黑金fpga_基于FPGA的卷积神经网络加速器设计与实现
随着计算机处理能力的提高,神经网络作为人工智能研究和发展的新方向,已成为机器学习领域的热点。而卷积神经网络(CNN)是一种源自人工神经网络的深度机器学习算法,在视频监控、机器视觉、模式识别等领域,已经得到了广泛的应用。其对图像的平移、比例缩放、倾斜等形式的变形,具有高度的适应性,能够灵敏的提取图形特征,避免了传统识别算法中复杂的特征提取和数据重建过程。目前,卷积神经网络的传统实现多为在通用处理器平台上,以软件方式运行,其运算性能、功耗、体积等 都急需改善。而 CNN 网络结构具有高度并行性,通用处理器为执行逻辑处理和事务处理而优化的特性并不适合用来挖掘卷积神经网络固有的并行特性。鉴于此,本文充分利用半定制集成电路 FPGA 拥有大量逻辑单元和布线资源,并具有并行处理、速度快、功耗低、小型化等优势,设计了一种基于 FPGA 的 CNN 加速器。
1 卷积神经网络
1.1)基本概念
卷积神经网络作是基于动物视觉感受野设计而成的,是神经网络领域一个重要的研究分支,是一种非常典型的前向传播神经网络,特别适合于二维数据处理的应用场景。其包含输入层、输出层和隐含层。其中,输入层神经元个数与输入数据维数相关;输出层神经元个数与需要识别的种类数相同,通常采用全连接方式;隐含层可以是单层也可以是多层,通常由交替出现的卷积层和池化层组成。卷积层是用一个卷积核与图像对应区域进行卷积,并通过激活函数进行非线性变换,得到一个值,然后不断的移动卷积核窗口,进行卷积、激活运算,完成对整个图像的卷积。卷积核大小通常选为 5×5 或者 3×3,其深度与输入图像的深度相同,步长是卷积核滑窗时移动像素的个数。池化层位于卷积层中间,或者卷积层与输出层中间,其主要作用是用来逐步压缩神经元和权值数量,将上一层卷积结果,通过滑动池化窗口,将窗口内数据取最大值或者取均值,压缩成一个值,其滑动窗口大小和步长决定了输出特征图的大小。CNN 每一层的特征都是由上一层的局部而非全局区域通过共享权值的卷积核激励而得到,如下面公式所示,减少权重数量,降低训练难度。这里,m, n 分别表示输入输出特征图个数,xlj 代表第 l 层的第 j 张特征图,f 为激活函数,kij,bj 分别表示对应层的 权重和偏置。

