CUDA编程第二章: CUDA编程模型
CUDA编程模型概述:
以程序员的角度可以从以下几个不同的层面来看待并行计算。
-
领域层
-
逻辑层
-
硬件层
在编程与算法设计的过程中,你最关心的应是在领域层如何解析数据和函数,以便在并行运行环境中能正确、高效地解决问题。
当进入编程阶段,你的关注点应转向如何组织并发线程。在这个阶段,你需要从逻辑层面来思考,以确保你的线程和计算能正确地解决问题。
在C语言并行编程中,需要使用pthreads或OpenMP技术来显式地管理线程。CUDA提出了一个线程层次结构抽象的概念,以允许控制线程行为。在阅读本书中的示例时,你会发现这个抽象为并行编程提供了良好的可扩展性。在硬件层,通过理解线程是如何映射到核心可以帮助提高其性能。
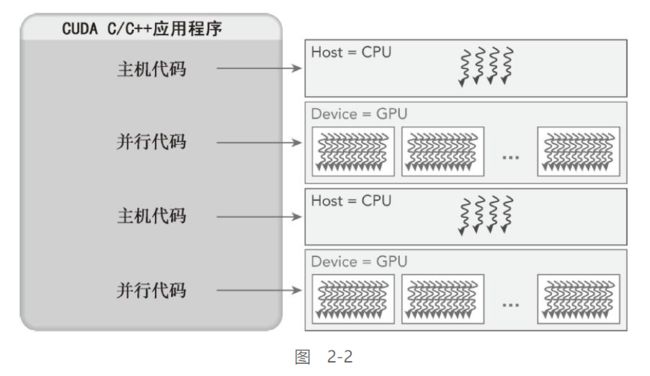
CUDA编程结构:
一个典型的CUDA程序实现流程遵循以下模式。
1.把数据从CPU内存拷贝到GPU内存。
2.调用核函数对存储在GPU内存中的数据进行操作。
3.将数据从GPU内存传送回到CPU内存。
内存管理:
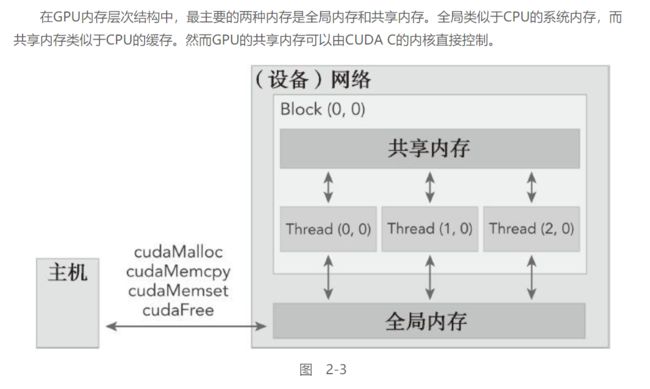
C中有一套对主机内存操作的函数, 相对应的, CUDA提供了一套对设备内存操作的函数:

内存申请:
用于向设备申请一定的线性内存
cudaError_t cudaMalloc<T>(T **devPtr, size_t size);
cudaError_t cudaMalloc(void **devPtr, size_t size);
注意这里申请是以字节为单位
注意:

其与C的malloc有一个地方不同, malloc通过返回void* 指针来确定申请内存的位置
而cudaMalloc返回的是error类型, 所以申请内存的位置就储存在第一个参数中, 这也是为啥第一个参数是void**, 其生成一个指向申请内存的指针, 并吧这个指针赋给void**
内存复制:
用于主机与设备之间的数据传输
cudaError_t cudaMemcpy(void *dst, const void *src, size_t count, enum cudaMemcpyKind kind);
前三个参数基本与C的memcpy相同, 注意这里copy是以字节为单位

第四个参数决定了copy的方向:

