sklearn-决策树,及决策树的可视化
决策树(Decision Tree):是在已知各种情况发生概率的基础上,通过构建决策树来进行分析的一种方式,是一种直观应用概率分析的一种图解法

但对于同一个问题,不同的分类顺序会决定分类的效率及其树的深度。所以对于树节点的选择,需要一定的计算方法,使得节点分配的效果最好。因此需要信息论的一些知识。
1.信息的定义:信息是用于消除随机不确定性的东西。
例子:假如你的一个同学,你不知道他的年龄。所以对于你来说,他的年龄就是一个随机不确定的。假如他第一次告诉你他的年龄,那么这个随机不确定量就消除了,所以这句话是信息。但是如果他第二次告诉你他的年龄,这个时候,这句话就不是信息了,因为你对于年龄这个变量已经不是不确定的了
2.信息墒:可以你对于结果的不确定的程度。
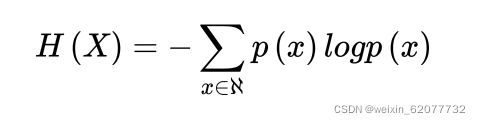
解读:n的值代表结果可能的个数。对于这个例子,我们可以用抛硬币的实例来解读。
eg:对于每一次抛硬币,结果是1/2,这一点毋庸置疑。但是,假如我们知道了硬币的质地,落地点的地形,和上抛的速度和力度这些特征,那么对于硬币正反面的结果的预测将不会仅限制于1/2 。这也就是特征对信息墒的减少。
在这个例子中,结果有两个,正面和反面。那么n的取值就是2,p(x) 表示在整个数据集中,硬币正面/反面的次数。也就是1/2
3. 条件墒:可以反应知道某一个条件后,信息墒的值
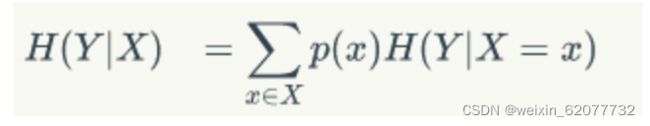
假设拿硬币质地来计算,硬币的质地分为3种,软,硬,中等
那么条件墒就变成了
p(硬)H( Y | X=硬)
p(软)H( Y | X=软)
p(中)H( Y | X=中)
这三者的加合
4.信息增益 = 信息熵 - 条件熵
信息增益可以看出对于一个条件已经知道的情况下,对于信息不确定性的减少。这正可以作为对于决策树的节点的选择
对于决策树节点的选择,有很多方法。这里只用着一种简单的方法。在API中有更加多的方法可以实现
随机树生成API:
# 信息获取
# 数据处理
# 数据分割
# 数据特征提取
# 数据预处理
# 数据的降维
# 模型构建 - 预估与调优
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
data = pd.read_csv('DS/wine/winequality-red.csv')
feature = data.iloc[:, :11]
target = data.iloc[:, 11:]
target = target.values.ravel()
x_train, x_test, y_train, y_test = train_test_split(
feature, target, test_size=0.25, random_state=0)
# 节点的选择方法,默认选择gini, max_depth是树的最大深度
estimator = DecisionTreeClassifier(criterion="gini", max_depth=12)
estimator.fit(x_train, y_train)
dict = {"max_depth": [12, 12, 13, 14, 15, 16]}
estimator = GridSearchCV(estimator, param_grid=dict, cv=8)
estimator.fit(x_train, y_train)
print(estimator.score(x_test, y_test))
print(estimator.best_estimator_)
0.635
DecisionTreeClassifier(max_depth=16)相比于knn的0.58,决策树在处理较大的数据的时候,表现较出色。
对于数据的可视化:
使用graphviz库来实现:对于mac用户,还要下载graphviz
brew install graphvizimport pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.tree import export_graphviz
import graphviz
data = pd.read_csv('DS/wine/winequality-red.csv')
feature = data.iloc[:, :11]
target = data.iloc[:, 11:]
target = target.values.ravel()
x_train, x_test, y_train, y_test = train_test_split(
feature, target, test_size=0.25, random_state=0)
# 节点的选择方法,默认选择gini, max_depth是树的最大深度
estimator = DecisionTreeClassifier(criterion="gini", max_depth=12)
estimator.fit(x_train, y_train)
dict = {"max_depth": [16]}
gcv = GridSearchCV(estimator, param_grid=dict, cv=8)
gcv.fit(x_train, y_train)
dot_data = export_graphviz(estimator, out_file=None,
feature_names=list(data.columns)[:11])
pic = graphviz.Source(dot_data)
pic.render('绝对路径/名称')
print(gcv.score(x_test, y_test))
print(gcv.best_estimator_)就可以生成 对应的PDF了