1.2)CNN网络结构
本设计所采用的 CNN 基本结构如下图所示。

依次包含输入层、第一次卷积层 C1、第一次池化层 S2、第二次卷积层 C3、第二次池化层 S4 和全连接输出层 O5。输入灰度图像分辨率为 28×28,经过 C1、S2、C3、S4 的特征提取,最后经过 O5 层输出图像分类结果。
在 C1 层分别与 6 个 5×5 的卷积核进行卷积操作,卷积步长设为 1,从而分别得到 6 个 24×24 的卷积图像,将图像中的每个像素加上偏置后,经过激活函数得出该层的 6 个 24×24 的输出特征图。激活函数一方面将数据钳制在一定范围内,另一方面页可以增加网络的非线性因素。常用的激活函数如 Sigmoid 函数、ReLu 函数等,这里选择传统的 Sigmoid 函数作为该网络的激活函数。该层有 24×24×6=3456 个神经元,5×5×6=150个权值,1×6=6 个偏置,以及(5×5+1)×3456=89 856 条连接。
S2 层为池化层或者称为下采样层,这里,采用均值池化方式,既减少预算复杂程度又避免丢失神经元信息。采样模板大小为 2×2,采样步长设为 2,对输入图像的每个 2×2 区域进行均值采样,由于采样步长为 2,使得相邻采样窗口,无重叠区域。该层输出 6 个 12×12 的特征图像,产生 12×12×6=864个神经元。
C3 层与 C1 层类似,对 6 个 12×12 的特征图像中的每一个,分别与 12 个 5×5 的卷积核进行卷积操作,卷积步长设为 1,从而分别得出该层的 12 个 8 ×8 的卷积图像,共 6 组。然后,将每组中相应位置的 6 个图像中像素点依次相加,再加上偏置后,经过激活函数,共得到 12 个 8×8 的输出特征图像。该层 有 8×8×12=768 个神经元,8×8×5×5×12×6=115 200 个权值,1×12=12 个偏置,以及 115200+8×8×12=115 968 条连接。
S4 层与 S2 层类似,采样模板大小为 2×2,采样步长设为 2。该层输出 12 个 4×4 的特征图像,产生 4×4×12=192 个神经元。
在 O5 层,将 S4 输出的 192 个神经元展成一维向量的形式,作为 O5 层的输入,输出为 10 个神经 元的全连接单层神经网络。该层共有 192×10=1920 条连接。
2 CNN加速器的FPGA实现
2.1) 流水线结构设计
在 CNN 五层结构中,卷积层、池化层和输出层都有并行计算特点,充分利用 CNN 自身结构特点,采用深度流水线、并行处理方式,最大限度提高处理速度和图像数据吞吐量。这里以 C1 和 S2 层为例,介绍其流水线实现方式。
对于 C1 层而言,如下图所示,为节约 FPGA 端口数量,其输入数据为将 28×28 的二维图像转为 784×1 的一维图像,每个像素点值依次输入,在 C1 层内部,首先经过 FIFO 进行缓存,解决外部图像输入与内部计算电路时钟域异步问题。由于 FPGA 外部时钟输入为 50MHz,图像输入频率为 50MHz,电路内部动作以 75MHz 为基准。图像缓存后,为便于流水线卷积操作,经过片内 5 个移位 RAM,首尾相接方式,实现 5 行数据同时输出结构,再经过 5×5 寄存器阵列缓存,形成 5×5 可供卷积运算的图像像素窗口,分别与 6 个 5×5 卷积核进行卷积运算后,与相应偏置求和后,进入激活函数。由于该层输出神经元结构为 24×24 的特征图像,并且卷积窗口在行间移动时会产生 5 个时钟周期的空档期,这里,为使电路结构清晰并便于电路实现,将激活函数输出结果分行存储于 24 个单行 FIFO 中。
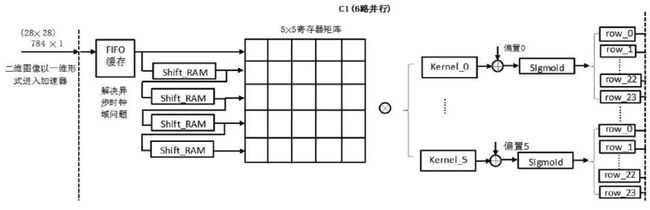
对于 S2 层而言,由于 C1 层对计算结果的 6 个特征图中的每一个进行了 24 行分行 FIFO 缓存,为池化操作提供了便利。由于选用 2×2 窗口池化,如下图所示,对 24 行 FIFO 读数据输出进行分组,两行为一组,共 12 组,分别进入 2×2 寄存器阵列,实现流水池化操作。这里,池化采用均值池化,即取池化窗口中 4 个元素的平均值作为池化结果,即将 4 个像素值求和再右移 4 位,得出池化输出。该层输出神经元为 12×12 特征图像,仿照 C1 层实现方式, 这里,12 行数据分别缓存于 12 个单行 FIFO 中,并通过行选择器,将 12 行逐一输出,转为一维图像数据。