注意:
此函数以同步的方式执行, 在操作完成&函数返回前, 主机的应用程序处于阻塞态, 除了内核启动之外的CUDA调用都会返回一个错误的枚举类型cuda Error_t
- 如果GPU内存分配成功,函数返回:
cudaSuccess, 否则返回cudaErrorMemoryAllocation
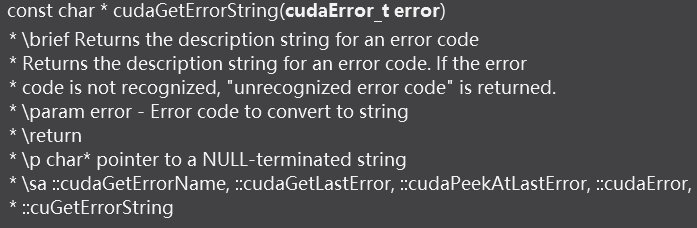
对于枚举类型cuda Error_t, 可以使用此将其转化为可读的错误信息:
内存层次结构:
例程:
一个简单的程序: 计算两个数组的各项和, 并储存在第三个数组中
- 主机中的内存块以
h_开头, 设备中的内存块以d_开头
#include 
线程管理:
CUDA的线程层次抽象是一个两层的线程层次结构,由线程块和线程块网格构成
图中展示的是二维二层结构, CUDA可以组织三维的结构

由一个内核启动所产生的所有线程统称为一个网格。同一网格中的所有线程共享相同的全局内存空间。一个网格由多个线程块构成,一个线程块包含一组线程,同一线程块内的线程协作可以通过以下方式来实现。
-
同步
-
共享内存
不同块内的线程不能协作
线程依靠以下两个坐标变量来区分彼此:
- blockIdx(线程块在线程格内的索引)
- threadIdx (块内线程索引)
这两个坐标变量使用的是有 3个 uint构成的CUDA内置向量, 可以在核函数中直接访问, 并能通过通过x,y,z三个字段来获取:

在执行一个核函数时, CUDA_Runtime会为每个线程分配这俩坐标
基于这俩坐标, 能实现将不同数据分配给不同线程
CUDA中, 网格 & 块的维度可以使用内置变量指定:
-
blockDim(线程块的维度,用每个线程块中的线程数来表示)
-
gridDim(线程格的维度,用每个线程格中的线程数来表示)
其为dim3类型变量, dim3是CUDA的内置类型, 用于指定维度, 同样由3个 uint 组成, 也可以通过xyz访问三个分量:

网格和线程块的维度:
通常,一个线程格会被组织成线程块的二维数组形式,一个线程块会被组织成线程的三维数组形式, 未使用的字段会自动被初始化为1且忽略不计
通常, 在启动核函数前, 在主机端定义dim3变量来确定要开的grid & block , 而后以此传入核函数调用的<<<>>>中, CUDA_Runtime将自动生成能够被所有线程访问的unit3 变量 gridDim & blockDim
例程:
#include 输出:
grid:(2 1 1) # 这里可以看到,为指定的字段被自动初始化为1
block:(3 1 1)
threadIndex:(0 0 0)
blockIndex:(1 0 0)
blockDim:(3 1 1) # blockDim & gridDim在每个设备线程中相同
gridDim:(2 1 1)
threadIndex:(1 0 0)
blockIndex:(1 0 0)
blockDim:(3 1 1)
gridDim:(2 1 1)
threadIndex:(2 0 0)
blockIndex:(1 0 0)
blockDim:(3 1 1)
gridDim:(2 1 1)
threadIndex:(0 0 0)
blockIndex:(0 0 0)
blockDim:(3 1 1)
gridDim:(2 1 1)
threadIndex:(1 0 0)
blockIndex:(0 0 0)
blockDim:(3 1 1)
gridDim:(2 1 1)
threadIndex:(2 0 0)
blockIndex:(0 0 0)
blockDim:(3 1 1)
gridDim:(2 1 1)
从主机端 & 设备端访问网格/块变量:
对于一个给定的数据大小,确定网格和块尺寸的一般步骤为:
-
确定块的大小
-
在已知数据大小和块大小的基础上计算网格维度
要确定块尺寸,通常需要考虑:
-
内核的性能特性
-
GPU资源的限制
由于一个内核启动的网格和块的维数会影响性能,这一结构为程序员优化程序提供了一个额外的途径。
网格和块的维度存在几个限制因素,对于块大小的一个主要限制因素就是可利用的计算资源,如寄存器,共享内存等
后头的几个章节会对上头的内容进行详细介绍
例程:
在数据量不变的情况下, 改变block大小同时修正grid大小:


