【论文笔记】:PSS(NMS-free)
&Title

- Object Detection Made Simpler by Eliminating Heuristic NMS
- 代码
&Summary
Motivation:如果网络只能为图像中的每个实例对象识别一个正样本,那么就没有必要使用NMS。
all the locations on the CNN feature maps within the center region of an object are assigned positive labels. As a result, multiple network outputs correspond to one target object. The consequence is that for inference, a mechanism (namely, NMS) is needed to choose the best positive sample among all the positive boxes.
作者提出了一个简单的NMS-free、端到端目标检测框架,该网络是对单级目标检测器(如FCOS、ATSS)的最小修改,可达到同等甚至更高的检测精度。它以几乎相同的推断速度执行检测,同时更简单,因为现在在插入期间消除了后处理NMS(非最大抑制)。
作者通过附加一个PSS head自动为每个实例选择单一正样本。通过采用停止梯度操作,解决学习目标产生的标签冲突问题(面对的一对多,一对一的标签分配,有些标签冲突的训练的例子,会使得学习具有挑战性)
PSS Advantages
- 去除了 NMS 后,检测更加简洁。FCOSPSS继承了 FCOS 的简洁,FCOSPSS可与其它可用 FCN 解决的任务完全兼容。
- 证明了 NMS 可以通过一个简单的 PSS head 去除,计算量可以忽略不计。
- PSS 非常灵活,PSS head 本质上是可以学习的 NMS。通过设计,FCOS heads 也可以与原来的检测器表现一样好,FCOSPSS就在是否使用 NMS 方面给出了足够的灵活度。例如,一旦训练好,我们可以选择不用 PSS head,将 FCOSPSS作为标准的 FCOS 使用。
- 作者报告了 COCO 数据集上的检测结果,与标准 FCOS 和 ATSS 检测器,以及最近的 NMS-free 检测器做了比较。
- PSS head 也适用于其它基于 anchor box 的检测器,比如 RetinaNet。在 RetinaNet 检测器中加入 PSS 后,作者得到了优异的结果,该方法在每个位置上应用一个正方形的 anchor box,并且采用了自适应训练采样来提升检测准确率。
- 这个思想也可以用到其他实例识别任务上。例如,我们可以在实例分割任务上去掉 NMS。作者希望本工作可以让基于 FCOS 检测器的工作受益,包括实例分割、关键点检测、文本检测、跟踪等。
&Research Objective
NMS-free
anchor-free 的检测器如 FCOS 和 FoveaBox提出后,NMS 成为了整个流程中仅有的启发式后处理。
&Problem Statement
- NMS 成为了整个流程中仅有的启发式方法
Since anchor-free detectors such as FCOSand FoveaBox were introduced, the community tend to recognize that anchor boxes may not be an indispensable design choice for object detection, thus leaving NMS (nonmaximum suppression) the only heuristic post-processing in the entire pipeline.
- FCOS、FoveaBox训练过程中单个 ground-truth 目标可能有多个正样本。CNN 特征图上,目标中心区域内所有的位置都会被赋予正标签。结果就是,单个目标物体可能对应着多个网络输出。这样就不得不需要 NMS 操作来从中选择最佳的正样本。
For instance, in FCOS and FoveaBox, all the locations on the CNN feature maps within the center region of an object are assigned positive labels. As a result, multiple network outputs correspond to one target object. The consequence is that for inference, a mechanism (namely, NMS) is needed to choose the best positive sample among all the positive boxes.
- 已有的相关工作证明,NMS是可去掉的
- [1, 34] formulate detection into a set-to-set prediction problem and leverage the Hungarian matching algorithm to tackle the issue of finding one positive sample for each ground-truth box.
- Wang et al. [26] design a fully convolutional network (FCN) without using Transformers and achieve end-to-end NMS-free object detection.