C3 层的实现方式与 C1 层的实现方式具有较大的相似性,6 个通道同时进行并行运算,每个通道经过 FIFO 进行层间缓存,经过片内 5 个移位 RAM,首尾相接方式,实现 5 行数据同时输出结构,再经过 5 ×5 寄存器阵列缓存,形成 5×5 可供卷积运算的图像像素窗口,分别与 1 个 5×5 卷积核进行卷积运算。6 个通道同时运算,运算结果求和,再加上相应偏置,进入激活函数。将激活函数输出结果分行存储于 8 个单行 FIFO 中。S4 层与 S2 层的采样方式类似,共 12 个通道,对 8 行 FIFO 读数据输出进行分组,两行为一组,共 4 组,分别进入 2×2 寄存器阵列,实现流水均值池化操作。该层输出神经元共 12×4×4=192 个。
O5 层为全连接输出层,输入来自 S4 层输出的192 个神经元,输出为 10 个分类结果,通过权重,实现全连接。每个输出对应 192 个权重,每 192 个权重以初值形式保存在 ROM 中,共 10 个 ROM。分别与192 个神经元相乘求和,得出中间分类结果,最后,遍历一遍输出结果,得出最大值,即最终分类结果。
2.2)片上存储器使用优化
FPGA 片内有一定的存储器资源,可以作为 RAM 使用也可作为 ROM 使用。通常 CNN 权值即可保存于片上存储器资源,也可以保存于片外 SDRAM 或者 Flash 中等,但从权值获取速度来看,片内存储器有明显优势。这里,为节省片内存储器资源,将一部分权值保存于片内存储器,另一部分权值以参数形式(parameter)直接参与运算。节省下来的资源,供卷积层和池化层缓存神经元数据使用。这样避免了将中间计算结果保存于片外 SDRAM 时的读写时间,进一步提高 CNN 计算速度。
2.3)浮点数定点优化
首先对输入图像的 0~1 浮点数,进行定点化处理,以方便在 FPGA 内部的数字系统进行运算。这里,为尽量减少数据定点化引起的数据精度损失,将图像数据放大 4096 倍,以 16 位存储,留出一定位宽余量。同时,前向传导各权值经过归一化处理后,也放大 4096 倍,以参数或者 ROM 初值形式,参与 FPGA 内部电路运算。当卷积操作时,涉及到图像数据与权值相乘,相当于倍数放大了 4096×4096=224 倍,为保证数据前后放大倍数的一直性,将相乘结果右移 12 位,再参与后续计算。
2.4)激活函数分段拟合优化
考虑到 FPGA 内部电路资源的限制,为网络引入非线性的同时,能够保证较高运算精度,最常用的激活函数查找表实现方式消耗大量存储器资源,无法满足本设计需求。这里,为了节省存储器资源,特别是片内存储器资源,同时保证精度,采用曲线分段拟合的方式实现。由于该 CNN 选用 Sigmoid 函数,如下公式所示,
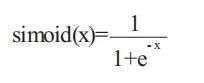
作为激活函数,这里只对 Sigmoid 函数进行曲线拟合。输入数据在[0,32767]范围内时,FPGA 分段拟合结果如下表所示。

根据 Sigmoid 函数的对称性,输入数据在 [32768,65536] 范围内时,根据以下公式得出输出值。
曲线拟合过程中,需要进行乘法和除法运算,乘法采用 16 位带符号位定点硬核乘法器实现,除以 4096 采用右移 12 位来实现。
3 实验结果与分析
CNN 网络训练过程在 PC 机中完成,并保存训练权重,将训练权重定点化后引入 FPGA 电路中,供前馈网络使用。FPGA 电路在黑金开发板 AX- 301 上实现,器件为 CycloneIV 系列的 XC7A200TSBG484,开发环境为 Vivado2018,仿真采用 Vivado 自 带仿真器。数字识别库选用 MNIST 数据集,其中训练集有 60 000 幅图像,测试集有 10 000 幅图像,每幅图像均为 28×28 像素的灰度图像,灰度值为 0~1 的浮点数值,定点化后送入 FPGA 中进行识别。FPGA 内部资源利用情况如下表所示,其乘累加速率可达到 0.598GMAC/s,功耗为 1.225w。以识别手写数字“6”为例,仿真波形如下图所示。


4 结语
本系统充分利用 FPGA 的高速并行处理能力和低功耗特点,实现了基于 FPGA 的卷积神经网络前馈网络加速器的设计。充分挖掘 CNN 网络结构特点,有效利用 FPGA 片上存储器资源,提高电路并行度,并以流水线结构提高运算速度和数据吞吐量。通过 MNIST 数据集对前馈网络进行测试,实现了对手写数字的识别。