启动一个CUDA核函数:
之前的例程中, 基本展示了启动CUDA核函数的过程, 其中<<控制线程在GPU上调度运行的模式
由此可以控制:
-
内核中线程的数目
-
内核中使用的线程布局
同一个快中的线程可以相互合作, 不同块内的线程不能协作, 根据此规则可以更好的配置线程的分布以适应要处理的数据
异步:
主机调用核函数后, 控制权立即返回(相当于函数立即返回), 主机 & 设备异步执行 , 所有的核函数都是异步的
这里需要注意, __global__核函数的返回值必须是void
如果需要同步, 则可以使用cudaDeviceSynchronize();代替之前的cudaDeviceReset();
某些API与主机是隐式同步的, 如之前的cudaMemcpy()
编写核函数:
三种核函数修饰符:

__device__和__host_限定符可以一齐使用,这样函数可以同时在主机和设备端进行编译
以下特性适用于所有核函数:
以下限制适用于所有核函数:
-
只能访问设备内存
-
返回类型必须为void
-
不支持可变数量的参数
-
不支持静态变量
-
异步执行
验证核函数:
基本使用两个策略:
- 使用高端的调试工具
- 没有调试工具的情况下, 可以使用
<<<1,1>>>或 由CPU执行的串行/并行代码来验证 核函数结果的正确性
处理错误:
由于CUDA调用是异步的, 有时很难确定问题出在哪
所以可以定义一个宏去调用所有CUDA API, 这是一个较好的办法:
#define CHECK(call) { \
const cudaError_t error = call;\
if (error != cudaSuccess)\
{\
printf("Error: %s:%d\n", __FILE__, __LINE__);\
printf("code: %d, reason: %s\n", error, cudaGetErrorString(error));\
exit(1);\
}\
}
宏函数可以在编译期间直接替换代码, 对程序性能几乎没有影响
注意: 这里使用define定义宏函数时, 换行处要使用\标记, 否则编译器不识别

使用CHECK后可以很好的判断出现了啥问题, 如下头的代码中, 由于矩阵过大导致内存溢出, 之前是没有提示的, 仅仅是CPU计算失败, 而现在可以看到如下输出:
Start calculating.....
Matrix size = 16384 * 32768
Error: cuda_test.cu:146
code: 2, reason: out of memory
从而可以判断出了啥问题
编译 & 执行:
这里主要实现一个GPU的向量加法:
#include 给核函数计时:
用CPU计时器即时:
书里用的是timeval , 这里还是直接使用clock() 较为方便
这里如果需要统计设备的计算时间, 主机需要使用cudaDeviceSynchronize() 来等待GPU计算完成, 相对而言较为耗时
用nvprof工具计时
这里在本地环境中遇到dll缺失的问题, 参考这个博客解决:
https://www.cnblogs.com/aixiaodi/p/13766461.html
老黄的一个CUDA官方分析工具, 还挺好用的, 显示的信息更全面, 并且比CPU计时更加准确, 推荐使用
直接使用CMD或vscode自带的命令行:
nvprof .\cuda_test.exe
输出:

可以看到大量的时间花费在了数据传输上, 设备真正计算的时间其实并不多, 可以根据此特点进行专项优化
实际性能最大化:

组织并行进程:
本部分主要探究不同的线程组织形式对于给定数据集的影响
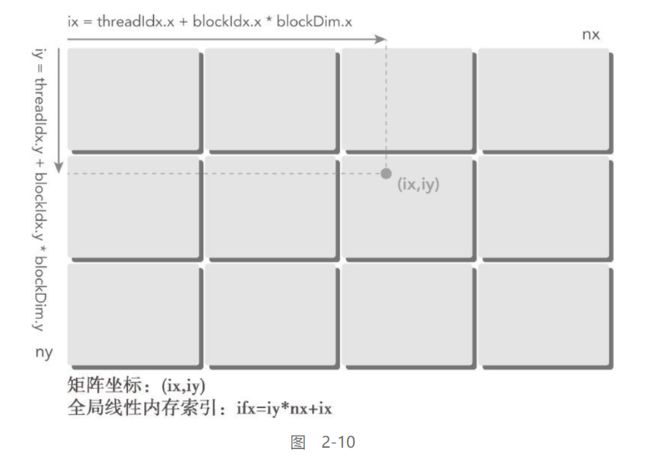
使用块和线程建立矩阵索引:
线程坐标与实际坐标的关系:
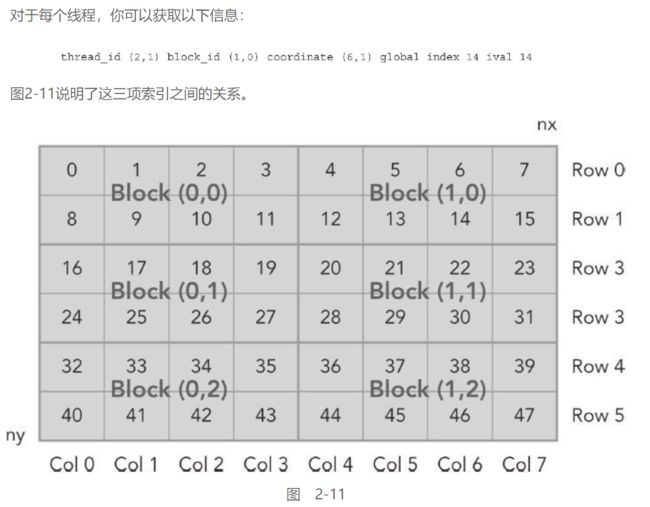


使用二维网络&二维块对矩阵求和:
这里基本按照一维线程的策略对二维线程进行映射
将二维线程当做一维线程进行操作, 分别映射到给定的二维数据集上
#include 输出:
Start calculating.....
Matrix size = 8192 * 16384
GPU计算完成, 耗时54 ms
CPU计算完成, 耗时447 ms
这里不同的线程配置会改变计算速度, 具体到第三章中才会涉及, 现在先知道个大概:
当线程数与CUDA数相同时:
Start calculating.....
Matrix size = 8192 * 16384
GPU计算完成, 耗时75 ms
CPU计算完成, 耗时435 ms
当减小grid扩大block时:
int threadNum = 1280; //CUDA_num=640, 这里开到2倍
//block & grid 均分threadNum
//1280质因数分解: 2*2*2*2*2*2*2*2*5
dim3 block(20, 8, 1);
dim3 grid(4, 2, 1);
Start calculating.....
Matrix size = 8192 * 16384
GPU计算完成, 耗时45 ms
CPU计算完成, 耗时438 ms
并且这里使用vscode 与 VS2017的计算结果上, CPU计算时间也有差异
这里是nvprof的结果:
可以看到同样也是大量的时间花费在了memcpy上


使用一维网络&一维快对矩阵求和:
道理基本上和第一个相同, 只不过变更一下线程索引
==其实线程索引都不需要变更, 直接使用2Dgrid + 2Dblock的线程索引即可
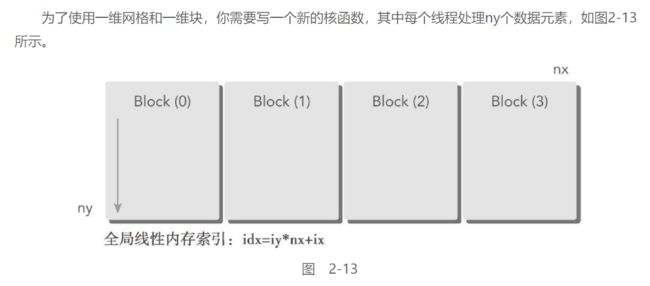
最终的性能与2Dgrid & 2Dblock 基本相同
使用二维网络和一维块对矩阵求和:
同样也是变更一下线程索引:


nvprof结果:

设备管理:
本部分介绍两种查看&管理设备的方式:
-
CUDA运行时API函数
-
NVIDIA系统管理界面(nvidia-smi)命令行实用程序
适用于没有图形界面的服务器&超算 (个人电脑可以使用任务管理器查看)
使用Runtime_API 查询GPU信息:
cudaError_t CUDARTAPI cudaGetDeviceProperties(struct cudaDeviceProp *prop, int device);
使用这个内置函数
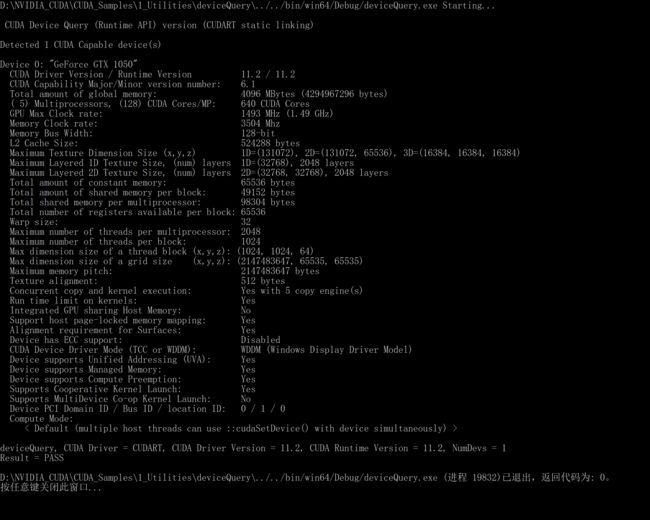
获取到的设备信息将存储在cudaDeviceProp结构体中, 这个结构体有一堆的信息, 其中CUDA给的example中的用于测试CUDA是否成功安装的deviceQuery用的就是这个:
详细的信息可以参照官网:
https://docs.nvidia.com/cuda/cuda-runtime-api/structcudaDeviceProp.html#structcudaDeviceProp
其余的信息, 基本就是分析deviceQuery了
-
驱动 & Runtime 版本:
int driverVersion = 0, runtimeVersion = 0; cudaDriverGetVersion(&driverVersion); cudaRuntimeGetVersion(&runtimeVersion); printf("%d\n%d", driverVersion, runtimeVersion);输出:
11020
11020可以看到他这里并没有小数点, 是用一个整数代替的版本
本机使用的驱动版本为11.2, 所以可知其转化方法:
printf("CUDA Driver Version / Runtime Version %d.%d / %d.%d", driverVersion/1000, (driverVersion%100)/10, runtimeVersion/1000, (runtimeVersion%100)/10 );CUDA Driver Version / Runtime Version 11.2 / 11.2
-
CUDA计算能力:
CUDA设备支持的计算架构版本,即计算能力,该值越大越好
这个通过上头的prop获得:
printf("CUDA Capability Major/Minor version number: %d.%d\n", prop.major, prop.minor);CUDA Capability Major/Minor version number: 6.1
-
显存:
printf("GPU Clock rate: %.0f MHz (%0.2f GHz)\n", prop.clockRate * 1e-3, prop.clockRate * 1e-6); -
GPU频率 & 内存频率:
printf("GPU Clock rate: %.0f MHz (%0.2f GHz)\n", prop.clockRate * 1e-3, prop.clockRate * 1e-6); printf("Memory Clock rate: %.0f MHz\n", prop.memoryClockRate * 1e-3f);
#include 输出:
Starting......
Device 0 : GeForce GTX 1050
CUDA Driver Version / Runtime Version 11.2 / 11.2
CUDA Capability Major/Minor version number: 6.1
Total amount of global memory: 4096.00 MBytes (4294967296 bytes)
GPU Clock rate: 1493 MHz (1.49 GHz)
Memory Clock rate: 3504 MHz
Memory Bus Width: 128-bit
L2 Cache Size: 524288 bytes
Max Texture Dimension Size (x,y,z): 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 8192)Max Layered Texture Size (dim) x layers 1D=(32768) x 2048, 2D=(32768,32768) x 2048
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers availables per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Maximum sizes of each dimension of a block: 1024 x 1024 x 64
Maximum sizes of each dimension of a grid: 2147483647 x 65535 x 65535
Maximum memory pitch: 2147483647 bytes
其余的直接分析deviceQuery:
| 序号 | 名称 | 值 | 解释 |
|---|---|---|---|
| 1 | Detected 1 CUDA Capable device(s) | 1 | 检测到1个可用的NVIDIA显卡设备 |
| 2 | Device 0: “GeForce 930M” | GeForce 930M | 当前显卡型号为" GeForce 930M " |
| 3 | CUDA Driver Version / Runtime Version | 7.5/7.5 | CUDA驱动版本 |