&Method(s)
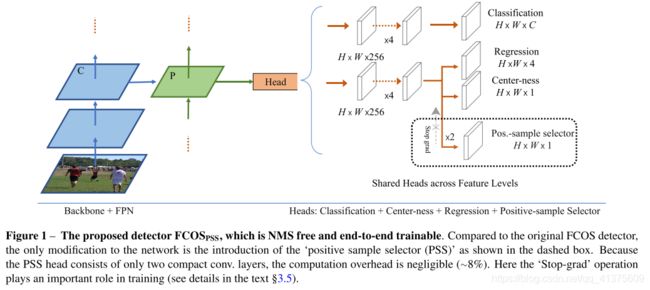
作者设计了一个简单效率高的全卷积目标检测网络,它没有用 NMS 操作,且是端到端的训练。作者基于 FCOS 检测器实例化了该方法,只做了些许的改动,如图1所示。
实际仅有的改动就是 :
- 增加了一个“正样本选择器”(PSS) head,它可以为每个目标实例选择最佳的正样本;
- 重新设计了目标函数,让检测器可以成功地训练。
在训练网络时,作者保留了原生的 FCOS 分类损失。因为它所提供的丰富的监督信息编码了那些不变的 encoding。此外,如3.4节所介绍的,一对多和一对一的标签分配差异会造成网络训练的困难,作者提出了一个简单的非对称优化机制:停止-梯度操作(参见图1),停止将 PSS head 相关的梯度传递给原生的 FCOS 网络参数。
loss function
整体的训练目标函数可以表示为:
![]()
这里λ1 ,λ 2是平衡系数。Lfcos则是损失项,与原生 FCOS 中的一样,即分类损失使用的是 focal loss,边框回归使用的是GIOU 损失,以及 center-ness 损失。
PSS Loss Lpss
L pss是本框架成功的关键,它是一个分类损失,与正样本选择器相关联。
作者目的是在单张图像中,为每个实例只选择一个正样本。PSS head 就是为了这个目的新增的
PSS head 的输出是一个形状为RH × W × 1 的特征图。用σ ( pss ) 来表示该特征图上的一个点。如果它对应着一个实例正样本,则σ ( pss ) 的目标值就是1;否则就是负标签。所以,最简单的方法就是用二元分类器。这里,为了利用FCOS 中的 C-way 分类器,作者将该损失项表示为 C-way 的分类问题。该损失项计算的 focal loss 是:

σ(s) 是FCOS 分类器输出的得分图。σ ( ctr )是center-ness 得分,这样就可与原生的 FCOS 兼容。该分类器和原生 FCOS 分类器的差别就是,图像中每个目标实例只有一个正样本。
Ranking Loss Lrank
作者为每个训练图像都增加了 ranking loss:
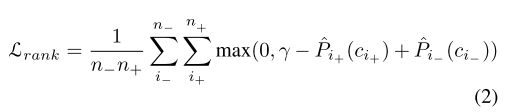
这里,γ 是个超参数,代表正负 anchors 间的 margin。在实验中默认设γ = 0.5。n −和n+表示正负样本的个数。P^i + ( ci )表示正样本i+属于类别ci+ 的分类得分,P^i- ( ci- )表示负样本i-属于类别ci-的分类得分。在实验中,作者从所有的负样本中选取最n_个 P^i- ( ci- )的样本,所有的实验中 n_= 100。
One-to-many Label Assignment One-to-many
一个实例有多个边框的好处就是丰富的特征表示可以提升分类器的学习能力,比如高宽比不变性和平移等。后果就是单个真实实例边上会有多个检测边框。所以NMS 就变得非常必要,它可以清理检测器的输出。
