《YOLOF:You Only Look One-level Feature》论文笔记
参考代码:YOLOF
1. 概述
导读:回顾之前检测网络中普遍使用的FPN网络进行不同尺度特征的融合,以及在不同scale下进行目标检测(不同size的目标会被分配到不同stride的FPN特征图上),这其实是一种分而治之的策略。但是这样的网络设计方式会带来较多的计算开销,毕竟需要计算那么多层级的FPN金字塔。而这篇文章的思路便是思考可否将FPN网络进行简化,这样检测网络的耗时就能得到极大减少。对此文章将FPN网络部分进行替换,只使用一个C5特征尺度完成全尺寸的目标检测任务。对于感受野问题,文章通过带shortcut连接的膨胀卷积block实现感受野的增大,同时保持对较大目标尺寸范围的适应性。解决感受野问题之后剩下的问题就是只使用1个尺度进行预测带来的正样本匹配问题了,对此提出了一个新的匹配优化策略。从而检测算法在编码器阶段得到极大简化,从而在保持性能的同时做到在速度上带来较大提升(baseline为RetinaNet)。
在上文中提到了FPN网络中比较重要的作用是:多尺度特征聚合、目标分层优化。那么具体上面两个功能对最后性能的影响更大?对此文章对FPN网络进行实验,得到下图:

通过对上图进行分析可以得到:
- 1)在图b中只使用C5的特征图作为输入,但是输出很多层次的特征,其得到的性能与图a的性能近似;
- 2)结合图c和图d可以得到,多尺度输入单尺度输出相比于单尺度输入单尺度输出来讲性能差异其实不大,也就是说多尺度特征聚合影响相对较小。
那么结合上述的两点结论可以得到:在FPN网络中占据性能主导地位的是多尺度预测,也就是文中提到的分而治之的策略。而且C5特征图中已经包含了适应和回归多种尺度目标能力。
则按照上述文章提到的两个思路去解决感受野问题与正样本不均衡问题,则得到的网络与其它网路在性能上进行对比,见下图所示:
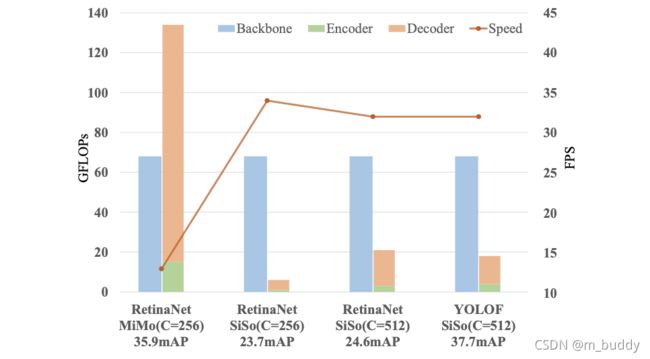
2. 解决问题的思路
2.1 感受野问题
感受野是网络能够描述目标尺度的能力,在只使用C5特征的时候其感受野如下图的a图所示,其感受野是不能涵盖到更大的目标的。那么要增加感受野一个最常用的方法就是通过级联膨胀卷积的形式,则得到的感受野如下图的b图。
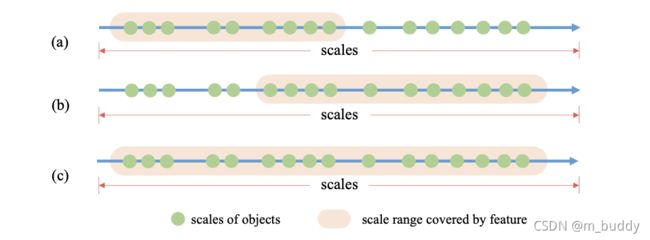
既然,增加膨胀卷积能够实际带来感受野的增加,那么怎么才能保持对低scale目标的适应能力呢?自然的想法就是shortcut连接,这样不仅保证了网络可以获取较大的感受野,而且还可以保留对低scale目标的适应能力,则对上面提到的膨胀卷积进行重新设计,其结构见下图所示:

则经过这样的改进之后,文章的感受野范围变成了适应较大范围的c图了。
2.2 正样本不平衡性问题
在传统的检测算法中通常采用Max-IoU的形式进行正样本选择,这种方式在多尺度预测的时候问题不大,但是将该方法运用于文章的方法就会存在问题了,见下图所示:

这是因为按照该选择方式会天然偏向与大尺度的目标,对应的中等和小目标正样本的比例就偏少,从而影响检测网络的学习能力。对此,文章选择对每个GT进行均匀匹配(Uniform Matching)的形式,也就是对每个GT box选择最匹配的检测框和anchor(这里的anchor scale设置为 [ 32 , 64 , 128 , 256 , 512 ] [32, 64, 128, 256, 512] [32,64,128,256,512]),实现上可以参考:
# playground/detection/coco/yolof/yolof_base/uniform_matcher.py#L40
cost_bbox = torch.cdist( # 计算预测框与GT的匹配度
box_xyxy_to_cxcywh(out_bbox), box_xyxy_to_cxcywh(tgt_bbox), p=1)
cost_bbox_anchors = torch.cdist( # 计算anchor与GT的匹配度
box_xyxy_to_cxcywh(anchors), box_xyxy_to_cxcywh(tgt_bbox), p=1)
# Final cost matrix
C = cost_bbox
C = C.view(bs, num_queries, -1).cpu()
C1 = cost_bbox_anchors
C1 = C1.view(bs, num_queries, -1).cpu()
sizes = [len(v.gt_boxes.tensor) for v in targets]
all_indices_list = [[] for _ in range(bs)]
# positive indices when matching predict boxes and gt boxes
indices = [ # 按照匹配度统一选择对应数量的预测框
tuple(
torch.topk(
c[i],
k=self.match_times,
dim=0,
largest=False)[1].numpy().tolist()
)
for i, c in enumerate(C.split(sizes, -1))
]
# positive indices when matching anchor boxes and gt boxes
indices1 = [ # 按照匹配度统一选择对应数量的anchor
tuple(
torch.topk(
c[i],
k=self.match_times,
dim=0,
largest=False)[1].numpy().tolist())
for i, c in enumerate(C1.split(sizes, -1))]
这里的均匀匹配机制与ATSS的方法进行比较,ATSS在 L L L层的特征上针对每个GT box选择 k k k最匹配的anchor,之后在 L ∗ k L*k L∗k个匹配anchor上使用动态IoU阈值选择正样本,因而整体工作偏向于正负样本的自适应。而文章的方法侧重的是不同尺度正样本的均衡性。
文中还有一点工作是对预测模块进行改进,将边界框回归特征编码的目标特征与分类特征进行融合,也就是下图中的解码器部分:

对应的实现可以参考:
# playground/detection/coco/yolof/yolof_base/decoder.py#L93
def forward(self,
feature: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
cls_score = self.cls_score(self.cls_subnet(feature)) # [N,A*C,H,W]
N, _, H, W = cls_score.shape
cls_score = cls_score.view(N, -1, self.num_classes, H, W) # [N,A,C,H,W]
reg_feat = self.bbox_subnet(feature)
bbox_reg = self.bbox_pred(reg_feat) # [N,A*4,H,W]
objectness = self.object_pred(reg_feat) # [N,A,H,W]
# implicit objectness
objectness = objectness.view(N, -1, 1, H, W) # [N,A,1,H,W]
normalized_cls_score = cls_score + objectness - torch.log(
1. + torch.clamp(cls_score.exp(), max=self.INF) + torch.clamp(
objectness.exp(), max=self.INF)) # [N,A,C,H,W]
normalized_cls_score = normalized_cls_score.view(N, -1, H, W) # [N,A*C,H,W]
return normalized_cls_score, bbox_reg
2.3 消融实验
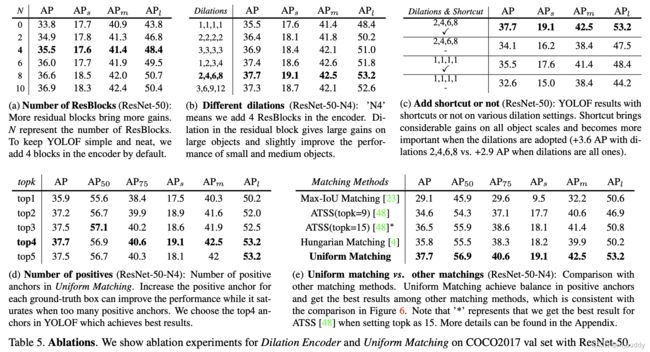
整体消融实验结果:

内部具体模块详细消融实验:
3. 实验结果
