读书笔记 - CUDA编程指南5.0 + 练习编译运行 01
文章目录
- 1. 导论
- 2. 编程模型
-
-
- 1. 内核
- 2. 线程层次
- 3. 存储器层次
- 3. 异构编程
-
- 快速入门例子
-
-
- vulkanImageCUDA
- 解决
-
- 参考
前言:
会根据CUDA编程指南一点点更新,欢迎讨论。
1. 导论
图形处理的需求,推动可编程图形处理器(GPU)向着高并行度和多线程演化。
从图形处理走向通用并行计算。
GPU和CPU浮点计算能力的差异: GPU并行度高,晶体管更多用于数据处理而非缓存和流控。
数据并行处理:将数据映射到并行处理的线程上,并进行加速。
CUDA:一种通用并行计算架构
CUDA核心的三个重点抽象(能提供犀利的的数据、任务并行):线程组层次、共享存储器和栅栏同步
2. 编程模型
1. 内核
CUDA通过允许程序员定义称为内核的C函数扩展了C,内核调用时会被N个CUDA线程执行N次(每个线程一次)。
- 内核使用
__global__声明符定义 - 使用
<<< >>>指定执行某一指定内核的线程数(参数可以是
整形或者dim3类型) - 每个执行内核的线程拥有(块内)独一无二的线程ID(
threadIdx)
2. 线程层次
threadIdx是一个有三个分量的向量(1d,2d,3d)
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i]+B[i];
}
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j]+B[i][j];
}
int main()
{
...
//Kernel invocation with N threads
VecAdd<<<1,N>>>(A,B,C)
...
// Kernel invocation with one block of N*N*1 threads
int numBlocks = 1
dim3 threadsPerBlock(N, N);
MatAdd <<<numBlocks,threadsPerBlock>>>(A,B,C)
}
以上为两段代码,分别是一维向量和二维矩阵相加的例子,在单一块内执行。
一个内核总的线程数等于每个块内线程X线程块数
由于块内的所有线程必须存在于同一个处理器核心中且共享该核心有限的 存储器资源,因此,一个块内的线程数目是有限的。在目前的GPU上,一个线程块可以包含多达1024个线程。
然而,一个内核可被多个同样大小的线程块执行,所以总的线程数等于每 个块内的线程数乘以线程块数。
线程块被组织成一维、二维或三维的线程网格,如图2.1所示。一个网格内 的线程块数往往由被处理的数据量而不是系统的处理器数决定,前者往往远超后者。
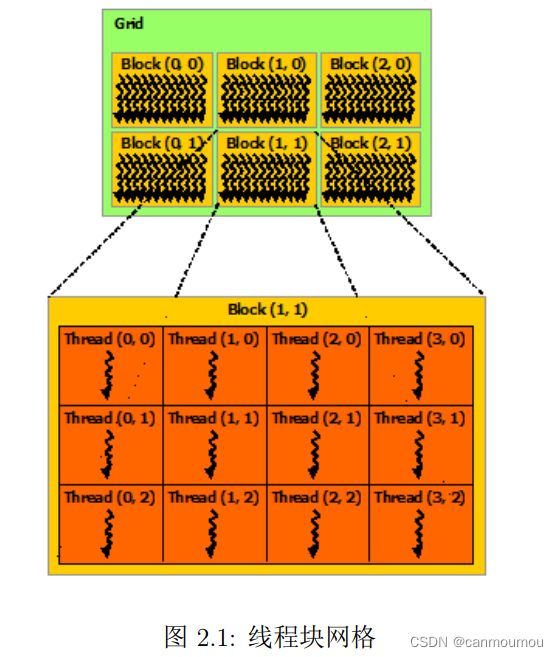
处理多个块的 MatAdd例子:
(只修改了 int i和int j的赋值)
// Kernel definition
global void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x ∗ blockDim.x + threadIdx.x;
int j = blockIdx.y ∗ blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i ][ j ] = A[i][ j ] + B[i][ j ];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
线程索引与线程ID直接相关:
对于一维的块,它们相同;对于二维长 度为(Dx,Dy)的块,线程索引为(x,y)的线程ID是(x+yDx);对于三维长度为(Dx,Dy,Dz)的块,索引为(x,y,z)的线程ID为(x+yDx+zDxDy)
3. 存储器层次
全局存储器:所有线程可访问(生命周期和块相同)
只读存储器: 常量和纹理存储器空间。(按其用途优化,可被所有线程访问)
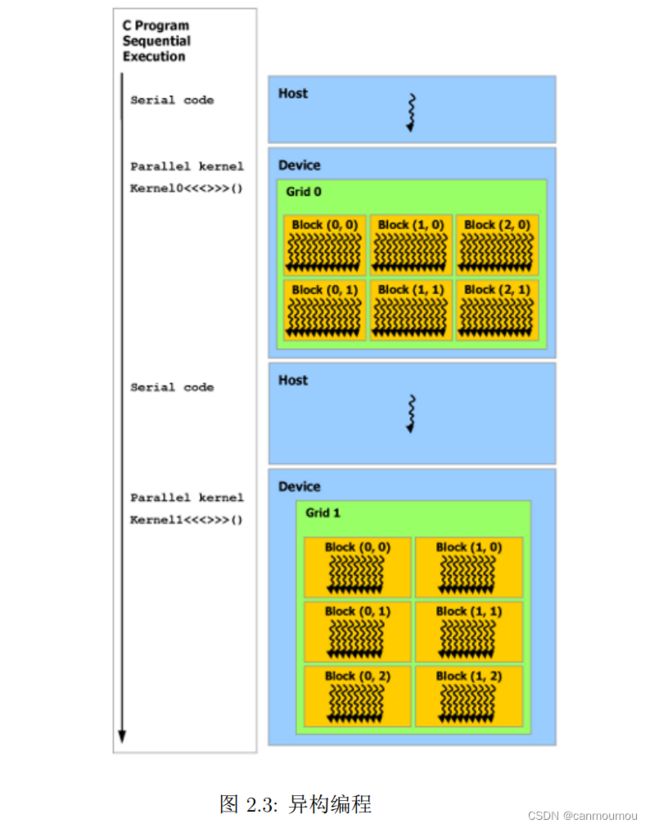
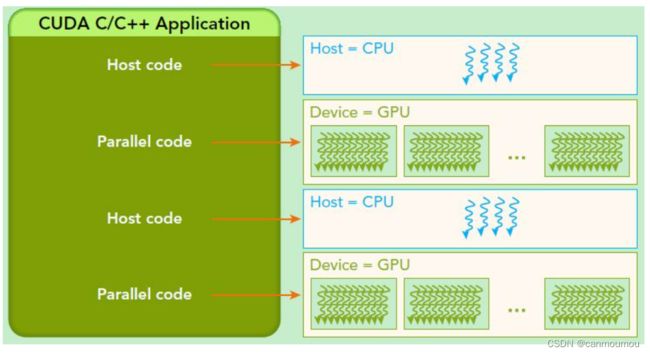
3. 异构编程
为什么说是异构编程
- 因为CUD假设每个线程在独立的物理设备上执行,设备是主机的协处理器。
- 假设主机和设备各自维护独立的DRAM存储器空间。
因此实现了主机和设备的异构。
主机:执行C程序(串行代码部分)
GPU:执行内核(并行代码部分)
程序通过 调用CUDA 运行时,来管理对内核可见的全局、常量和纹理存储器空间。这包括设备存储器分配和释放,也包括在主机和设备间的数据传输。
快速入门例子
- windows 安装cuda
- linux安装cuda
因为之前已经在服务器上安装过。因此安装方面不做赘述,cuda的安装一般也不容易出错。
下载测试例子(安装cuda时也可选,但我单独下载了):
git clone https://github.com/NVIDIA/cuda-samples.git
阅读README可以看到如何编译,windoes版本可以直接打开sln文件。
以下是Linux的编译:
make
离开了一会儿回来发现在第五个例子终止了:
compilation terminated.
make[1]: *** [Makefile:383: vulkanImageCUDA.o] Error 255
make[1]: Leaving directory '/data1/jilan.li/github/cuda-samples/Samples/5_Domain_Specific/vulkanImageCUDA'
