X)+N(0,1)(23)
我们通过定义为 ∥ β ˉ − β ^ ∥ 1 \|\bar{\beta}-\hat{\beta}\|_1 ∥βˉ−β^∥1的绝对误差( β \beta β误差)来评估估计性能。在训练过程中,我们进行了30次实验,并报告平均 β \beta β误差作为估计误差。
对于预测,我们在训练中选择最准确的估计,并计算均方根误差(RMSE) 1 n ∑ i = 1 n ( Y i − Y ^ i ) \frac{1}{n}\sqrt{\sum^n_{i=1}(Y_i-\hat Y_i)} n1∑i=1n(Yi−Y^i),我们还进行了30次这个过程,并对结果进行平均。
特别是,在稳定学习中,我们想要评估方法在不同测试环境的变化分布中的性能。为此,我们用固定的 ρ train \rho_{\text{train}} ρtrain所有方法,并通过改变测试数据中的 ρ \rho ρ来产生不同的测试环境。
然后我们报告在各种测试环境下的平均预测误差来表示预测精度,它的标准差来表示预测的稳定性。一个稳定的模型不仅要产生较小的平均预测误差,而且要在不同的测试场景中产生较小的方差。
3.2.2结果
我们对 n , p , s n, p, s n,p,s和 ρ t r a i n \rho_{train} ρtrain进行了广泛的实验。
从图1和表1中,我们观察和分析如下:
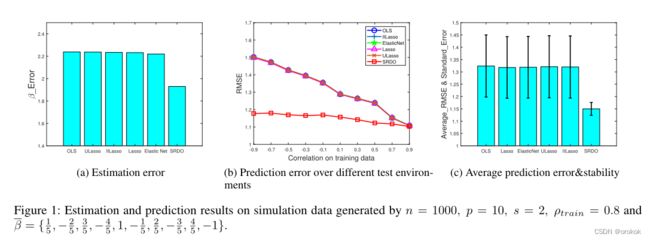

- 普通最小二乘在误差膨胀方面存在共线性,在大多数情况下性能最差,这与我们的理论分析是一致的。
- Lasso与OLS没有太大区别,因为我们在模拟中使用了密集的 β ˉ \bar{\beta} βˉ。最弱的信号的量级为0.2,与最大的信号相当,因此系数收缩机制在这种情况下通常很难工作。
- Elastic Net的表现略好于其他基线,因为它在共线情况下涉及 l 2 l_2 l2正则化
- ULasso和IILasso在本实验中并不能很好地解决共线性问题,因为他们假设在相关群中是稀疏的结构(即在多个相关变量中只存在一个活动变量),这在这里是不满足的。
- 从图1中我们可以发现,SRDO在变量间相关性强的情况下估计误差最小,在不同的测试设置下预测性能更稳定,达到了稳定学习的目的。注意,在图1 (b)的右端,所有方法都产生了可比较的结果,这与I.I.D.假设相吻合,因为训练数据中的强共线性仍然存在于测试数据中。但是,随着训练分布和测试分布的差异越来越大(从右端到左端),基线的性能迅速恶化。
- 从表1可以看出,当训练数据的共线性增强时,我们的方法在估计误差、预测误差和预测稳定性等各方面都比基线得到了更多的改进。
3.3现实回归实验
3.3.1数据集和实验性设置
在这个实验中,我们使用真实世界的房屋销售价格回归数据集(Kaggle),来自美国King County,其中包括2014年5月至2015年5月之间的房屋销售价格。
为了测试不同算法的稳定性,我们根据房屋建造年份模拟不同的“环境”。