尽管一对多分配策略依赖于 NMS 后处理,但是它的意义体现在:
- 更丰富的训练数据可以帮助学习特征不变性,这非常有用;
- 这和当前所有深度学习技术的数据增广方式一致。所以,作者认为保留 FCOS 中一对多的标签分配策略非常重要。
现有目标检测任务广泛采用了一对多的标签分配 :单张训练图像中的每个目标实例都被分配到多个 ground-truth 边框。因为标注 ground-truth 边框本身就是模棱两可的,边框挪动几个像素仍然会表示同一个物体,因此也会被认为是正样本。这也是为什么一对一的标签分配策略很难产生令人满意的结果,因为要找到定义准确的标注框很难。
One-to-one Label Assignment
进行一对一标签分配时,我们需要为每个 ground-truth 实例 j(c j和bj分别是 ground-truth 的标签和边框坐标) 选择匹配度最高的anchori(这里 anchor 表示 anchor box 或 anchor point)。

[26]指出的,最佳匹配应该包括分类和定位。当前检测网络的分类质量和定位质量应该在匹配得分Q i,j 演一定的角色。
这里si和ctr i 表示 anchori分类得分和 center-ness 预测。而且 pss i 表示二元 mask 预测得分,是正样本选择器 PSS 的输出。P ^i ( c j) 表示 anchor i 属于类别c j的分类得分。注意,σ ( ⋅ ) ∈ [ 0 , 1 ] 是 sigmoid 函数,将得分归一化为一个概率值。在上面等式中,作者假设三个概率是独立的,这样它们的乘积就是 P ^ i ( c j )
现在Q i,j代表 anchori 和 ground-truth 实例j 的匹配分数。cj是实例j 的 ground-truth 类别标签。 P ^ i ( c j ) 表示 anchor i 对应类别标签c j 的预测得分。b ^ i表示 anchori的预测边框坐标;b j 表示实例 j 的 ground-truth 边框坐标。超参数α ∈ [ 0 , 1 ] 用于调节分类和定位的比值。
在本文中Ω j 只是原始检测器所用到的正样本。例如,FCOSPSS 使用实例 j 中心区域的 anchor points 作为Ω j ,这和 FCOS 一样。ATSSPSS 则使用了 ATSS 采样策略。
最终通过匈牙利算法来解决二分图匹配问题,图像上每个ground truth 实例 j 都得到一个标签,对每个实例 j 都通过最大化值∑ j Q i , j,找到最佳的 anchor 索引 i。作者发现,如果使用简单的 top-one 选择来替换匈牙利算法,也可得到类似的表现。
Conflict in the Two Classification Loss Terms
Conflict: 对于等式1中的目标函数,作者最小化两个相关的分类目标损失项。
- 第一个是原生 FCOS 分类项(一对多),Lfcos。假设一个目标实例得到了 k 个正样本(anchor boxes 或 points)。