| 4 | CUDA Capability Major/Minor version number | 5.0 | CUDA设备支持的计算架构版本,即计算能力,该值越大越好 |
| 5 | Total amount of global memory | 4096Mbytes | Global memory全局存储器的大小。使用CUDA RUNTIME API调用函数cudaMalloc后,会消耗GPU设备上的存储空间,合理分配和释放空间避免程序出现crash |
| 6 | (3) Multiprocessors, (128) CUDA Cores/MP | 384 CUDA Cores | 3个流多处理器(即SM),每个多处理器中包含128个流处理器,共384个CUDA核 |
| 7 | GPU Max Clock rate | 941 MHz | GPU最大频率 |
| 8 | Memory Clock rate | 900 MHz | 显存的频率 |
| 9 | Memory Bus Width | 64-bit | 总线带宽 |
| 10 | L2 Cache Size | 1048576 bytes | 二级缓存大小 |
| 11 | Maximum Texture Dimension Size (x, y, z) | 1D=(65535)2D=(65535, 65535)3D=(4096,4096,4096) | |
| 12 | Maximum Layered 1D Texture Size, (num) layers | 1D=(16384),2048 layers | |
| 13 | Maximum Layered 2D Texture Size, (num) layers | 2D=(16384,16384), 2048 layers | |
| 14 | Total amount of constant memory | 65535 bytes | 常量存储器的大小 |
| 15 | Total amount of shared memory per block | 49152 bytes | 共享存储器的大小,共享存储器速度比全局存储器快;多处理器上的所有线程块可以同时共享这些存储器 |
| 16 | Total number of registers available per block | 65535 | |
| 17 | Warp Size | 32 | Warp,线程束,是SM运行的最基本单位,一个线程束含有32个线程 |
| 18 | Maximum number of threads per multiprocessor | 2048 | 一个SM中最多有2048个线程,即一个SM中可以有2048/32=64个线程束Warp |
| 19 | Maximum number of threads per block | 1024 | 一个线程块最多可用的线程数目 |
| 20 | Max dimension size of a thread block (x, y, z) | (1024,1024,64) | ThreadIdx.x<=1024,ThreadIdx.y<=1024,ThreadIdx.z<=64Block内三维中各维度的最大值 |
| 21 | Max dimension size of a grid size (x, y, z) | (2147483647,65535,65535) | Grid内三维中各维度的最大值 |
| 22 | Maximum memory Pitch | 2147483647 bytes | 显存访问时对齐时的pitch的最大值 |
| 23 | Texture alignment | 512 bytes | 纹理单元访问时对其参数的最大值 |
| 24 | Concurrent copy and kernel execution | Yes with 1 copy engine(s) | |
| 25 | Run time limit on kernels | Yes | |
| 26 | Integrated GPU sharing Host Memory | No | |
| 27 | Support host page-locked memory mapping | Yes | |
| 28 | Alignment requirement for Surfaces | Yes | |
| 29 | Device has ECC support | Disabled | |
| 30 | 其他 |
GPU性能的粗略比较:
直接使用上头cudaGetDeviceProperties获取到的multiProcessorCount
这个获取到的是显卡的流式多处理器的数量, 间接反映的CUDA数量, 反正就是越多越好
本地环境使用的GTX1050仅开启了5个MP核心
使用nvidia-smi 查询GPU信息:
本地环境中, nvidia-smi路径没有添加到系统path中, 所以只能使用CMD进入指定目录运行:

在运行时设置设备:
使用环境变量CUDA_VISIBLE_DEVICES 即可在运行时指定所选的GPU且无需更改应用程序
参考博客:
https://blog.csdn.net/lscelory/article/details/83579062
由于本地环境中仅有一块具有CUDA功能的显卡, 所以无法对此进行测试
临时设置:
Linux: export CUDA_VISIBLE_DEVICES=1
windows: set CUDA_VISIBLE_DEVICES=1
永久设置:
linux:
在~/.bashrc 的最后加上export CUDA_VISIBLE_DEVICES=1,然后source ~/.bashrc
windows:
打开我的电脑环境变量设置的地方,直接添加就行了。