由于架构的流行风格的变化,预测因子的分布以及它们的共线性可能会随着时间的变化而变化,这是相当合理的。
3.3.2结果
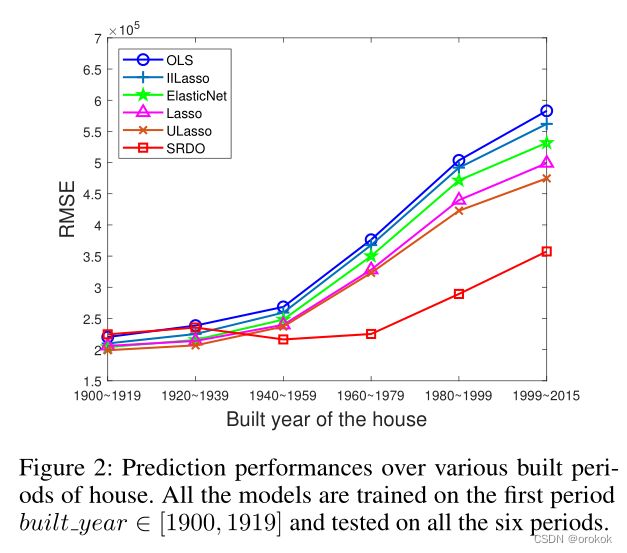
从图2中我们可以发现,与其他基线相比,我们的方法不仅实现了最小的平均误差,而且在不同的测试环境中具有更好的稳定性。结果与我们的假设一致,即通过较长时间跨度收集的数据会发生共线性模式的变化。因此,共线性的去除产生了一个更稳定的分布变化模型。
ElasticNet和Lasso与OLS相比获得了显著的优势,因为它们涉及 l 1 l_1 l1和 l 2 l_2 l2正则化,用于稀疏性和方差减少,这在实际应用中通常是有利的。
一个看似合理的原因是,与ULasso使用 R j k = ∣ r j k ∣ / ( 1 − ∣ r j k ∣ ) R_{jk}=|r_{jk}|/(1-|r_{jk}|) Rjk=∣rjk∣/(1−∣rjk∣),而不是在ULasso中 R j k = r j k 2 R_{jk}=r_{jk}^2 Rjk=rjk2,其中 r j k = 1 n ∣ X j ⊤ X k ∣ r_{jk}=\frac{1}{n}|X^\top_jX_k| rjk=n1∣Xj⊤Xk∣是绝对样本相关性。过度惩罚导致所选模型过于稀疏。
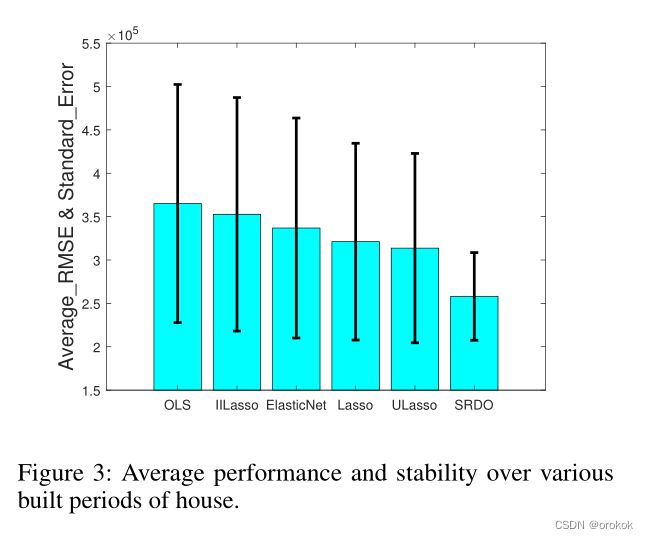
从图3中,我们可以发现所有方法在时间轴上都有明显的误差膨胀。
结果表明,该方法在3-6时间段的性能明显优于基线,且在前两个时间段的性能与基线相当,且分布没有明显变化。因此,在实际使用中,我们的算法更加可靠,尤其是在测试场景中预期会遇到明显的环境变化时。
3.4现实分类实验
3.4.1数据集和实验性设置
微信Ads是2015年9月从腾讯微信App收集的在线广告数据集,包含用户对广告流量的反馈。
为了测试不同算法的稳定性,我们通过用户年龄分层模拟不同的环境,因为我们认为年龄是影响个人兴趣、上网行为等的重要因素。具体来说,我们将数据集按用户年龄分为5个子集。
3.4.2结果
在图4中,我们根据每种方法的AUC绘制了分类性能。
与之前的回归实验类似,我们的方法通常在分布偏移较大且对训练分布和测试分布之间的差异更稳健的情况下有效。
与回归任务相比,AUC的整体改善程度较为温和的一个看似合理的原因是,该数据集的共线性问题不像房屋销售数据那么严重,这对传统方法造成的估计偏差膨胀较小。
总结与讨论
本文研究了具有模型错误描述偏差的线性回归的稳定学习问题。我们提出了一种通过采样重加权来减少共线性对训练数据影响的方法。我们从理论上证明了存在一组最优的样本权值,使设计矩阵在理想情况下接近正交。在更实际的情况下,实证结果表明,当测试数据与训练数据不同时,我们的方法可以提高线性模型的稳定性。我们的方法是一种通用的数据预处理方法,可以无缝集成到经典的线性模型如普通最小二乘和逻辑回归。它为缓解统计估计的共线性问题提供了一种统一的方法。
Reference
Stable Learning via Sample Reweighting