- 第二个分类就是 PSS 项,Lpss 。Lpss 的主要责任是将单个正样本(从 k 个正样本)从其余样本中区分开来。
因此当训练 PSS 分类器时,对于Lfcos,k 个正样本中就有 k − 1 个会被认为 ground-truth 是负的样本。要想兼容这两个损失项就很麻烦,因为标签不是连续的。
换句话说,当我们训练模型时,一些样本被同时认为是正样本和负样本。这个冲突可能损害最终模型的表现。
为此,作者提出了一个简单而有效的非对称优化机制。具体地说,不将 PSS head 相关的梯度传入原生的 FCOS 网络参数(虚线边框以外的网络)。这在图1中被标记为"停止-梯度"操作。所以,该 PSS head 对原生 FCOS 训练的影响是最小的。
Stop Gradient
用 SGD 更新原生 FCOS 的参数时,PSS head 设为常数,因此 PSS 传回到网络其余部分的梯度就是0。
将 θ = { θfcos, θpss} 作为网络所有要优化的变量,可分为2个部分。本质上,停止-梯度操作要做的就是交替地优化这两个部分的变量。
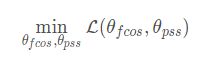
我们可以交替地解决这2个子问题(t tt表示迭代索引):

当我们解决等式5时,关于 θpss的梯度就是0。
使用了停止-梯度操作的 SGD 只是对上述交替优化的近似,因为我们无法将每个子问题收敛。
我们可能只一次交替就解决这2个子问题。初始化 θpss=0,解决等式5 直到收敛,然后解决等式6。这与训练原生 FCOS 直到收敛,然后冻结 FCOS,然后训练 PSS head 直到收敛等价。实验表明,这会造成检测性能些许下降,但是极大地增加训练计算时间。
&Evaluation
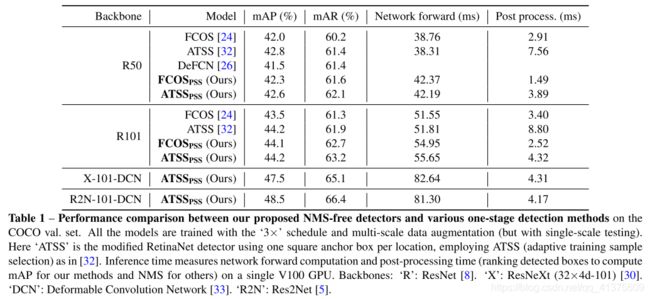
- 表一:作者提出的 NMS-free 检测器和各种单阶段检测方法的性能比较
- 表二:作者通过实验证明了,使用停止-梯度操作会持续地提升模型准确率

- 图二:FCOSpss通过停止-梯度操作训练而来,可以极大地抑制重复预测。

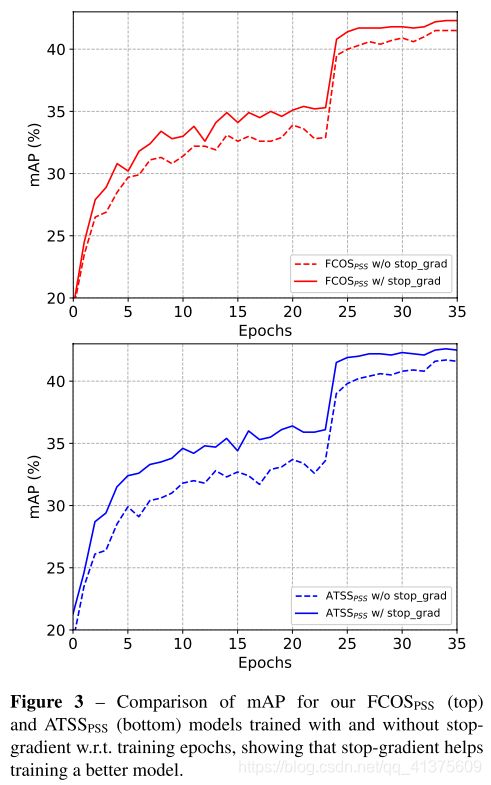
- 图三:停止梯度操作可以让模型更优
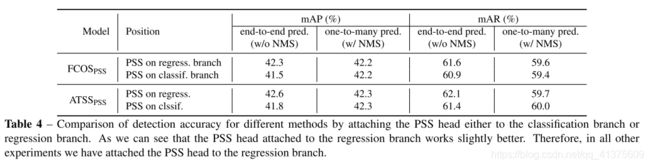
- 表四:将PSS连接到分类分支或回归分支,检测精度比较
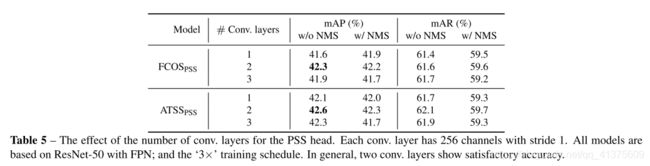
- 表五:PSShead的conv层数消融实验
- 其他消融实验看原文
Conclusion
作者提出了一个更简单和更有效的E2E检测框架,仅需要对FCOS、ATSS进行简单的修改,就能移除NMS,并且达到和超过ATSS、FCOS的baseline。作者保留了原始detector,所以模型训练完成后,我们还可以继续选择使用NMS的结果,而去除NMS的pipeline使得我们模型更加容易部署。