make: *** [Makefile:45: Samples/5_Domain_Specific/vulkanImageCUDA/Makefile.ph_build] Error 2
往上方排查,发现glfw3缺失:
Package glfw3 was not found in the pkg-config search path.
Perhaps you should add the directory containing `glfw3.pc'
to the PKG_CONFIG_PATH environment variable
No package 'glfw3' found
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
vulkanImageCUDA.cu:37:10: fatal error: GLFW/glfw3.h: No such file or directory
37 | #include <GLFW/glfw3.h>
| ^~~~~~~~~~~~~~
用 apt-cache 搜索了一下下载,再make。注意要下载-dev的包。
sudo apt-cache search glfw3
sudo apt-get install libglfw3-dev
再make一次:
/usr/bin/ld: vulkanImageCUDA.o: in function `vulkanImageCUDA::cudaVkSemaphoreSignal(CUexternalSemaphore_st*&)':
tmpxft_0007cb3d_00000000-6_vulkanImageCUDA.compute_86.cudafe1.cpp:(.text._ZN15vulkanImageCUDA21cudaVkSemaphoreSignalERP22CUexternalSemaphore_st[_ZN15vulkanImageCUDA21cudaVkSemaphoreSignalERP22CUexternalSemaphore_st]+0x7f): undefined reference to `cudaSignalExternalSemaphoresAsync_v2'
/usr/bin/ld: vulkanImageCUDA.o: in function `vulkanImageCUDA::cudaVkSemaphoreWait(CUexternalSemaphore_st*&)':
tmpxft_0007cb3d_00000000-6_vulkanImageCUDA.compute_86.cudafe1.cpp:(.text._ZN15vulkanImageCUDA19cudaVkSemaphoreWaitERP22CUexternalSemaphore_st[_ZN15vulkanImageCUDA19cudaVkSemaphoreWaitERP22CUexternalSemaphore_st]+0x7f): undefined reference to `cudaWaitExternalSemaphoresAsync_v2'
collect2: error: ld returned 1 exit status
make[1]: *** [Makefile:386: vulkanImageCUDA] Error 1
make[1]: Leaving directory '/data1/jilan.li/github/cuda-samples/Samples/5_Domain_Specific/vulkanImageCUDA'
make: *** [Makefile:45: Samples/5_Domain_Specific/vulkanImageCUDA/Makefile.ph_build] Error 2
我以为是cuda版本不一致,但我运行/usr/local/cuda-11.4/sample下的例子,也有同样的错误。
所以我再看第五个例子中关于出错文件的README,其中写到需要Vulkan SDK和GLFW3库。
vulkanImageCUDA
This sample demonstrates Vulkan Image - CUDA Interop. CUDA imports the Vulkan image buffer,
performs box filtering over it, and synchronizes with Vulkan through
vulkan semaphores imported by CUDA. This sample depends on Vulkan SDK,
GLFW3 libraries, for building this sample please refer to
“Build_instructions.txt” provided in this sample’s directory
解决
- 下载官方压缩包Vulkan SDK:
- 加入apt list 命令行下载
sudo wget -qO /etc/apt/sources.list.d/lunarg-vulkan-focal.list http://packages.lunarg.com/vulkan/lunarg-vulkan-focal.list
sudo apt install vulkan-sdk
参考
CUDA编程入门极简教程